




 本文详细介绍了在虚拟机环境中搭建Hadoop集群的过程,包括环境准备、网络配置、SSH无密码验证配置、JDK安装、Hadoop集群安装及验证等关键步骤。
本文详细介绍了在虚拟机环境中搭建Hadoop集群的过程,包括环境准备、网络配置、SSH无密码验证配置、JDK安装、Hadoop集群安装及验证等关键步骤。
1Hadoop集群部署介绍
1.1 Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
1.2 Spark介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
1.3 实验环境
Windows 10
Vmware Workstation
Ubuntu16.04.3
Hadoop-2.6.0
Jdk1.8.0_121
Scala-2.11.8
Spark-2.3.4-bin-Hadoop-2.6
SSH
我的环境是在虚拟机中配置的,Hadoop集群中包括3个节点:1个Master,2个Salve,节点之间局域网连接,可以相互ping通,节点IP地址分布如下:
| 虚拟机系统 | 机器名称 | IP地址 |
| Ubuntu16.04 | master | 192.168.94.135 |
| Ubuntu16.04 | slave1 | 192.168.94.136 |
| Ubuntu16.04 | slave2 | 192.168.94.137 |
Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;2个Salve机器配置DataNode 和TaskTracker的角色,负责分布式数据存储以及任务的执行。其实应该还应该有1个Master机器,用来作为备用,以防止Master服务器宕机,还有一个备用马上启用。后续经验积累一定阶段后补上一台备用Master机器(可通过配置文件修改备用机器数)。
注意:由于hadoop要求所有机器上hadoop的部署目录结构要求相同(因为在启动时按与主节点相同的目录启动其它任务节点),并且都有一个相同的用户名账户。参考各种文档上说的是所有机器都建立一个hadoop用户,使用这个账户来实现无密码认证。这里为了方便,分别在三台机器上都重新建立一个hadoop用户。
2 网络配置
Hadoop集群要按上所示的参数进行配置。
注意:我的虚拟机都采用NAT方式连接网络,IP地址是自动分配的,所以这里就使用自动分配的IP地址而未特地修改为某些IP地址。
1)修改当前机器名称 sudo vim /etc/hostname
在Ubuntu下修改机器名称,修改文件/etc/hostname里的值即可,修改成功后用hostname命令查看当前主机名是否设置成功。
2)配置hosts文件 sudo vim /etc/hosts
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名对应的IP地址。
在进行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的"/etc/hosts"文件中都要添加如下内容:
192.168.94.135 master
192.168.94.136 slave1
192.168.94.137 slave2
命令:vim /etc/hosts,添加结果如下:
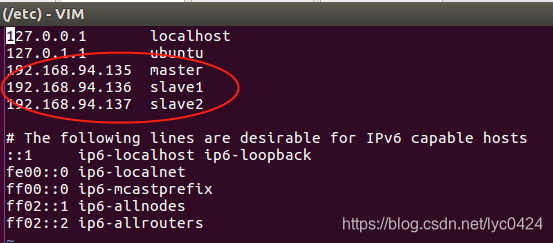
现在对slave机器进行ping通测试,看是否能测试成功。

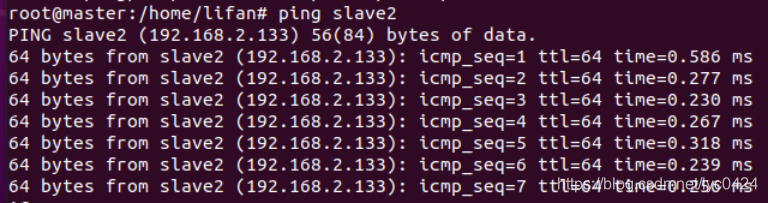
从上图中我们已经能用主机名进行ping通了,说明我们刚才添加的内容,在局域网内能进行DNS解析了,那么现在剩下的事儿就是在其余的Slave机器上进行相同的配置。然后进行测试。
3 SSH无密码验证配置
(前提:安装了openssh-server,若没有则用命令安装sudo apt-get install openssh-server)
cd
ssh-copy-id -i /home/ubuntu/.ssh/id_rsa.pub slave1
连续敲击回车最后输入slave1密码完成master和slave1的免密钥登录配置
3.1 Master机器上设置无密码登录master机器
让 Master 节点需能无密码 SSH 本机(自身免密),在 Master 节点上执行:
使用cd .ssh进入 .ssh这个隐藏文件夹;
再创建一个文件authorized_keys,使用命令touch authorized_keys;
然后使用cat id_rsa.pub > authorized_keys 即可;
最后使用 chmod 600 authorized_keys修改权限就完成了。
4 JDK安装
sudo tar -zxvf jdk-8u121-linux-x64.tar.gz -C ~/install
4.1 配置环境变量
添加以下内容并保存(以下内容中的ubuntu为用户名,根据实际情况修改):
export JAVA_HOME=/home/ubuntu/install/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
scp -r ~/install/jdk1.8.0_121 ubuntu@slave1:~/install/jdk1.8.0_121
sudo scp /etc/profile ubuntu@slave1:/etc
5 Hadoop集群安装
先在master上安装和配置,随后发给slave节点。
5.1 安装hadoop
在home文件夹下创建install文件夹,下载Hadoop_2.6.0.tar.gz文件并复制到该文件夹下。
1)解压hadoop_2.6.0.tar.gz文件:
cd /home/install/
tar -zxvf hadoop-2.6.0.tar.gz -C ~/install
解压后会自动创建hadoop-2.6.0,这个文件夹就是hadoop的安装文件夹。
2)添加Hadoop路径:vim /etc/profile(在slave上也需要同样的的添加路径操作)
sudo vim /etc/profile
export HADOOP_HOME=/home/ubuntu/install/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.2 配置Hadoop环境变量
cd ~/workspace/hadoop-2.6.0/etc/hadoop进入hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml
5.2.1 在hadoop-env.sh中配置JAVA_HOME
添加以下内容
export JAVA_HOME=/home/ubuntu/install/jdk1.8.0_121

