




人工智能 (AI) 是一种强大的工具,它可以增强您的应用程序,提供更好的个性化定制体验,满足客户的独特需求,同时提高内部运营的质量和效率。虽然简单的演示应用程序通常是快速掌握新技术的简单方法,但“现实世界”要复杂得多,您希望看到更多使用 AI 的强大、现实启发式场景的示例。为了帮助回答不仅仅是“什么是 AI?”这个问题,而且还回答“如何在我的应用程序中使用 AI?”,我们创建了一个应用程序来说明如何将 AI 融入典型的业务线应用程序中。
推出 eShop“AI 支持”版本
人工智能增强型eShopSupport 应用程序是一个支持网站,客户可使用它来查询产品。eShop 员工有一个工作流程来跟踪这些查询、与客户交谈以及对这些查询进行分类并最终关闭这些查询。通过各种功能,此示例超越了流行的“聊天机器人”场景,展示了人工智能可以提高开发人员工作效率的几种方式,同时提高您能够提供的个性化客户支持水平。
此演示说明了如何使用 AI 来增强现有业务线应用程序中的各种功能,而不仅仅是“绿地”或新应用程序。例如,为什么不使用语义搜索来增强您的搜索功能,即使用户没有输入准确的短语或使用正确的拼写,它也可以找到内容?您是否需要向您的应用程序添加新语言?大型语言模型 (LLM) 能够处理多种语言的输入和输出。您是否需要筛选大量数据来寻找趋势?使用 LLM 来帮助汇总您的数据。如果要进入管道,请考虑自动进行分类和情绪分析。
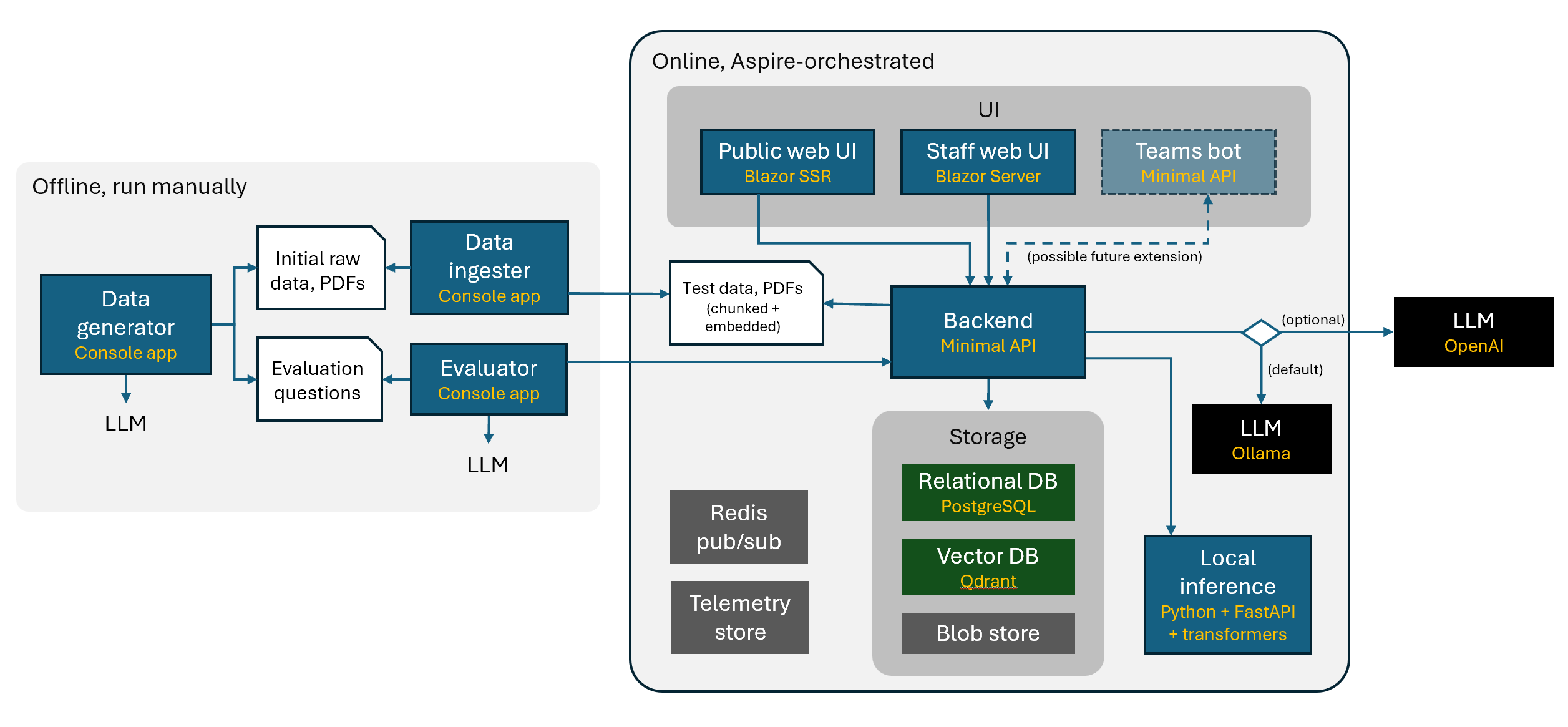
该演示还使用.NET Aspire来利用其跨服务、数据存储、容器甚至技术进行编排的能力。Python 是数据科学领域的一种流行语言,但这并不意味着您必须将所有内容都切换到 Python,甚至将 Python 转换为 C#。此示例展示了一种互操作性方法,并使用 .NET Aspire 托管 Python 微服务。
特征
样本中与 AI 相关的功能包括:
| 特征 | 描述 | 代码实现 |
|---|---|---|
| 语义搜索 | 无需确切的短语或描述,甚至拼写不正确即可查找内容 | src / 后端 / 服务 / SemanticSeach |
| 总结 | 避免“陷入困境”而重新阅读历史以获取背景信息,只需关注相关部分 | src / 后端 / 服务 / TicketSummarizer |
| 分类 | 无需人工干预即可实现工作流程自动化 | src / PythonInference / 路由器 / 分类器 |
| 情绪评分 | 帮助对反馈和讨论进行分类和优先排序,以了解产品或活动的接受程度 | src / 后端 / 服务 / TicketSummarizer |
