




在消费者被协调者节点coordinator(也是消费者,只是第一个发送加组请求的消费者)分配好消费方案后,如何拉取消息呢?下面我们结合流程图来理解下:
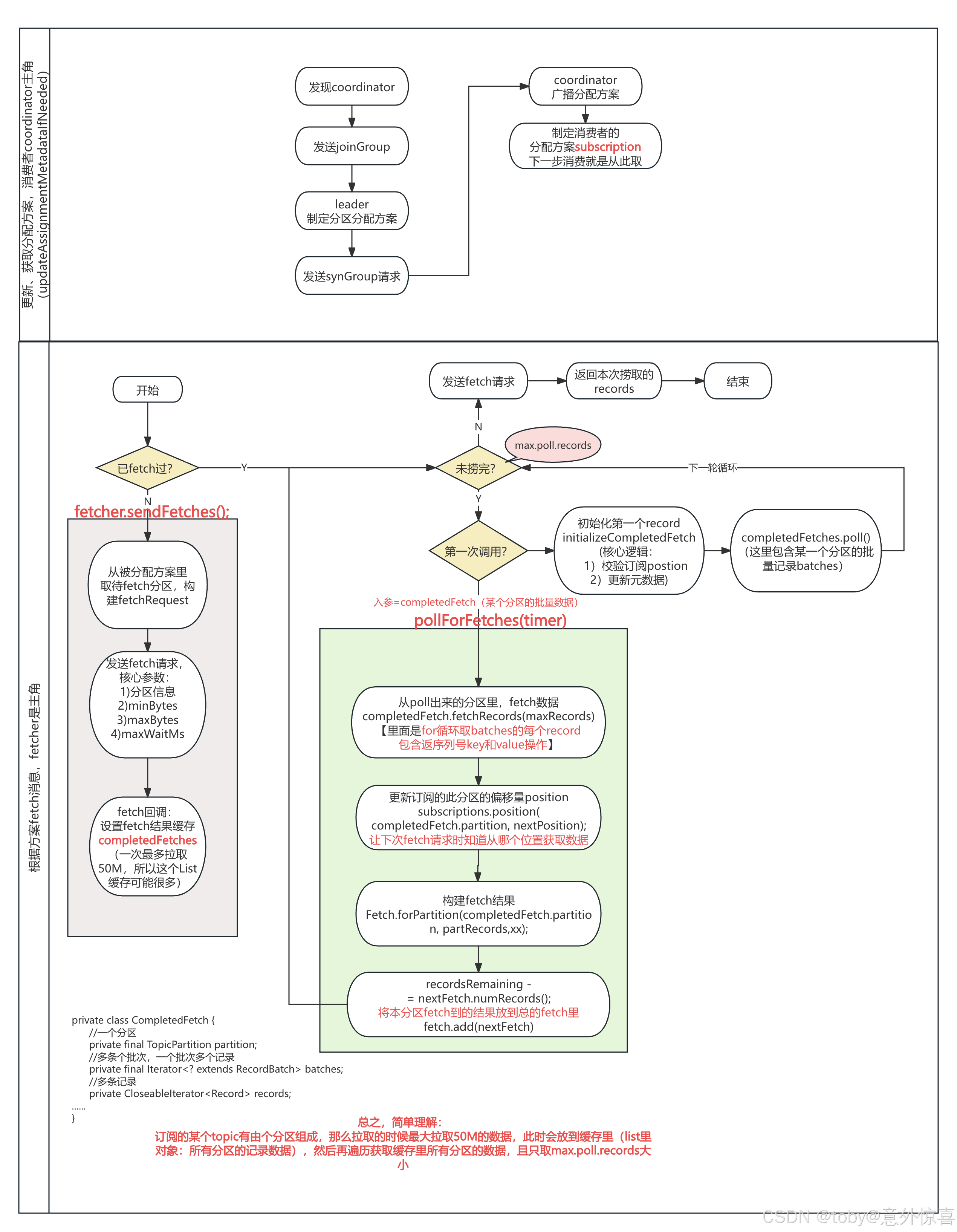
核心思想其实就是:从指定位置(分区偏移量)、指定大小(一次捞取多少)、指定topic分区向broker的主节点发送fetch请求,一次性把一大批的分区数据拉到消费者本地内存,然后按照用户的消费配置(max.poll.records)依次给出响应数据。
下面我们结合流程图逐步分析下(下半部分图):
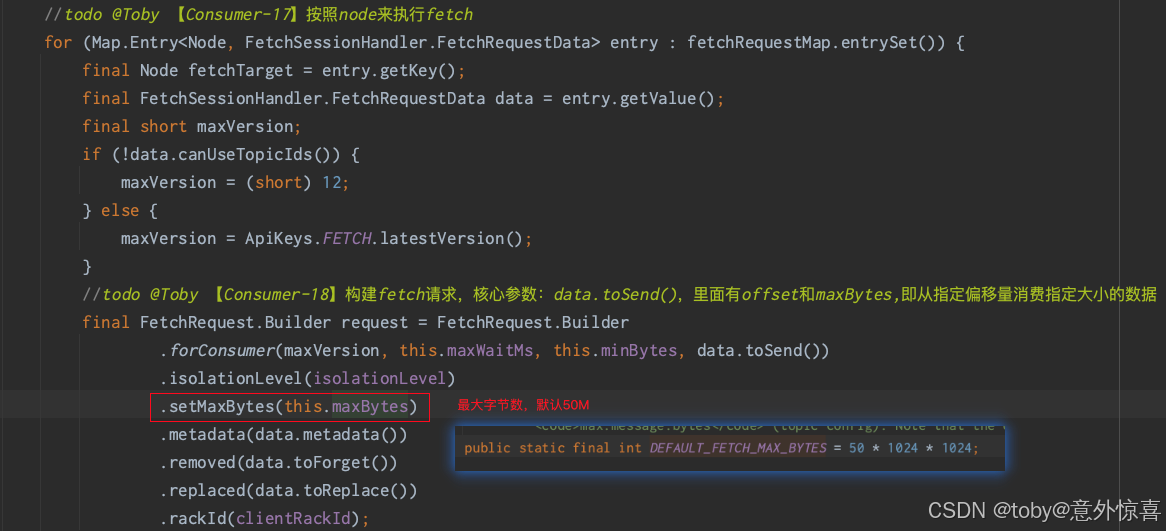
- 先判断是否已经发送过fetch请求,即之前已经从broker捞取数据且缓存有数据,如果没有则进入灰色方块流程,给broker发送fetch请求,核心参数如下。拉取后把分区信息放入本地缓存里。