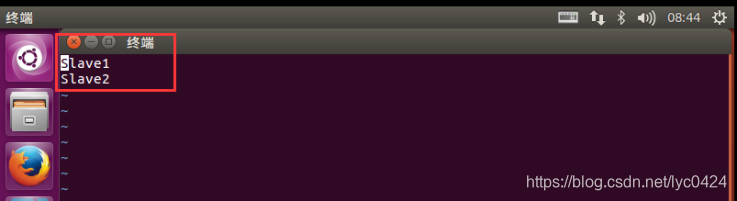
5.2.2 在slaves中配置slave节点的ip或者host
slave1
slave2
命令:vim slaves
#master同样
vim master
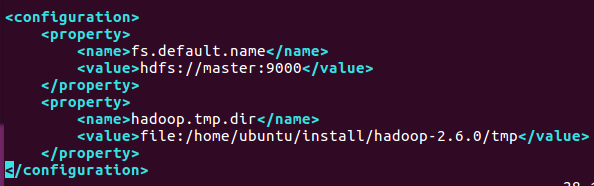
<configuration>
<value>hdfs://master:9000</value>
<value>file:/home/ubuntu/install/hadoop-2.6.0/tmp</value>
命令:vim core-site.xml
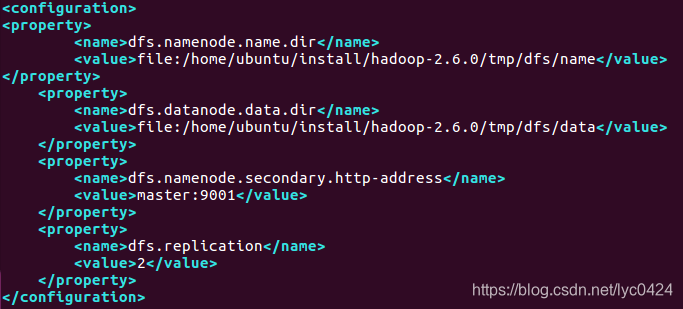
<configuration>
<name>dfs.namenode.name.dir</name>
<value>file:/home/ubuntu/install/hadoop-2.6.0/tmp/dfs/name</value>
<name>dfs.datanode.data.dir</name>
<value>file:/home/ubuntu/install/hadoop-2.6.0/tmp/dfs/data</value>
<name>dfs.namenode.secondary.http-address</name>
命令:vim hdfs-site.xml
(先将mapred-site.xml.template重命名为:mapred-site.xml)
<configuration>
<name>mapreduce.framework.name</name>
<name>mapreduce.jobhistory.address</name>
<name>mapreduce.jobhistory.webapp.address</name>
cp mapred-site.xml.template mapred-site.xml
命令:vim mapred-site.xml
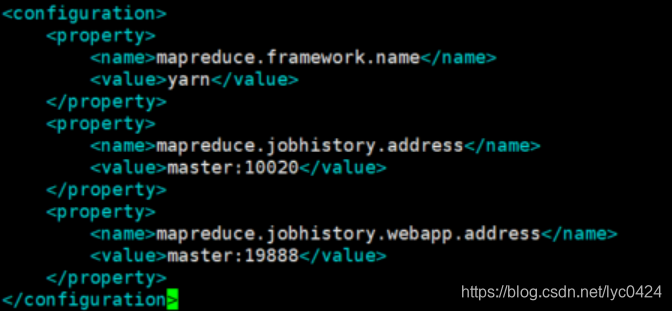
<configuration>
<name>yarn.resourcemanager.hostname</name>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<name>yarn.log-aggregation-enable</name>
<name>yarn.log-aggregation.retain-seconds</name>
命令:vim yarn-site.xml
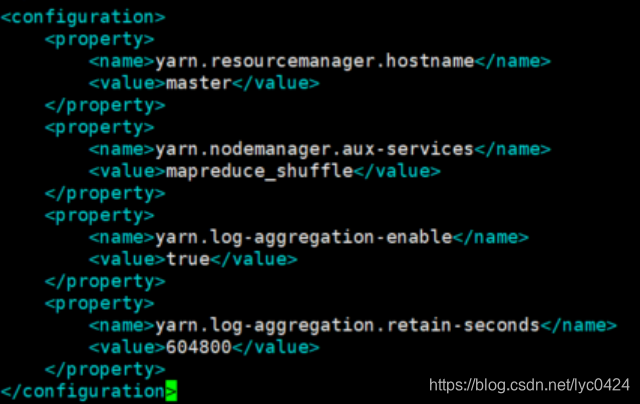
5.3 将配置好的hadoop-2.6.0文件夹分发给所有slaves
scp -r ~/install/hadoop-2.6.0 ubuntu@slave1:~/install/hadoop-2.6.0
scp -r ~/install/hadoop-2.6.0 ubuntu@slave2:~/install/hadoop-2.6.0
5.4 格式化
格式化:hadoop namenode -format(对namenode进行初始化)
5.5 验证Hadoop是否安装配置成功
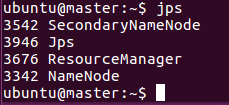
命令:start-all.sh

