




 本文详细介绍了Hive中的数据类型,包括基本类型如数值型、日期型、字符型,以及复杂类型如ARRAY、MAP、STRUCT。还讨论了时间戳、Decimal类型的特性和使用,以及数据类型的转换。此外,文章提到了Hive的数据格式,如TextFile、SequenceFile、RCFile,以及数据存储在HDFS中的组织方式,包括Table、External Table、Partition和Bucket的概念。
本文详细介绍了Hive中的数据类型,包括基本类型如数值型、日期型、字符型,以及复杂类型如ARRAY、MAP、STRUCT。还讨论了时间戳、Decimal类型的特性和使用,以及数据类型的转换。此外,文章提到了Hive的数据格式,如TextFile、SequenceFile、RCFile,以及数据存储在HDFS中的组织方式,包括Table、External Table、Partition和Bucket的概念。
3.1.9 Hive的数据类型与数据格式
Hive的数据类型有两种,一种是基本的数据类型,一种是复杂的数据类型。首先看一下Hive基本数据类型,第一个是数值型,如表2-1所示,

(1)Integral Types (TINYINT, SMALLINT, INT/INTEGER, BIGINT):默认情况下,整数型为INT型,当数字大于INT型的范围时,会自动解释执行为BIGINT,或者使用以下后缀进行说明。
(2)Decimals:Hive的小数型是基于Java BigDecimal的,BigDecimal在Java中用于表示任意精度的小数类型。所有常规数字运算(例如+、-、*、/)和相关的UDF(如Floor、Ceil、Round等)都使用和支持Decimal。可以将Decimal和其他数值型互相转换,且Decimal支持科学计数法和非科学计数法。因此,无论数据集是否包含如4.004E + 3(科学记数法)或4004(非科学记数法)或两者的组合的数据,都可以使用Decimal。
从Hive 0.13开始,用户可以使用DECIMAL(precision, scale) 语法在创建表时来定义Decimal数据类型的precision和scale。 如果未指定precision,则默认为10。如果未指定scale,将默认为0(无小数位)
CREATE TABLE foo (
a DECIMAL, – Defaults to decimal(10,0)
b DECIMAL(9, 7)
)
大于BIGINT的数值,需要使用BD后缀及Decimal(38,0)来处理,如
select CAST(18446744073709001000BD AS DECIMAL(38,0)) from my_table limit 1;
Decimal在Hive 0.12.0和0.13.0之间是不兼容的,故0.12前的版本需要迁移才可继续使用。
基本类型中除了数值型,还有日期型,关于日期型以及支持版本,如表2-2所示,

(1)Timestamps
支持传统的UNIX时间戳和可选的纳秒精度。
- 支持的转化
- 整数数字类型:以秒为单位解释为UNIX时间戳
- 浮点数值类型:以秒为单位解释为UNIX时间戳,带小数精度
- 字符串:符合JDBC java.sql.Timestamp格式“YYYY-MM-DD HH:MM:SS.fffffffff”(9位小数位精度)
时间戳被解释为无时间的,并被存储为从UNIX纪元的偏移量。提供了用于转换到和从时区转换的便捷UDF(to_utc_timestamp,from_utc_timestamp)。
所有现有的日期时间UDF(月,日,年,小时等)都使用TIMESTAMP数据类型。
Text files中的时间戳必须使用格式yyyy-mm-dd hh:mm:ss [.f …]。如果它们是另一种格式,请将它们声明为适当的类型(INT,FLOAT,STRING等),并使用UDF将它们转换为时间戳。
在表级别上,可以通过向SerDe属性“timestamp.formats”(自版本1.2.0 with HIVE-9298)提供格式来支持备选时间戳格式。例如,yyyy-MM-dd’T’HH:mm:ss.SSS,yyyy-MM-dd’T’HH: mm:ss。
(2)Dates
DATE值描述特定的年/月/日,格式为YYYY-MM-DD。例如,DATE'2013-01-01'。日期类型没有时间组件。Date类型支持的值范围是0000-01-01到9999-12-31,这取决于Java Date类型的原始支持。
Date types只能在Date, Timestamp, or String types之间转换,转换类型及结果如表2-3所示。


(3)Intervals
时间间隔在1.2.0之后版本支持,在2.2.0版本上进行了扩展。
第三种最常提及的基本类型是字符型,字符型包含三种,分别是:(1)String:字符串文字可以用单引号(')或双引号(")表示。Hive在字符串中使用C风格的转义。(2)Varchar:Varchar类型使用长度说明符(介于1和65355之间)创建,它定义字符串中允许的最大字符数。如果要转换/分配给Varchar值的字符串值超过length说明符,则字符串将被静默截断。字符长度由字符串包含的代码点的数量确定。像字符串一样,尾部空格在Varchar中很重要,并且会影响比较结果。非通用UDF不能直接使用Varchar类型作为输入参数或返回值。可以创建字符串UDF,而Varchar值将被转换为strings并传递到UDF。要直接使用Varchar参数或返回Varchar值,请创建GenericUDF。如果基于reflection-based方法来获取数据类型信息,则可能存在不支持Varchar的场景。 这包括一些SerDe函数实现。(3)Char:字符类型与Varchar类似,但它们是固定长度的,意味着比指定长度值短的值用空格填充,但尾随空格在比较期间不重要。最大长度固定为255。