- 分区信息:主要是topic和分区
- minBytes:最小拉取多少个字节
- maxBytes :最大拉取多少字节,默认50M
- 如果fetch过,则每次请求时只从缓存中拿。这个大家应该印象比较深刻,即客户端的map.poll.records配置,比如默认值为500。则本次会调用源码里的pollForFetches,从缓存中取出500个消息,然后在自己的缓存里对本次拉到的偏移量位置打标,方便下次知道从哪个地方消费数据。
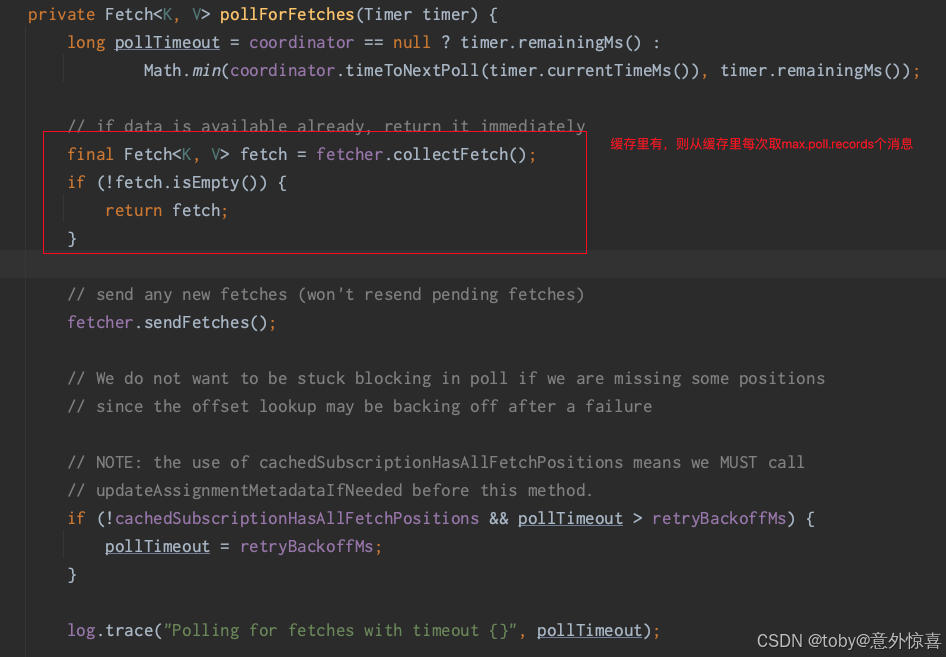 进去后发现,里面就是按照配置(max.poll.records)从缓存里取数据:
