




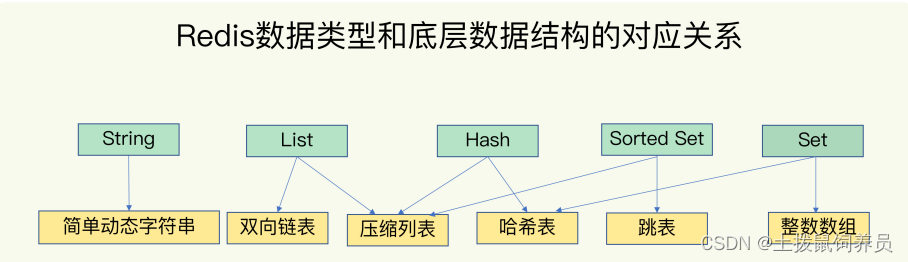
O(1) 时间复杂度就能找到对应的哈希桶位置,然后就可以访问相应的 entry 元素。
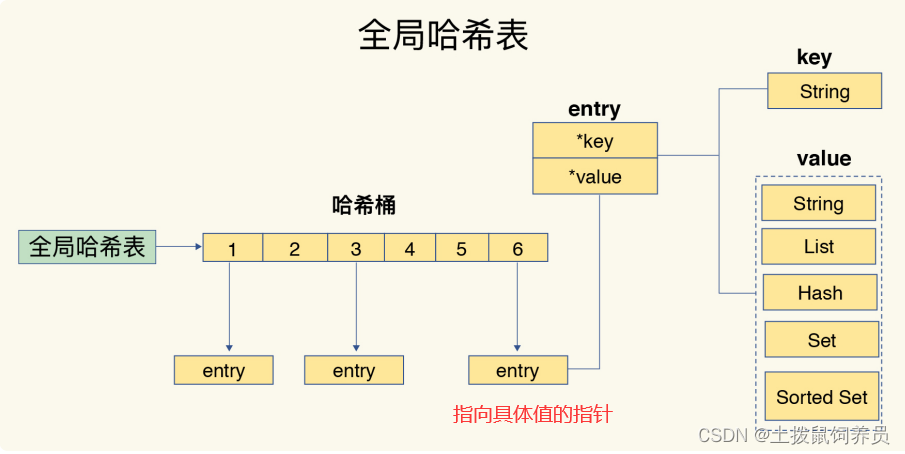
为什么哈希表操作变慢了?
哈希冲突导致的一个哈希桶形成的链表
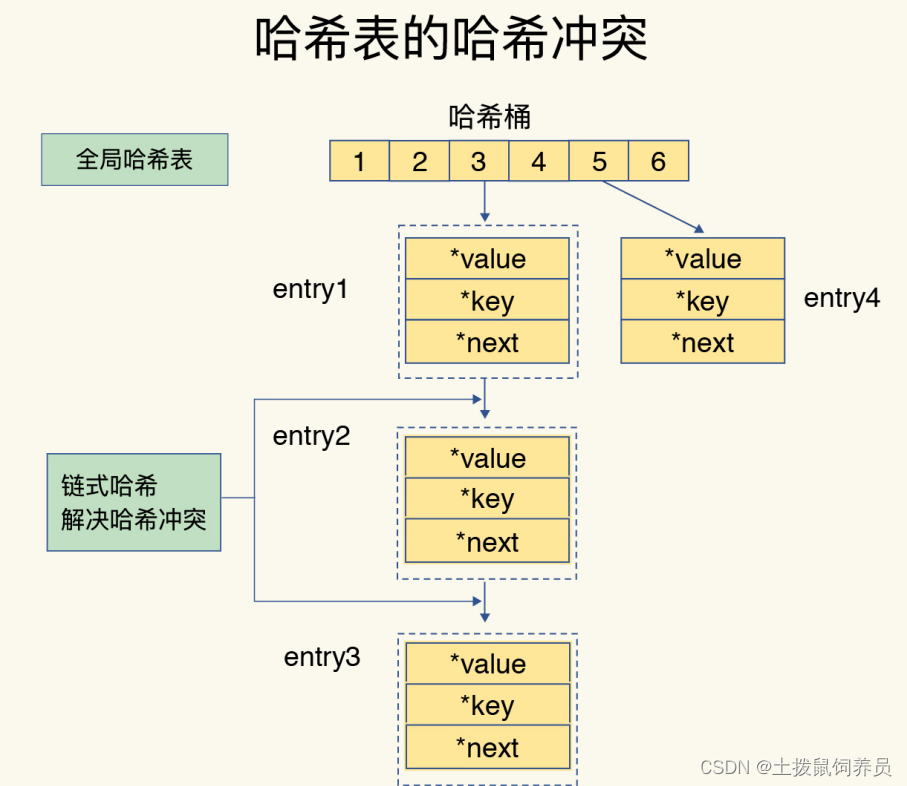
为了保持高效的查找,redis会进行rehash操作,让元素更分散。
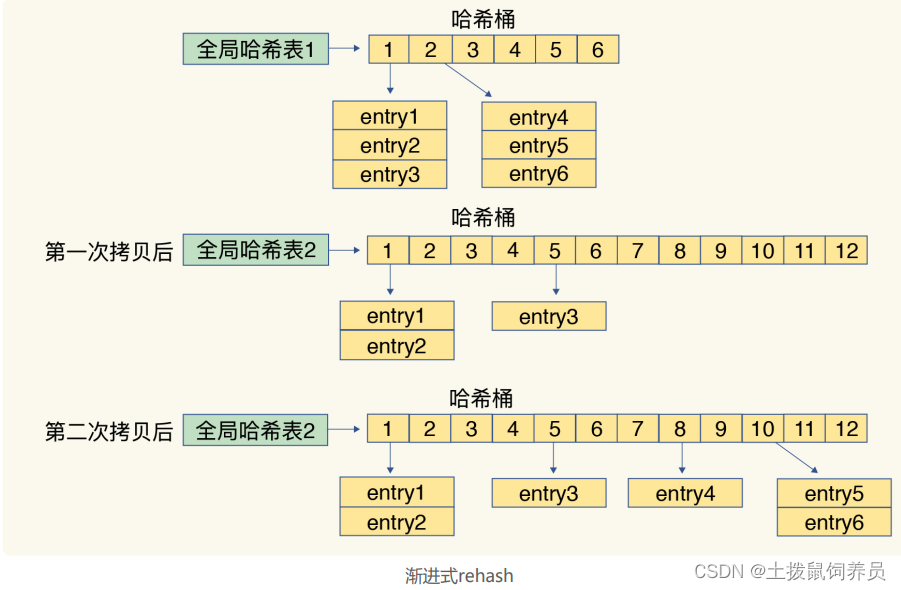
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。刚插入数据时,默认使用哈希表 1,数量增多会进行rehash,分为三步:
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 释放哈希表 1 的空间。
下次的时候就可以让 哈希表1进行扩容备用。
为了避免一次性拷贝造成的线程阻塞,采用了 渐进式rehash,将一次性的拷贝分摊
- 每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的entries。