| 内部问答聊天机器人 | 帮助员工回答技术和业务相关的问题,并提供引文作为证明,并自动生成答复草稿 | src / ServiceDefaults / 客户端 / 后端 / StaffBackendClient |
| 测试数据生成 | 根据您提供的规则生成大量数据 | 种子数据/数据生成器/生成器 |
| 评估工具 | 根据准确性、速度和成本客观地对机器人/代理的行为进行评分,并随着时间的推移系统地改进它们 | src / 评估器 / 程序 |
| E2E 测试 | 当产品本身不确定时提供确定性测试门的示例(实验)方法 | 测试/E2E测试 |
.NET Aspire 用于管理 LLM 和数据库等资源。Microsoft.Extensions.AI是一组用于智能应用的通用构建块和原语。开发人员可以使用一组标准 API 来执行常见任务,而库和框架提供商可以在这些通用的标准接口和类的基础上进行构建,以在整个 .NET 生态系统中提供一致的体验。正如Semantic Kernel 团队在其博客中宣布的那样,Microsoft.Extensions.AI 版本不会取代 Semantic Kernel。相反,它提供了一组抽象、API 和原语构建块,这些将由 Semantic Kernel 实现,以及语义分块等附加功能。
本地克隆和运行的说明
与典型演示相比,智能应用示例通常需要更多资源和强大的环境才能运行。您可以阅读运行示例的最低要求,并使用最新的分步说明在eShopSupport 存储库上本地克隆和运行示例。
代码之旅
应用程序背后的“大脑”是用于生成响应的大型语言模型 (LLM)。虽然将 LLM 视为聊天或助手是一种普遍趋势,但此示例演示了如何使用它们来增强业务线应用程序中的各种功能。LLM 用于生成摘要、提供问题的答案、建议回复客户查询,甚至生成测试数据。使用 Microsoft.Extensions.AI 提供的标准原语,您可以使用相同的代码与 LLM 交互,无论它是Ollama托管的本地模型还是云中的Azure OpenAI 服务资源。
选择您的型号
现在您知道可以更换模型,让我们看一下执行此操作的代码。以下代码使用Microsoft.Extensions.AI抽象与客户端交互,本地和远程模型之间的唯一区别在于配置方式。您配置的服务和模型将传递给依赖项注入,并使用 Microsoft.Extensions.AI 提供的标准接口进行注册。使用此功能,您可以轻松地使用 Ollama 等工具从本地模型切换到云托管的 OpenAI 模型。
Program.cs在项目中打开AppHost以查看模型的配置方式并将其注入到应用程序中。例如,要使用 Ollama,您可以像这样配置服务:
