




目录
一、机器学习的定义
定义:主要通过概率论、统计学等数学的方法,让机器从已知数据中模拟或实现人类的学习行为,找出规律并自动生成规则,然后对未知数据进行预测。
二、机器学习可解决的问题
1.监督学习
- 监督算法:输入数据已知,提供输出数据。
- 实例:1.基于医学影像判断肿瘤是否为良性(输入的是影像,输出的是肿瘤是否为良性)
2.检测信用卡交易中的诈骗行为(输入的是信用卡交易记录,输出的是该交易记录是否可能为诈骗)
2.无监督学习
- 无监督算法:输入数据已知,没有提供输出数据。
- 实例:1.确定一系列博客文章的主题(有许多文本数据,找到共同主题的文章并归为一类,但事先并不知道有多少个可能的主题,所以输出是未知的)
2.将客户分成具有相似偏好的群组
三、样本,特征,标签
将输入数据表征为计算机可以理解的形式非常重要,通常来说,将数据想象成表格。
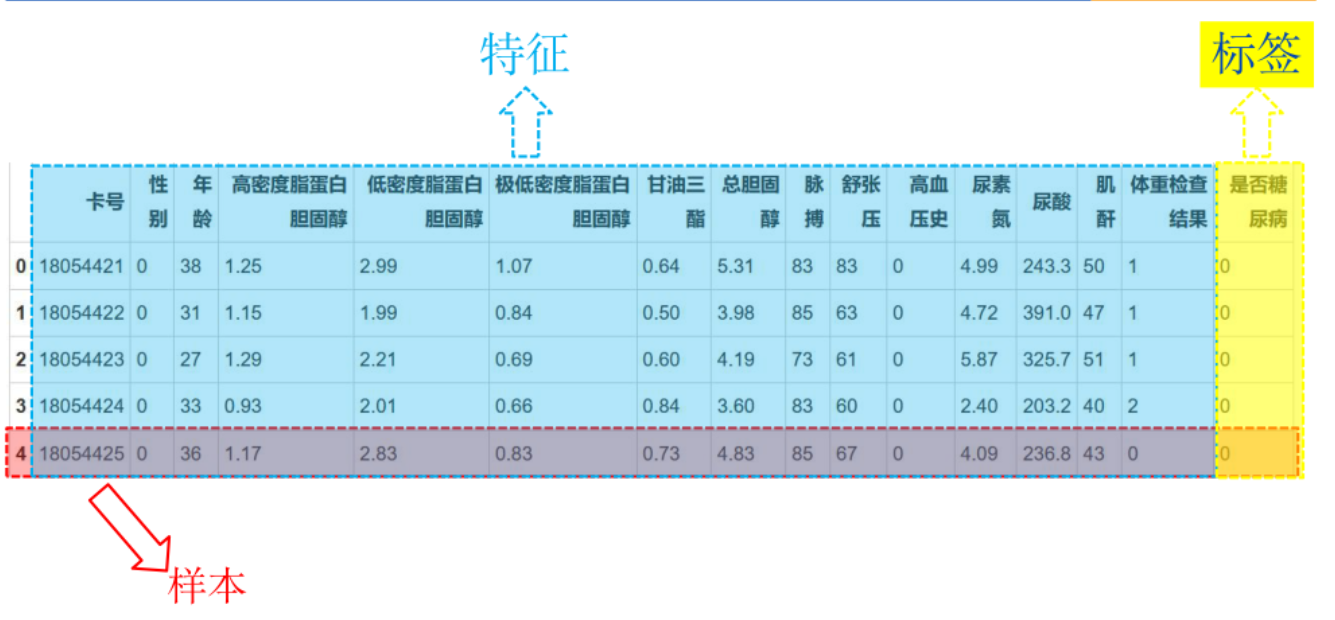
样本:表格中每一行
特征:表格中描述样本的属性的每一列
标签:表格中预期输出数据的一列
四、必要的库和工具
1.sklearn库
pip install scikit-learn2.matplotlib
作用:可视化内容,如折线图、直方图、散点图等。
pip install matplotlib
3.pandas库
作用:从许多文件格式和数据库中提取数据,如excel文件、csv(逗号分隔值)文件和SQL。
pip install pandas4.Jupyter notebook
它是一个可以在浏览器中运行代码的交互环境。可以在终端用 pip install Jupyter notebook 进入该工具中编写代码。当然还可以在官网下载该工具。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