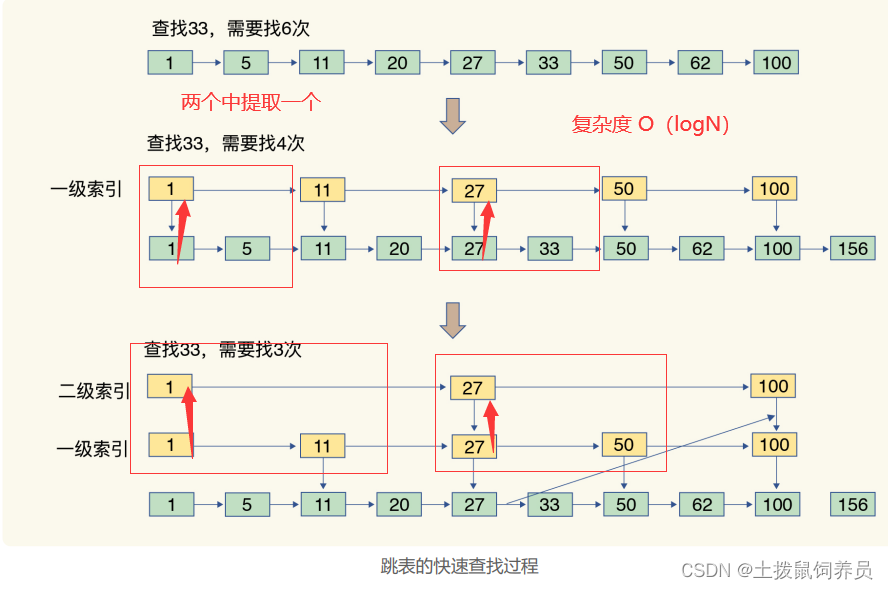
头尾复杂度 O(1) ,中间复杂度 O(N)
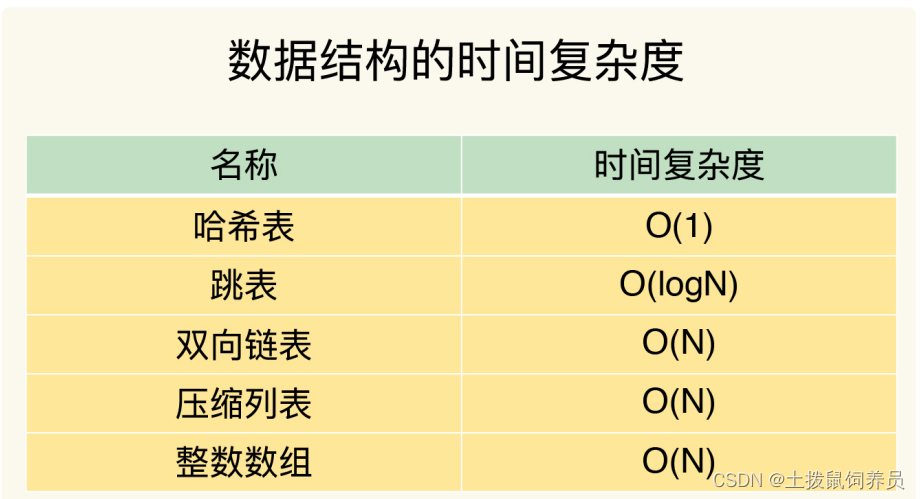
- 整数数组和压缩列表查询效率不高,Redis为啥使用?
1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
redis为什么用单线程?
- 多线程会引起共享资源的并发控制问题
- 加锁也可能会导致线程的吞吐量降低
单线程 Redis 为什么那么快?
- 使用了内存,使用了高校的数据结构(哈希表,跳表)
- IO多路复用
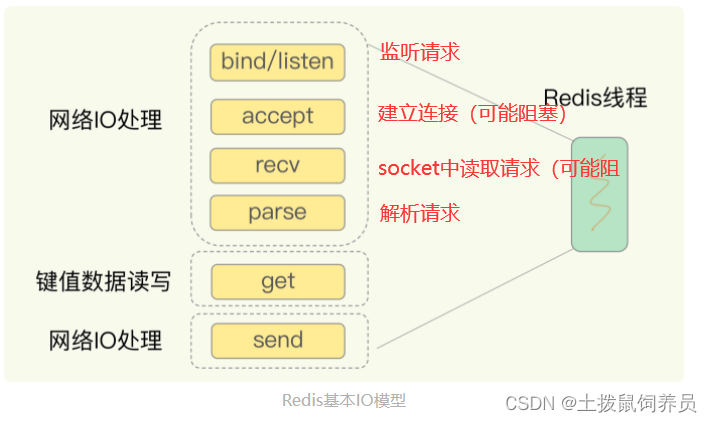