var chatCompletion = builder.AddOllama("chatcompletion").WithDataVolume();测试完成,准备部署了吗?没问题。在appSettings.json配置中设置 OpenAI 密钥,然后将调用更改为:
var chatCompletion = builder.AddConnectionString("chatcompletion");请注意,尽管连接方式不同,但两个实例中的服务名称相同(“chatcompletion”)。现在,无论您使用哪种模型,代码都是相同的:
var client = services.GetRequiredService<IChatClient>();
var response = await ChatClient.CompleteAsync(
prompt,
new ChatOptions ());该类ChatOptions允许您指定参数,例如要生成的最大令牌数、温度或“创造力”等。它提供了现成的合理默认值,但您可以自定义它以满足您的需求。
生成测试数据
该seeddata文件夹包含DataGenerator用于创建测试数据的文件夹。各种生成器都位于该Generators文件夹中。提示符如下所示:
- 有多少条记录
- 字段创建规则和业务逻辑
- 数据的架构(本例中提供了一个 JSON 示例)
这种构造提示的方法不仅对数据生成有用。如果您希望以众所周知的结构或格式接收响应,以便对其进行解析,则可以随时使用此模式。这是自动化某些工作流程和任务的关键。
以下是生成类别的示例提示:
Generate 100 product category names for an online retailer of high-tech outdoor adventure goods and related clothing/electronics/etc.
Each category name is a single descriptive term, so it does not use the word 'and'.
Category names should be interesting and novel, e.g., "Mountain Unicycles", "AI Boots", or "High-volume Water Filtration Plants", not simply "Tents".
This retailer sells relatively technical products.