了解到基本的数据类型之后,再来看看复杂数据类型都包括哪些。如表3-1所示,
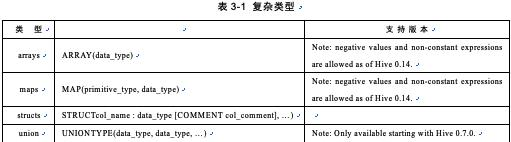
注:UNIONTYPE目前还没有完全支持,官方建议只用于查看,详见官方文档。
(1)ARRAY: ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由[‘apple’,’orange’,’mango’]组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从0开始的;
关于ARRAY的具体操作步骤如下,
首先准备数据:具体数据以及格式如下,
1 football,basketball,tabletannis tom
2 music,movie tomas
然后使用create关键字创建基础表,并且按照数据的格式来使用分隔符,创建表之后可以使用desc关键字来查看该表的表结构,具体代码如下,
create table arrtest(id int,hobbies<string>,name string) row format delimited fields
terminated by ' ' collection items terminated by ',' lines terminated by '\n' stored
as textfile ;
OK
Time taken: 6.014 seconds
hive> desc formatted arrtest;
OK
# col_name data_type comment
id int
hobbies array<string>
name string
# Detailed Table Information
Database: default
Owner: laura
CreateTime: Wed Aug 02 19:01:55 PDT 2017
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://hadoop0:8020/user/hive/warehouse/arrtest
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1501725715
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim ,
field.delim
line.delim \n
serialization.format
Time taken: 1.062 seconds, Fetched: 35 row(s)
接下来加载数据,使用load关键字来加载包含以上数据的数据文件到该表中,具体代码如下,
load data local inpath '/home/centos/arr.dat' into arrtest ;
最后使用select语句查询数据是否插入正确,具体代码如下,
select * from arrtest ;
select id,hobbies[0] from arrtest ;
select id,array('xx','yy') from arrtest ;
(2)MAP: MAP包含key->value键值对,可以通过key来访问元素。比如“userlist”是一个MAP类型,其中username是key,password是value;那么我们可以通过userlist[‘username’]来得到这个用户对应的password;
这几种类型之间主要区别在关键字类型定义不同,这里使用的是MAP类型,具体操作步骤如下,
首先也是准备数据,数据格式定义为MAP形式,第二步创建含有MAP类型字段的表,例如,
create table map1(id int,scores map<string,int>) row format delimited fields terminated by ' ' collection items terminated by ',' map keys terminated by ':' lines terminated by '\n' stored as textfile ;
接下来后续的操作步骤和ARRAY的完全相同,这里不做进一步解释。
(3)STRUCT: STRUCT可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素,比如:在表中有一列a的类型为struct{b string,c string},则我们可以通过指定a.b,a.c来访问域b和c。关于struct类型的操作代码及运行结果如下所示,
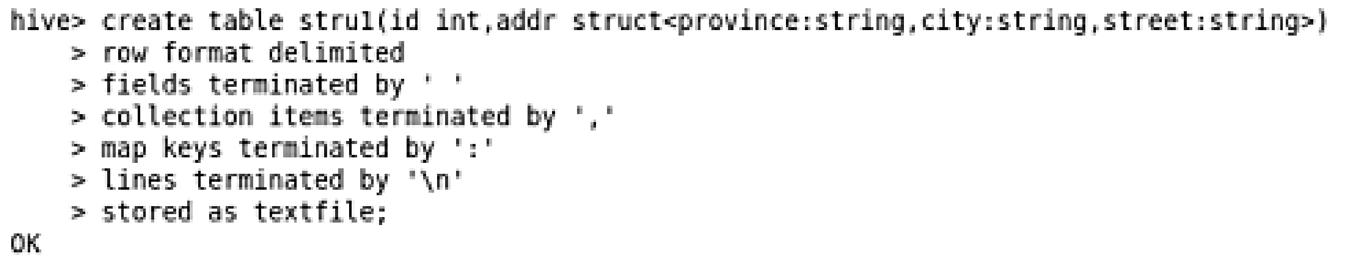
创建表stru1之后,使用desc命令来查看表结构以及一些属性,下面是关于该表的一些描述信息,
