




 本文详细介绍了MySQL慢查询日志的配置与使用,包括如何开启和设置阀值,利用mysqldumpslow工具进行慢SQL分析,以及通过存储过程和函数模拟海量数据插入,帮助读者掌握SQL调优技巧。
本文详细介绍了MySQL慢查询日志的配置与使用,包括如何开启和设置阀值,利用mysqldumpslow工具进行慢SQL分析,以及通过存储过程和函数模拟海量数据插入,帮助读者掌握SQL调优技巧。
SQL排查
--- 慢查询日志: MySQL提供的一种日志记录用于记录MySQK中响应时间超过 阀值 的 sql语句 (long_query)
慢查询日志默认是关闭
建议:开发调优是打开 而最终部署时关闭
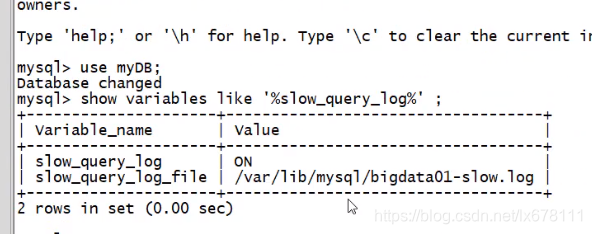
检查是否开启了慢查询日志
show variables like '%slow_query_log';
临时开启:
set global slow_query_log=1
在内存开启
永久开启:

阀值: show variables like '%long_queury_time%';
临时设置阀值: set global long_queury_time = 5;
重新登录生效 不需要重启服务
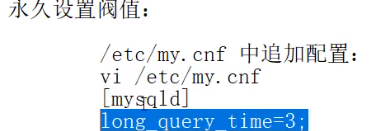
永久设置阀值:
慢查询阀值和mysqldumpslow工具
查询超过阀值得sql : show global status like '%slow_queries';
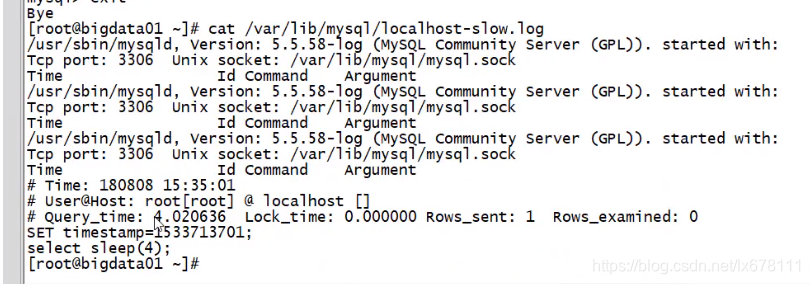
cat /var/lib/mysql/localhost-slow.log
(2)通过mysqldumpslow工具查看慢sql 可以通过一些过滤条件 快速查找需要定位的慢sql
mysqldumpslow --help
s:order排序方式
r:逆序
l:锁定时间
g:正则匹配模式
-- 获取返回记录组多的3个sql : mysqldumpslow -s r -t 3 /var/lib/mysql/localhost-slow.log
-- 获取访问次数最多的3个SQL mysqldumpslow -s c -t 3 /var/lib/mysql/localhost-slow.log
--- 按照时间排序,前10条包含left join 查询语句的sql mysqldumpslow -s t -t 10 -g "left join"
分析海量数据
用存储过程 、存储函数 模拟海量数据
通过存储函数 插入海量数据
创建存储函数: 存储过程 无return 存储函数 有return
delimiter $
create function randString(n int) returns varchar(255)
begin
declare all_str varchar(100)default 'abcdefg.....'
declare return_str varchar(255) default '';
declare i int default 0;
while i<n
do
set return_str - concat(return_str.substring(all_srt,FLOOR(rand()*52)+1,1) );
set i=i+1;
end while;
return return_str;
end $
--产生随机整数
delimiter $
create function ran_run() returns int(5)
begin
declare i int default 0
set i - floor(rand()*100);
return i;
end $
create produre insert_emp(in eid_start int(10), in data_times int(10))
begin
declare i int default 0;
set autocommit = 0; --关闭自动提交
repeat
insert into emp values(eid_start + i ,randstring(5), 'other' ,ran_nu())
set i=i+1;
until i = data_times
end repeat;
commit;
end $
- - 通过存储过程插入海量数据,dept表中
create produre insert_dept(in dno_start int(10), in data_times int(10))
begin
declare i int default 0;
set autocommit = 0; --关闭自动提交
repeat
insert into dept values(dno_start + i ,randstring(6), randstring(8))
set i=i+1;
until i = data_times
end repeat;
commit;
end $
- - 插入数据
delimiter ;
call insert_emp (1000,800000);
call insert_dept(10,30);
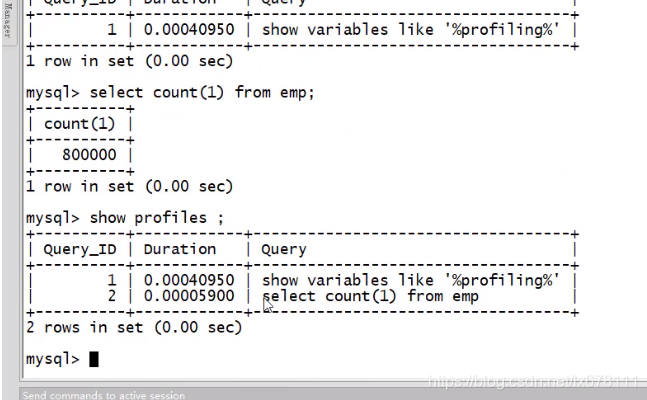


show profiles
show variables like '%profiling’
set profiling = on;
查询全局日志
这些全局的记录操作 仅仅在开发和调优过程中打开即可,部署时一定要关闭
show variables like '%general_log%';
- - 执行的所有sql记录在表中
set global general_log = 1
set global log_output ='table'
- -执行的所有sql记录在文件中
set global log_output ='file'
set global general_log_file ='/tmp/general.log'
set global general_log= 1
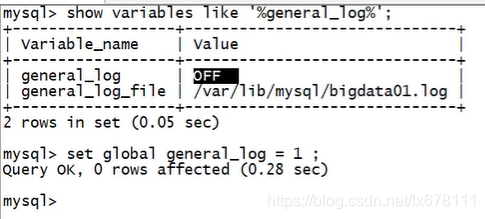
开启全局日志 会记录所有sql : 会被记录 到 mysql.general_log表中。
select * from mysql.general_log

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