Each category has a list of up to 8 brand names that make products in that category.
All brand names are purely fictional.
Brand names are usually multiple words with spaces and/or special characters, e.g. "Orange Gear", "Aqua Tech US", "Livewell", "E & K", "JAXⓇ".
Many brand names are used in multiple categories. Some categories have only 2 brands.
The response should be a JSON object of the form:
{
"categories"": [
{
"name":"Tents",
"brands": [
"Rosewood",
"Summit Kings"]
}]
}然后可以轻松地将响应反序列化并插入到数据库中。
评估模型
LLM 模型不是确定性的,因此使用完全相同的输入可能会产生不同的结果。这带来了一些挑战。您需要一种方法来测试您的提示是否生成了预期的响应,以便您可以通过评估响应的质量来迭代改进提示。您还需要一个可以自动化的基线,并在由于应用程序更改而出现回归时对其进行分类。
代码提供了“评估”的示例,评估是一组客观问题,用于询问模型并确定其是否合理。分数取决于模型的答案与预期答案的接近程度。满分必须包括手册提供的所有事实,并且没有错误、不相关的陈述或矛盾。问题由基于产品手册的模型生成,并将答案与预期答案进行比较。
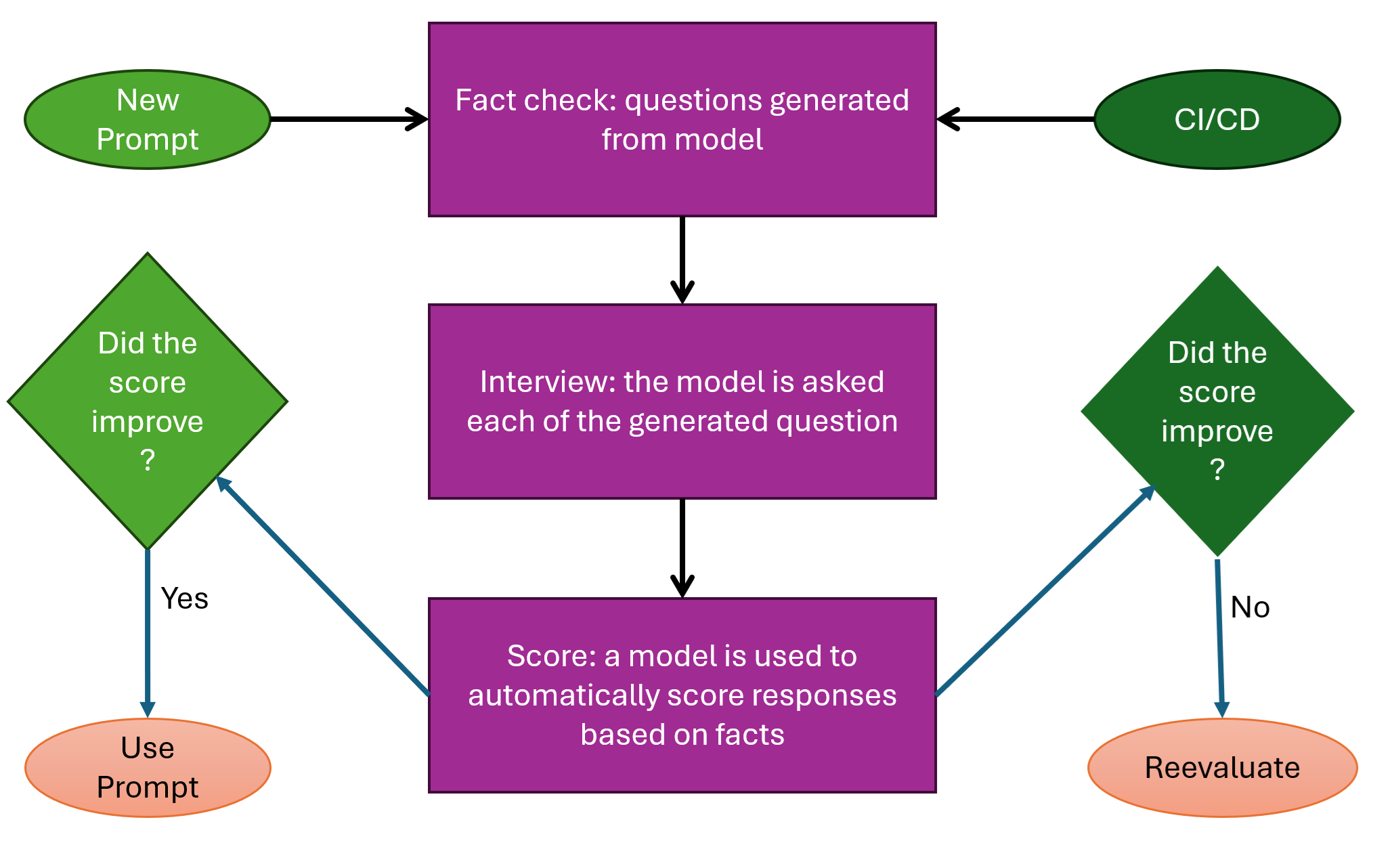
这种方法可以帮助您和您的团队确信模型的更新或提示的调整将实现预期的结果。
总结和分类信息
LLM 的一项功能可以节省大量时间并提高效率和生产力,那就是能够总结和分类信息。想象一下,您是一名客户支持代表,每天都会收到数百个请求。您需要对每个请求进行分类,以便能够优先处理不满意的客户和关键请求。LLM 可以通过总结和分类请求来提供帮助。它还可以提供情绪分数。情绪、总结和分类都提供了正确的背景信息,让您“一目了然”,从而适当地确定工单的优先级。您可以随时阅读原始工单以进行澄清或仔细检查 LLM 的工作。
最棒的是:所有这些都可以在一次 LLM 通话中实现。以下是提示总结、分类和分析票证情绪的示例:
You are part of a customer support ticketing system.