基于多路复用的高性能 I/O 模型
- 基于linux select/epoll
- 内核可同时监听多个监听套接字和 多个已连接套接字
- 一旦内核监听到套接字上有数据返回,立刻交给redis线程处理数据
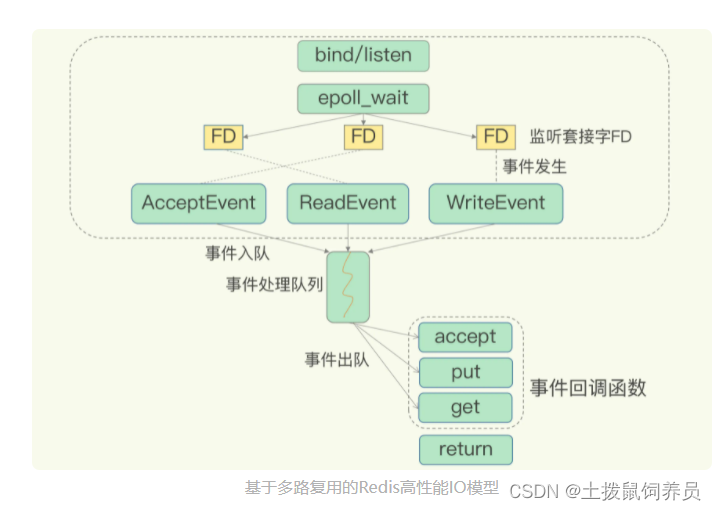
- 所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
- 这些事件会放入到队列中,Redis无需一直轮询是否有事件,只要多事件处理队列进行处理
Redis单线程处理IO请求性能瓶颈主要包括2个方面:
1、任意一个请求在server中一旦发生耗时,都会影响整个server的性能。耗时的操作包括以下几种:
a、操作bigkey
b、使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据;
c、大量key集中过期:Redis的过期机制也是在主线程中执行的,大量key集中过期会导致处理一个请求时,耗时都在删除过期key,耗时变长;
d、淘汰策略:淘汰策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会造成耗时变长;
e、AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能;
f、主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久;
2、并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
针对问题1,一方面需要业务人员去规避,一方面Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
针对问题2,Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。
select poll(select根据不同的系统,文件描述符限制为1024或者2048,poll没有数量限制),文件描述符集合保存在用户态,每次把集合传入内核态,内核态返回ready的文件描述符。
epoll是通过epoll_create和epoll_ctl和epoll_await三个系统调用完成的,每当接入一个文件描述符,通过ctl添加到内核维护的红黑树中,通过事件机制,当数据ready后,从红黑树移动到链表,通过await获取链表中准备好数据的fd,程序去处理。

















 919
919




 到【灌水乐园】发言
到【灌水乐园】发言