hive> desc formatted stru1;
OK
# col_name data_type comment
id int
addr struct<province:string,city:string,street:string>
# Detailed Table Information
Database: default
Owner: laura
CreateTime: Thu Aug 03 00:12:21 PDT 2017
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://hadoop0:8020/user/hive/warehouse/stru1
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1501744341
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim ,
field.delim
line.delim \n
mapkey.delim :
serialization.format
Time taken: 0.625 seconds, Fetched: 35 row(s)
接下来就是向该表中插入一些数据,首先就是创建具有固定格式的数据,具体数据如下,
hebei1,handan1,remin1
hebei2,handan2,remin2
hebei3,handan3,remin3
将上面的数据存储到文件名为stru1.dat中,然后使用load data命令将该文件加载到表stru1中,具体代码以及插入之后的查询数据语句如下,
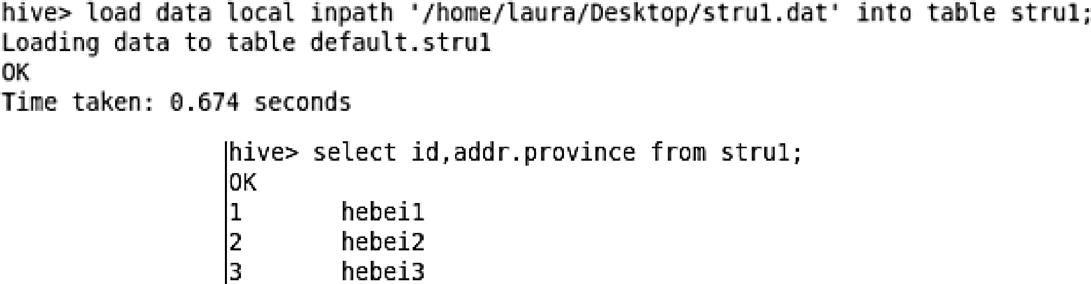
(4)UNION: UNIONTYPE,他是从Hive0.7.0开始支持的。
了解到Hive的复杂类型之后,可以使用一个简单的例子来查看Hive对于数据类型的使用方法,
hive> create table fuzaleixing(id int,arr array<string>,str struct<sex: string,age:int>,ma map<string,int>) stored as textfile;
OK
Time taken: 1.265 seconds
关于数据类型,可以进行类型之间的转换。关于Hive的类型转换有两个常用的关键字,concat和cast。
concat这个函数能够把字符串类型的数据连接起来,连接的某个元素可以是列值。
cast能够将某个列的值显示的转化为某个类型。用法如下所示,
cast(f as type); //类型转换函数
concat(,,,,,) //字符连接函数
最后实现一个完整的demo,首先需要准备数据data.txt:
1 健健妹妹,toronto male,30 db;80
2 倩倩姐姐,montreal male,35 perl:85
然后创建对应的Hive表,并且数据插入到该表中,
hive > create table fuzaleixing(id int,arr array<string>,str struct<sex:string,age:int>,ma map<string,int>) row format delimited fields terminated by ‘\t’ collection items terminated by ‘,’ map keys terminated by ‘:’ stored as textfile;
hive > insert into fuzaleixing(arr,str,ma) values([‘健健妹妹’,’ toronto’],{ "sex":"male","age":30},{"db;80":null});
hive > insert into fuzaleixing(arr,str,ma) values([‘倩倩姐姐,’ montreal ],{ "sex":"male","age":35},{"perl;85":null});
成功插入数据之后,使用select语句查询一下表中的数据,验证一下是否执行成功,
hive> select * from fuzaleixing;
OK
1 ["健健妹妹","toronto"] {"sex":"male","age":30} {"db;80":null}
2 ["倩倩姐姐","montreal"] {"sex":"male","age":35} {"perl":85}
Time taken: 0.649 seconds, Fetched: 2 row(s)
创建表之后,这个地方可以实现一个简单的应用实例,也是大数据领域中比较火的demo,那就是wordcount实例,首先需要把上面表中的数据使用explode[1],这个方法是爆炸的意思,它的作用是可以将单词都打开,都列出来,因此可以把炸裂出来的每一个单词存成新的表,如下,
create table words as select explode(arr) from fuzaleixing;
hive> create table words as select explode(arr) from fuzaleixing;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181122145533_6a313ef3-c8f8-45ab-b4c3-c7269a29e464
