




 本文介绍了如何在 pandas 的 Series 和 DataFrame 中进行索引切片操作,特别是针对 DataFrame 中选取连续多列的方法,强调了使用高级索引来实现这一功能。
本文介绍了如何在 pandas 的 Series 和 DataFrame 中进行索引切片操作,特别是针对 DataFrame 中选取连续多列的方法,强调了使用高级索引来实现这一功能。
pandas 索引切片
Series
ser1=pd.Series(range(10,15),index=list('ABCDE'))
print(ser1)
普通索引
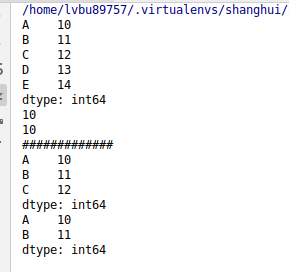
print(ser1['A'])
print(ser1[0])
print('#############')
注意通过自定义索引的左闭右闭的,用默认索引(下标)是左闭右开的
print(ser1['A':'C'])
print(ser1[0:2])
print()
print('################')
不连续索引
print(ser1[['A','C','E']])
print(ser1[[0,2,3]])
print('###############')
条件索引
print(ser1[(ser1>12) & (ser1<15)])
print()
print(ser1[(ser1<12) | (ser1>15)])
print()
print(ser1[ser1!=13])
print()
print(ser1[~(ser1==13)])
print()
print('###############')
print()
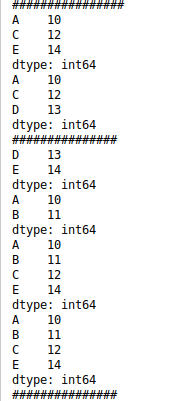
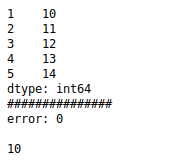
ser2=pd.Series(range(10,15),index=range(1,6))
print(ser2)
print('###############')
这样定义索引无法取到下标0
try:
print(ser2[0])
except Exception as e:
print('error:',e)
print()
print(ser2[1])
dataFrame
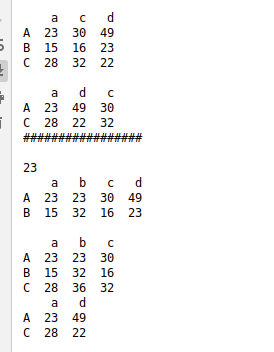
注意:默认不能直接和之前一样取连续多列,要使用高级索引实现
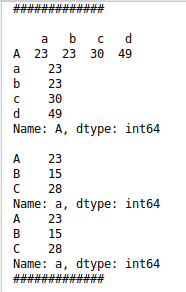
df1=pd.DataFrame(np.random.randint(10,50,(3,4)),index=list('ABC'),columns=list('abcd'))
普通索引
print(df1)
print()
这里取到的是一个series对象
print(df1['a'])
print(df1['a'].values)
print()
用行列索引取元素
print(df1['a']['B'])
print(df1['a'][1])
print()
取不连续多列
print(df1[['a','c']])
print()
取单行,注意这个方法取出的是一个DataFrame对象
print(df1['A':'A'])
print()
取连续多行
print(df1['A':'C'])
print('############')
print()
高级索引,这里是Series的例子
ser1=pd.Series(range(10,15),index=list('ABCDE'))
print(ser1.loc['B':'D'])
print(ser1.loc[['B','D']])
print('#############')
print()
dataFrame index参数高级索引
print(df1['A':'A'])
print(df1.loc['A'])
print()
取一列数据
print(df1['a'])
print(df1.loc[:,'a'])
print('#############')
print()
取连续多行
print(df1['A':'C'])
print(df1.loc['A':'C'])
print()
取连续多列
print(df1.loc[:,'a':'c'])
print()
取指定连续行列
print(df1.loc['B':'C','c':'d'])
print()
取不连续多行
print(df1.loc[['A','C']])
print()
取不连续多列
print(df1.loc[:,['a','c','d']])
print()
取指定行列(可指定顺序)
print(df1.loc[['A','C'],['a','d','c']])
print('#################')
print()
下标高级索引
print(df1.iloc[0,0])
print(df1.iloc[0:2])
print()
print(df1.iloc[:,0:3])
print(df1.iloc[[0,2],[0,3]])
print('##############')
print()
df1=pd.DataFrame(np.random.randint(10,20,(3,4)),index=list('ABC'),columns=list('abcd'))
print(df1)
print()
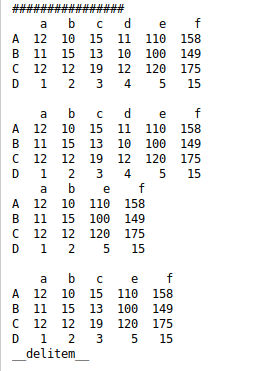
添加列
df1['e']=df1['d']*10
print(df1)
print()
添加行
df1.loc['D']=[1,2,3,4,5]
print(df1)
print()
添加列
df1['f']=df1['a']+df1['b']+df1['c']+df1['d']+df1['e']
print(df1)
print()
print('################')
print(df1)
print()
# 删除指定列
df2=df1.drop(['c','d'],axis=1)
print(df1)
print(df2)
print()
删除指定列
del df1['d']
print(df1)
#不能删除指定行
try:
del df1.loc['A']
except Exception as e:
print(e)
print()
print('#####################')





















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









