




 本文分析了Spark应用程序中SparkContext对象的初始化流程,重点介绍了standalone模式下SchedulerBackend和TaskScheduler的创建过程,以及与之相关的DAGScheduler启动流程。
本文分析了Spark应用程序中SparkContext对象的初始化流程,重点介绍了standalone模式下SchedulerBackend和TaskScheduler的创建过程,以及与之相关的DAGScheduler启动流程。
SparkContext初始化源码分析
在我们写一个Spark应用程序时,都会创建一个SparkContext对象,下面将分析在创建一个SparkContext对象的时候都做了哪些事情。
因为这里有多种运行模式,这里只分析在standalone模式下运行的初始化流程
整体的运行流程如下图所示:
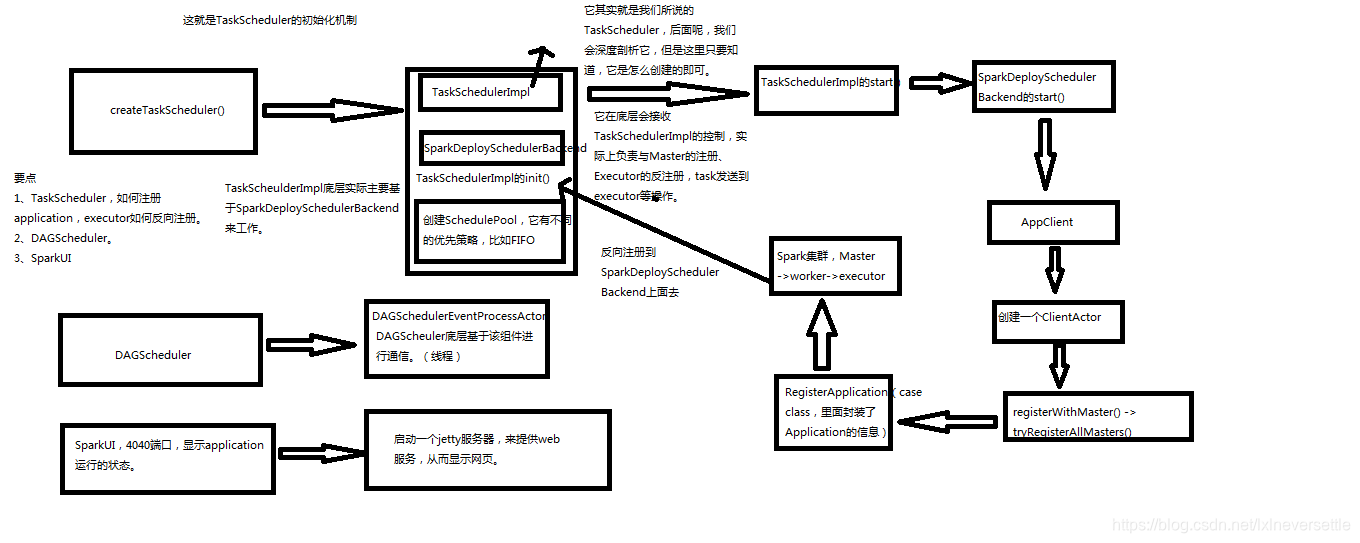
这里需要注意的是,上面的流程图是旧版本的SparkContext初始化的流程图,新版本和它没什么太大区别,主要是新版本更换了新的rpc通信组件,旧版本使用的actor,新版本使用的是netty,对应ClientActor的是ClientEndPoint
Standalone模式
首先看创建SchedulerBackend以及TaskScheduler的代码
master指定是在local,yarn或者standalone下运行
deployMode指定是在client还是cluster模式下运行
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
下面方法的主要作用就是根据master和deployMode来创建对应类型的SchedulerBackend以及TaskScheduler
在Standalone模式下创建的是StandaloneSchedulerBackend以及TaskSchedulerImp
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
// 根据master内容来创建组件
// 这里还有其他几种模式的创建过程,但是只分析standalone模式下的
master match {
// 这是我们常用的spark standalone模式
case SPARK_REGEX(sparkUrl) =>
// 首先使用SparkContext来创建taskScheduler
val scheduler = new TaskSchedulerImpl(sc)
// 这里不止一个master,但是只有一个是active的
val masterUrls = sparkUrl.split(",").map("spark://" + _)
// 将taskScheduler作为参数传入了Backend的构造函数中
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
// 将backend赋予自己的一个类变量
// 根据策略创建了相应策略的调度池
// scheduler和banckend互相持有对方的引用
scheduler.initialize(backend)
(backend, scheduler)
}
}
// TaskSchedule进行初始化
// 主要是创建一个根据策略创建一个线程池
def initialize(backend: SchedulerBackend) {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
下面的方法代表在创建完SchedulerBackend和TaskScheduler之后,还会创建一个DAGScheduler,然后启动TaskScheduler
_dagScheduler = new DAGScheduler(this)
_taskScheduler.start()
看一下TaskSchedulerImpl的start()
// 这里主要调用了backend的start方法
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleWithFixedDelay(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
在看下StandaloneSchedulerBackend的start()
override def start() {
// 执行父类CoarseGrainedSchedulerBackend的start方法,该方法会创建一个属于driver的rpc终端,用来通信
super.start()
//...................