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1479847093336_0003, Tracking URL = http://hadoop0:8888/ proxy/application_1479847093336_0003/
Kill Command = /home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479847093336_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-11-22 15:00:24,881 Stage-1 map = 0%, reduce = 0%
2018-11-22 15:00:26,120 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.33 sec
MapReduce Total cumulative CPU time: 1 seconds 330 msec
Ended Job = job_1479847093336_0003
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop0:8020/user/hive/warehouse/myhive.db/.hive- staging_hive_2018-11-22_14-55-46_473_2826816185216022499-1/-ext-10002
Moving data to: hdfs://hadoop0:8020/user/hive/warehouse/myhive.db/words
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.33 sec HDFS Read: 4470 HDFS Write: 377139 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 330 msec
OK
Time taken: 282.979 seconds
接下来可以对新表中的单词进行统计,使用group by方法,group by是对检索结果的保留行进行单纯分组,一般总爱和聚合函数一块用,例如AVG(),COUNT(),MAX(),MAIN()等一块用,group by操作表示按照某些字段的值进行分组,有相同的值放到一起,语法样例如下,
select col,count(*) from words group by col;
hive> select col,count(*) from words group by col;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181122145533_6a313ef3-c8f8-45ab-b4c3-c7269a29e464
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1479847093336_0004, Tracking URL = http://hadoop0:8888/ proxy/application_1479847093336_0004/
Kill Command = /home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479847093336_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-11-22 15:05:43,454 Stage-1 map = 0%, reduce = 0%
2018-11-22 15:05:45,568 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.5 sec
2018-11-22 15:05:46,679 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.97 sec
MapReduce Total cumulative CPU time: 1 seconds 970 msec
Ended Job = job_1479847093336_0004
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.97 sec HDFS Read: 12053 HDFS Write: 762660 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 970 msec
OK
montreal 2
new york 1
shelley 1
toronto 1
will 1
Time taken: 150.607 seconds, Fetched: 5 row(s)
以上的实例即可实现wordcount应用。
如果想要获取Hive中的数据,我们应该怎么操作呢?由于Hive的数据对应的是Hadoop上的数据文件,因此可以使用Hadoop get命令获取到相应数据。
hdfs dfs -get ... .