可看到master节点:Jps、NameNode、SecondNameNode、ResourceManager
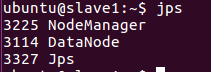
slave1~2节点:Jps、DataNode、NodeManager
网页验证:在Master浏览器输入http://Master:50070/
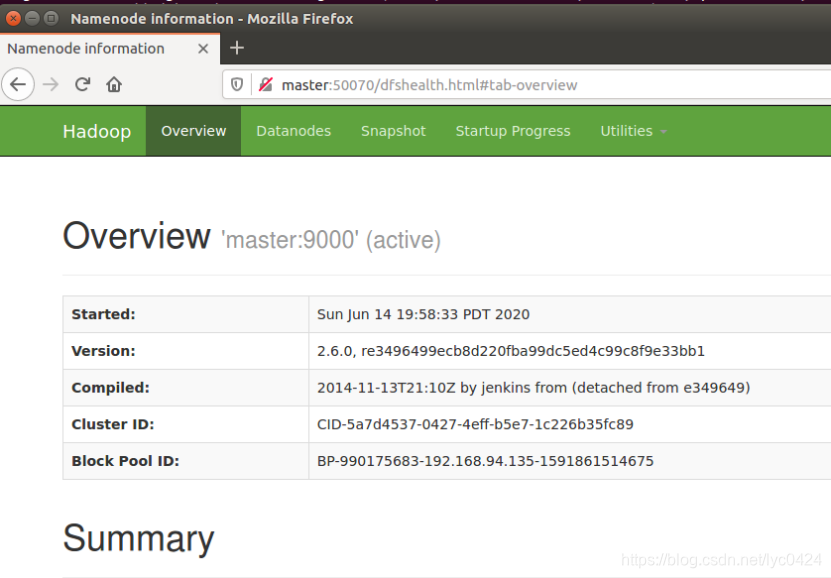
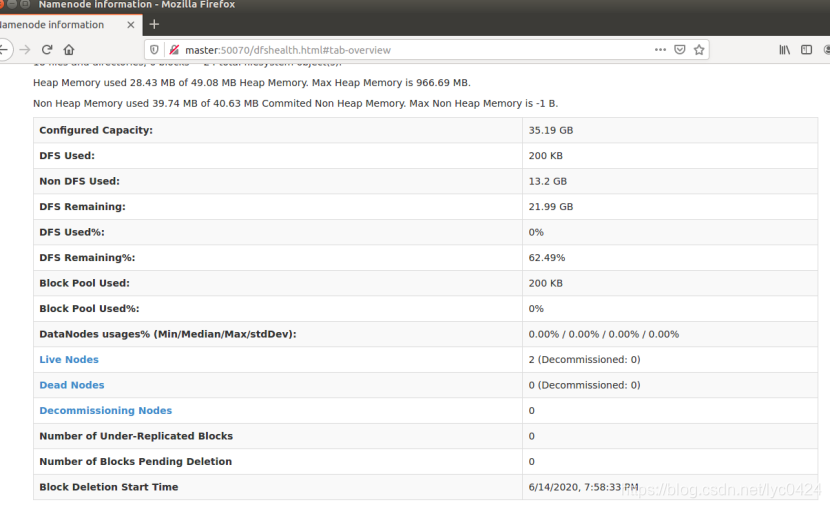


















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