// 这个ApplicationDescription非常重要,描述了应用对资源的需求情况
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
// 在后端中创建一个App client
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
// onStart方法中向master进行注册
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
下面看一下StandaloneAppClient的start()
def start() {
// Just launch an rpcEndpoint; it will call back into the listener.
// spark2.x不再使用Actor
// 在seupEndpoint中会对新创建的CientEndPoint进行注册
// 会启动AppClinet,进而调用onStart方法
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}
上面的代码会触发ClientEndpoint的start()方法,也会触发onStart()
ClientEndPoint
override def onStart(): Unit = {
try {
// 向master进行注册
registerWithMaster(1)
} catch {
case e: Exception =>
logWarning("Failed to connect to master", e)
markDisconnected()
stop()
}
}
// 尝试向所有的master进行注册,会尝试多次,如果超过最大尝试次数,会打印注册失败信息,并且放弃注册
private def registerWithMaster(nthRetry: Int) {
registerMasterFutures.set(tryRegisterAllMasters())
// 以一定的频率重试注册
registrationRetryTimer.set(registrationRetryThread.schedule(new Runnable {
override def run(): Unit = {
// registered是一个AtomicBoolean变量,用来代表是否注册成功
// 当ClientEndPoint收到来自master的注册成功响应时,会将该变量置为true
// 如果向master注册成功,那么会取消当前正在运行的所有注册线程
// 并且会关闭注册线程池
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
} else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1)
}
}
}, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
}
// 方法返回的是向每个master注册之后得到的响应数组
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
// 向每个master进行注册
for (masterAddress <- masterRpcAddresses) yield {\
// 内部使用一个注册线程池来向master进行注册
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
// 向指定的master发送注册信息
// 并且将返回值添加到数组中
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}
下面总结一下流程:
(1)首先根据运行参数创建相应类型的TaskScheduler以及SchedulerBackend,TaskScheduler和SchedulerBackend互相拥有对方的引用
(2)初始化TaskScheduler,这里主要就是根据调度策略初始化线程池,提供两种调度策略,FIFO和FAIR
(3)接着创建DAGScheduler
(4)在调用TaskScheduler的start()中会调用SchedulerBackend的start(),并且TaskScheduler的其启动工作主要就是启动SchedulerBackend
(5)SchedulerBackend,在standalone模式下是StandaloneSchedulerBackend,当调用StandaloneSchedulerBackend的
start()方法时,会调父类CoarseGrainedSchedulerBackend的start(),在父类的start()方法中,主要是读取SparkContext中的参数信息
使用参数信息创建一个driverEndpoint
(6)现在回到StandaloneSchedulerBackend的start()方法,在该方法中首先创建一个应用描述信息对象ApplicationDescription对象
该对象描述了应用对资源的需求情况,因此十分重要。接着创建了一个StandaloneAppClient对象,并且调用了该对象的start()方法。StandaloneAppClient的主要作用就是和集群的其他组件进行通信
StandAppclient的start()方法会触发ClientEndPoint的onStart()方法以及start()方法
在ClientEndPoint的onStart()方法中,会向所有的master发送注册信息,并且不成功会重复多次
(7)在StandaloneSchedulerBackend的末尾会将运行状态修改为SUBMITTED,然后等待向master的注册完成之后,将状态修改为RUNNING

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