了解到数据类型之后,接下来来看一下Hive的数据格式都包含哪些。
首先,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以很自由地组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
其次,Hive中所有的数据都存储在HDFS中,Hive中包含以下数据模型:Table,External Table,Partition,Bucket。
Hive中的Table和数据库中的Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录存储数据。例如,一个表pvs,它在HDFS中的路径为:/wh/pvs,其中,wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。
Partition对应于数据库中的Partition列的密集索引,但是Hive中Partition的组织方式和数据库中的很不相同。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。例如:pvs表中包含ds和ctry两个Partition,则对应于ds = 20180801,ctry=US的HDFS子目录为/wh/pvs/ds=20090801/ctry=US;对应于ds=20180801,ctry=CA的HDFS子目录为/wh/pvs/ds=20180801/ctry=CA。
Buckets对指定列计算hash,根据hash值切分数据,目的是为了并行,每一个Bucket对应一个文件。将user列分散至32个bucket,首先对user列的值计算hash,对应hash值为0的HDFS目录为/wh/pvs/ds=20180801/ctry=US/part-00000;hash值为20的HDFS目录为/wh/ pvs/ds=20180801/ctry=US/part-00020。
External Table指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
Table的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE …LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。
Hive有textFile,SequenceFile,RCFile三种文件格式。
其中textfile为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件复制到hdfs上但不进行处理。
SequenceFile,RCFile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中,然后再从textfile表中用insert导入到SequenceFile、RCFile表中。
create table zone0000tf(ra int, dec int, mag int) row format delimited fields terminated by '|';
create table zone0000rc(ra int, dec int, mag int) row format delimited fields terminated by '|' stored as rcfile;
load data local inpath '/home/cq/usnoa/zone0000.asc ' into table zone0000tf;
insert overwrite table zone0000rc select * from zone0000tf;(begin a job)
File Format
TextFile SequenceFIle RCFFile
Data type Text Only Text/Binary Text/Binary
Internal Storage Order Row-based Row-based Column-based
Compression File Based Block Based Block Based
Splitable YES YES YES
Splitable After Compression No YES YES
源数据放在test1表中,大小为26413896039 Byte。
创建sequencefile压缩表test2,使用insert overwrite table test2 select …语句将test1数据导入test2,设置配置项。
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
set io.seqfile.compression.type=BLOCK;
set io.compression.codecs=com.hadoop.compression.lzo.LzoCodec;
导入耗时:98.528s。另压缩类型使用默认的record,耗时为418.936s。
创建rcfile 表test3,同样方式导入test3。
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;
set io.compression.codecs=com.hadoop.compression.lzo.LzoCodec;
导入耗时 253.876s。
以下为其他统计数据对比,如表3-2所示。
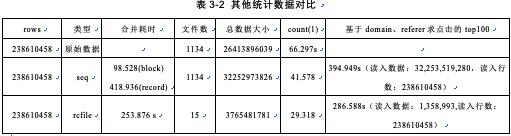
因为原始数据中均是小文件,所以合并后文件数大量减少,但是Hive实现的seqfile 处理竟然还是原来的数目。rcfile 使用lzo 压缩效果明显,7倍的压缩比率。查询数据中读入数据,因为这里这涉及小部分数据,所以rcfile的表读入数据仅是seqfile的4%而读入行数一致。
SequeceFile是Hadoop API提供的一种二进制文件支持。这种二进制文件直接将<key, value>对序列化到文件中。一般对小文件可以使用这种文件合并,即将文件名作为key,文件内容作为value序列化到大文件中。这种文件格式有以下好处:
(1)支持压缩,且可定制为基于Record或Block压缩(Block级压缩性能较优)。
(2)本地化任务支持:因为文件可以被切分,因此MapReduce任务时数据的本地化情况应该是非常好的。
(3)难度低:因为是Hadoop框架提供的API,业务逻辑侧的修改比较简单。
坏处是需要一个合并文件的过程,且合并后的文件将不方便查看。
SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件,它可以在map/reduce过程中的input/output 的format时被使用。在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。
SequenceFile分别提供了读、写、排序的操作类。
