




 本文介绍了一种爬取豆瓣热门电影数据的方法,包括如何分析目标URL及其参数、使用正则表达式抓取数据,以及如何下载电影封面图片并保存到本地。
本文介绍了一种爬取豆瓣热门电影数据的方法,包括如何分析目标URL及其参数、使用正则表达式抓取数据,以及如何下载电影封面图片并保存到本地。
本文重点总结
1、分析并确定待爬取url及关键参数(更多详情可参考上篇注释)
2、正则表达式的使用
3、图片下载
上代码
import requests
import re
import io, sys, os
import urllib.request
# 注意修改参数page_limit限定爬取个数,本文设置为100
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=100&page_start=0'
# 防止反爬虫
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Referer':'https://movie.douban.com/explore',
}
# 上述url请求的响应内容
html_doc = requests.get(url=url, headers=headers).content.decode('utf-8') # 获取字符串格式的html_doc
# 下面一行解决编码问题:UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position 0: illegal multibyte sequence
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
# print(html_doc)
# 使用正则表达式收割图片的url
# 通过请求url的源码观察得知,电影名称为title后面的部分
pat_name = re.compile(r'"title":"(.*?)"')
name_lst = pat_name.findall(html_doc)
pat_rate = re.compile(r'"rate":"(.*?)"')
rate_lst = pat_rate.findall(html_doc)
# 获取电影封面图片地址
# pat_cover = re.compile(r'"cover":"(https://.*.jpg)"')
# above one works same as below, but below is zhuangbility version
pat_cover = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
cover_lst = pat_cover.findall(html_doc)
# 下载图片
count = 1 # 计数正在下载的图片序号
# 设置图片存储路径,如果目录不存在则创建
path = './top100_movies'
if not os.path.exists(path):
os.mkdir(path)
for url in cover_lst:
# 去掉url中多余的右斜线\\,否则请求报错
url = url.replace('\\', '')
# 命名文件
file_name = '%s-%s分.jpg' % (name_lst[count-1], rate_lst[count-1])
print('Downloading %s movie cover...' % count)
urllib.request.urlretrieve(url, os.path.join(path, file_name))
count += 1
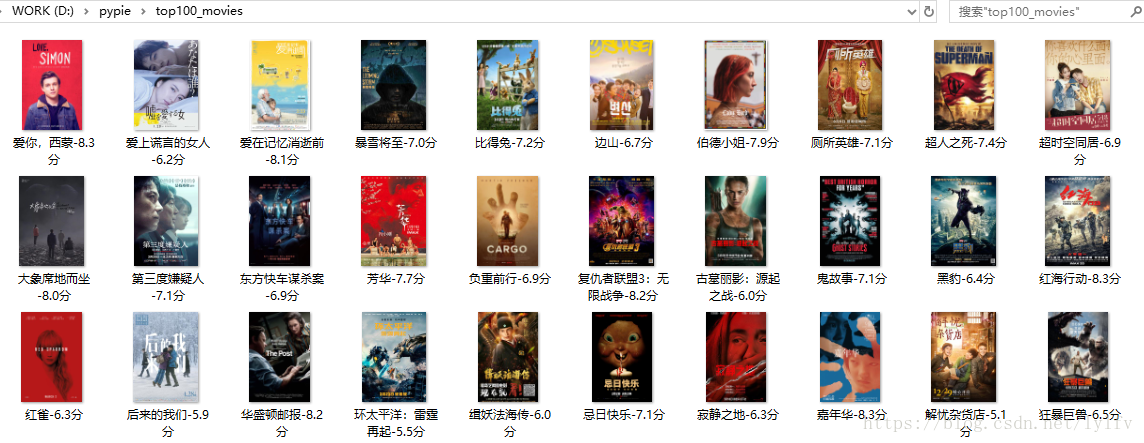
代码运行截图如下

















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