进去后发现,里面就是按照配置(max.poll.records)从缓存里取数据: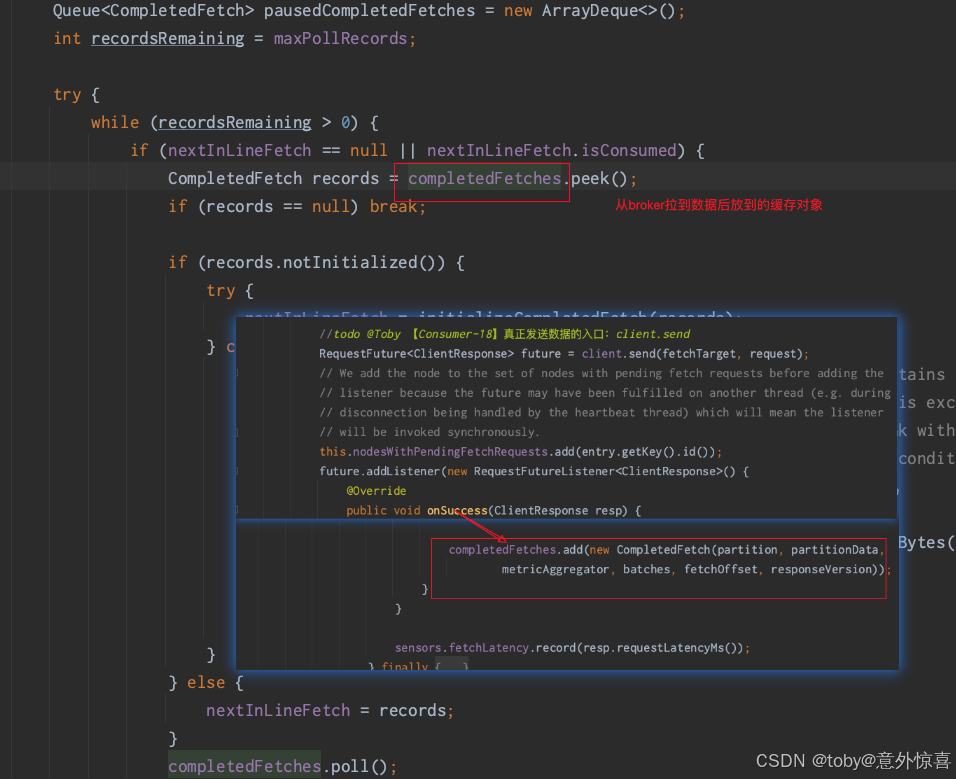 completedFetches则是每次给broker发送fetch请求成功后,将数据塞入的结合对象。
completedFetches则是每次给broker发送fetch请求成功后,将数据塞入的结合对象。 - 将500个偏移量消息成功给到消费者后,缓存里会减掉500个。如此循环,等缓存里没有数据了消费者客户端才会向broker发送fetch请求,如此往返。
注意这里从缓存返回消息后,会给缓存的消息打标(position),以便知道下次循环该从哪个位置开始消费,但是这里的打标并不是提交偏移量。

















 975
975



 到【灌水乐园】发言
到【灌水乐园】发言