SequenceFile的操作中有三种处理方式:
(1)不压缩数据直接存储。 //enum.NONE
(2)压缩value值不压缩key值存储的存储方式。//enum.RECORD
(3)key/value值都以压缩的方式存储。//enum.BLOCK
工作中用到了RcFile来存储和读取RcFile格式的文件,并记录下来。
RcFile是FaceBook开发的一个集行存储和列存储的优点于一身,压缩比更高,读取列更快,它在MapReduce环境中大规模数据处理中扮演着重要的角色。关于读取RcFile格式文件的操作,下面是一个简单的例子,
Job job = new Job();
job.setJarByClass(类.class);
//设定输入文件为RcFile格式
job.setInputFormatClass(RCFileInputFormat.class);
//普通输出
job.setOutputFormatClass(TextOutputFormat.class);
//设置输入路径
RCFileInputFormat.addInputPath(job,new Path(srcpath));
//MultipleInputs.addInputPath(job,new Path(srcpath),RCFileInputFormat.class);
//输出
TextOutputFormat.setOutputPath(job,new Path(respath));
//输出key格式
job.setOutputKeyClass(Text.class)
//输出value格式
job.setOutputValueClass(NullWritable.class);
//设置mapper类
job.setMapperClass(ReadTestMapper.class);
code=(job.waitForCompletion(true))?0:1;
//mapper类
public class ReadTestMapper extends Mapper<LongWritable, BytestRefArrayWritable,
Text,NullWritable>{
Protected void map(LongWritable key,BytestRefArrayWritable value,Context context)throws IOException,InterruptedException{
Text txt = new Text();
StringBuffer sb = new StringBuffer();
for(int i=0;i<value.size();i++){
BytesRefWritable v = value.get(i);
txt.set(v.getData(),v.getStart(),v.getLength());
if(i==value.size()-1){
sb.append(txt.toString());
}else{
sb.append(txt.toString()+”\t”);
}
}
Context.write(new Text(sb.toString()),NullWritable.get());
}
定义job信息之后,第二步定义ReadTestMapper类,该类继承mapper父类,接下来按照具体需求实现map方法,具体实现代码如下,
public class ReadTestMapper extends Mapper<LongWritable, BytestRefArrayWritable, Text,NullWritable>{
Protected void map(LongWritable key,BytestRefArrayWritable value,Context context)throws IOException,InterruptedException{
String line = value.toString();
String day = context.getConfiguration().get(“date”);
if(!Line.equals(“”)){
String[] lines = line.split(“”,-1);
if(lines.length>3){
String time_temp = lines[1];
String times = timeStampDate(time_temp);
String d = times.substring(0,10);
if(day.equals(d)){
byte[][] record = {lines[0].getBytes(“UTF-8”,lines[1].getBytes (“UTF-8”), lines[2].getBytes(“UTF-8”),lines[3].getBytes(“UTF-8”)};
BytesRefArrayWritable bytes = new BytesRefArrayWritable(record.length);
for(int i=0;i<record.length;i++){
BytesRefWritable cu = new BytesRefWritable(record[i],0,record[i]. length);
bytes.set(i,cu);
}
context.write(key,bytes);
}
}
}
SequenceFile提供了若干Writer的构造静态获取。
//SequenceFile.createWriter();
SequenceFile.Reader使用了桥接模式,可以读取SequenceFile.Writer中的任何方式的压缩数据。
三种不同的压缩方式是共用一个数据头,流方式的读取会先读取头字节以判断是哪种方式的压缩,然后根据压缩方式去解压缩并反序列化字节流数据,得到可识别的数据。
流的存储头字节格式为,
Header:
*字节头"SEQ", 后跟一字节表示版本"SEQ4","SEQ6".
*keyClass name
*valueClass name
*compression boolean型的存储标示压缩值是否转变为keys/values值了
*blockcompression boolean型的存储标示是否全压缩的方式转变为keys/values值了
*compressor 压缩处理的类型,比如用Gzip压缩的Hadoop提供的是GzipCodec
所有的String类型的写操作被封装为Hadoop的IO API,Text类型writeString()搞定。
未压缩的和只压缩values值的方式的字节流头部是类似的
*Header
*RecordLength记录长度
*key Length key值长度
*key 值
*是否压缩标志 boolean
*values
以上是关于Hive的数据格式的介绍,以及举了一个简单的例子来方便我们更好地理解Hive的数据类型以及数据格式。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









