 C语言链表实现
C语言链表实现





学习到了数据结构中的链表,写此文档方便自己加固理解,加深记忆。
链表与数组同为线性结构,但是区别于数组。在定义数组时存储的大小必须是已知,并且在内存分配中是必须连续的,所以可以使用下标随机访问。
链表在内存中的分配非常灵活,但也就无法进行随机访问,必须遍历,顺序访问链表中的某一个节点。
节点:链表中存放有效数据的单位。
头节点:在单链表的第一个结点之前附设一个结点,称之为头结点。
首节点:第一个存储有效数据的节点。
尾节点:单链表中最后一个节点。
数据结构中的链表只是一种抽象的定义,提供了一种方法,具体的实现因编程语言而异。
在C语言中节点用结构体来实现。
typedef struct node
{
int data;//数据域,存放有效数据
struct node* pNext;//指针域,指向了下一个节点
}NODE;接下来就可以创建链表了。
首先,先定义一个头节点指向第一个节点,头节点内不存放有效数据,这样可以方便对链表操作。
需要注意到一个细节,每次新建一个结点时,都需要把新节点挂在上一个节点后。pHead->pNext = pNew;
如果这样操作的话会导致一个错误的结果。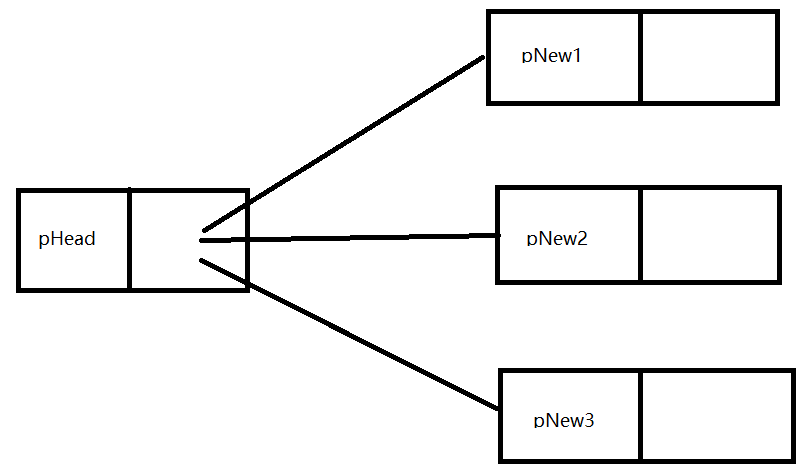 循环会形成这样的结构。这样的结构不是链表而是树的结构。
循环会形成这样的结构。这样的结构不是链表而是树的结构。
一个简单的解决办法就是用一个指针始终指向链表的尾节点,在增加节点时与这个指针进行交换来实现对链表增加节点(目前很模糊的理解2018.6.5)。
# include <stdio.h>
# include <stdlib.h>
//---------结构体------------------------------------------------------
typedef struct node
{
int data;
struct node* pNext;
}NODE;
//-----------函数声明-------------------------------------------------------
NODE* create_linklist (); //创建链表并返回头节点
void traversal_linklist (NODE* pHead); //对链表遍历
//-------------主函数-----------------------------------------------------
int main (void)
{
NODE* pHead = create_linklist(); //调用函数,返回头节点方便对链表进行操作。
traversal_linklist (pHead); //对链表进行遍历
return 0;
}
//------------函数体----------------------------------------------------------------
//-----------创建链表--------------------
NODE* create_linklist ()
{
int i=0; //循环
int len; //链表的长度
int val; //用户存放在每个节点内的值
NODE* pHead = (NODE*)malloc(sizeof(NODE)); //为头节点分配一块空间存放链表首节点的信息
NODE* pTail = pHead;
puts ("输入链表的长度");
scanf ("%d",&len);
for (; i<len; i++)
{
printf ("输入第%d节点的值\n",i+1);
scanf ("%d",&val);
NODE* pNew = (NODE*)malloc(sizeof (NODE));
pNew->data = val;
pTail->pNext = pNew;
pTail = pNew;
pTail->pNext = NULL;
}
return pHead;
}
//--------链表的遍历-------------
void traversal_linklist (NODE* pHead)
{
NODE* p = pHead->pNext;
while (p)
{
printf ("链表内的值%d ",p->data);
p = p->pNext;
}
puts ("");
}

















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