Your job is to write brief summaries of customer support interactions.
This is to help support agents understand the context quickly so they can help the customer efficiently.
Here are details of a support ticket.
Product: "Television Set"
Brand: "Contoso"
The message log so far is:
(customer feedback goes here, such as: "my TV won't turn on" or "it's stuck on a channel that plays nothing but 80s sitcoms")
Write these summaries:
1. A longer summary that is up to 30 words long, condensing as much distinctive information as possible. Do NOT repeat the customer or product name, since this is known anyway. Try to include what SPECIFIC questions/info were given, not just stating in general that questions/info were given. Always cite specifics of the questions or answers. For example, if there is pending question, summarize it in a few words. FOCUS ON THE CURRENT STATUS AND WHAT KIND OF RESPONSE (IF ANY) WOULD BE MOST USEFUL FROM THE NEXT SUPPORT AGENT.
2. A shorter summary that is up to 8 words long. This functions as a title for the ticket, so the goal is to distinguish what's unique about this ticket.
3. A 10-word summary of the latest thing the CUSTOMER has said, ignoring any agent messages. Then, based ONLY on that summary, score the customer's satisfaction using one of the following phrases ranked from worst to best: (insert list of terms like "angry" to "ecstatic" here) Pay particular attention to the TONE of the customer's messages, as we are most interested in their emotional state.
Both summaries will only be seen by customer support agents.
Respond as JSON in the following form:
{
"LongSummary": "string",
"ShortSummary": "string",
"TenWordsSummarizingOnlyWhatCustomerSaid": "string",
"CustomerSatisfaction": "string"
}
如您所见,结果再次是一个可解析的 JSON 对象,可用于更新数据库中的票证。
语义搜索
语义搜索使用语义排名来提供更相关的结果。当您拥有大量项目数据库,而用户可能不知道他们正在寻找的确切单词或短语时,这尤其有用。LLM 可以根据搜索词的含义提供更相关的搜索结果。搜索的工作原理是将搜索文本转换为“嵌入”,即表示文本含义的数字向量。它可以根据含义的对齐方式提供短语之间的“距离”。例如,考虑一个产品目录,其中包含:
- 显微镜——强大的 200 倍放大倍率揭示世界上最微小的奇迹
- 望远镜——焦距 2,350 毫米足以观测遥远的星系
- 手套——别让你的手太冷
在传统搜索中,如果客户输入“micrscope”(故意拼写错误),则搜索不会返回任何结果,因为没有完全匹配。使用语义搜索,搜索会认为此字符串与显微镜条目最接近。同样,如果用户搜索“skiing”,它会选择“gloves”条目作为更接近的匹配项,而不是“microscope”或“telescope”的条目,即使拼写没有相似之处。
该 repo 包含几个类,它们在Services文件夹中提供语义搜索的实现。
关于端到端测试的说明
为了完整性,我们引入了一种端到端测试方法。eShop 支持中的示例完全是实验性的,不应被视为生产指南。对智能应用进行自动化测试面临许多挑战,从资源限制和成本控制到模型不确定的事实。提供的示例是一种控制模型更改并确保应用的行为与预期结果一致的方法。
结论
智能应用的时代已经到来,.NET 提供了将 AI 驱动的功能集成到项目中所需的工具。持续评估 AI 的负责任使用至关重要。例如,不要假设 AI 总是正确的。这就是为什么应用程序的设计使得实际客户响应不是自动的。会生成建议的响应,但仍需人工审核和发送。AI 加速了这一过程,但人类仍在掌控之中。
类似地,自动化支持工单的工作流程会对某个类别做出“最佳猜测”,但如果猜测不正确,人类可以随时推翻这一猜测。该应用还会量化响应的质量,以便您可以系统地改进响应。这些只是 AI 如何与人类合作(而不是取代人类)以增强您的应用体验并提高生产力的几个例子。
文章翻译于作者 | Jeremy Likness Principal Program Manager - .NET Web Frameworks

















 73
73





 到【灌水乐园】发言
到【灌水乐园】发言







