






 本文深入解析Go语言中Goroutine的创建过程,从`newproc`和`newproc1`函数出发,详细阐述如何为`runtime.main`创建一个新的执行上下文,包括参数传递、栈空间分配和调度准备。通过源码分析,展示了从创建到加入运行队列的完整流程。
本文深入解析Go语言中Goroutine的创建过程,从`newproc`和`newproc1`函数出发,详细阐述如何为`runtime.main`创建一个新的执行上下文,包括参数传递、栈空间分配和调度准备。通过源码分析,展示了从创建到加入运行队列的完整流程。
还是上篇文章的例子:
package mainimport "fmt"func main() {fmt.Println("Hello World!")}
接着上篇文章来聊。
schedinit完成调度系统初始化之后,返回到rt0_go中开始调用newproc(),创建一个新的goroutine用于执行mainPC所对应的runtime.main()。
来看runtime/asm_amd64.s文件197行代码:
# create a new goroutine to start programMOVQ $runtime·mainPC(SB), AX # entry,mainPC是runtime.main# newproc的第二个参数入栈,也就是新的goroutine需要执行的函数PUSHQ AX # AX = &funcval{runtime·main},# newproc的第一个参数入栈,该参数表示runtime.main函数需要的参数大小,因为runtime.main没有参数,所以这里是0PUSHQ $0CALL runtime·newproc(SB) # 创建main goroutinePOPQ AXPOPQ AX# start this MCALL runtime·mstart(SB) # 主线程进入调度循环,运行刚刚创建的goroutine# 上面的mstart永远不应该返回的,如果返回了,一定是代码逻辑有问题,直接abortCALL runtime·abort(SB)// mstart should never returnRETDATA runtime·mainPC+0(SB)/8,$runtime·main(SB)GLOB Lruntime·mainPC(SB),RODATA,$8
runtime.main()最后调main.main(),所以分析runtime.main()之前先看newproc()。
newproc用于创建新的goroutine,有两个参数,新创建出来的goroutine会先从第二个参数fn开始执行,fn可能也会有参数,而newproc第一个参数就是fn的参数,以字节为单位。
来看如下Go代码:
func start(a, b, c int64) {......}func main() {go start(1, 2, 3)}
编译器编译上述代码时,会将其调整为对newproc的调用,编译之后的代码逻辑基本等同于如下代码案例:
func main() {push 0x3push 0x2push 0x1runtime.newproc(24, start)}
编译器编译时会首先用几条指令将start需用到的三个参数压栈,然后调用newproc。
因为start的三个int64类型参数共占24字节,所以传递给newproc的第一个参数是24,表示start需要24字节大小的参数。
那为什么需要传递fn的参数大小给newproc呢?
这是因为newproc将创建一个新的goroutine来执行fn,而这个新创建的goroutine与当前的goroutine使用的不是一个栈,所以就需要在创建新的goroutine时就将fn需要用到的参数从当前goroutine栈上拷贝到新的goroutine所使用的栈上,如此才能让其开始执行,而newproc本身并不知道需要拷贝多少数据到新创建的goroutine的栈上,所以需要使用参数的方式来指定拷贝多少数据。
再来继续分析newproc,它其实是newproc1的一个包装。
来看runtime/proc.go文件第3232行详细代码:
// Create a new g running fn with siz bytes of arguments.// Put it on the queue of g's waiting to run.// The compiler turns a go statement into a call to this.// Cannot split the stack because it assumes that the arguments// are available sequentially after &fn; they would not be// copied if a stack split occurred.//go:nosplitfunc newproc(siz int32, fn *funcval) {//函数调用参数入栈顺序是从右向左,而且栈是从高地址向低地址增长的//注意:argp指向fn函数的第一个参数,而不是newproc函数的参数//参数fn在栈上的地址+8的位置存放的是fn函数的第一个参数argp := add(unsafe.Pointer(&fn), sys.PtrSize)gp := getg() //获取正在运行的g,初始化时是m0.g0//getcallerpc()返回一个地址,也就是调用newproc时由call指令压栈的函数返回地址,//对于我们现在这个场景来说,pc就是CALLruntime·newproc(SB)指令后面的POPQ AX这条指令的地址pc := getcallerpc()//systemstack的作用是切换到g0栈执行作为参数的函数//我们这个场景现在本身就在g0栈,因此什么也不做,直接调用作为参数的函数systemstack(func() {newproc1(fn, (*uint8)(argp), siz, gp, pc)})}
通过上述代码可以看到,这里最重要的准备工作有两个,其一就是获取fn第一个参数的地址,也就是代码中的argp,另一个就是使用systemstack切换到g0栈,当然了,本文的初始化的场景本就在g0,所以不需要切换,但这个函数是通用的,在用户goroutine中,也会再次创建goroutine,此时就需要进行栈的切换。
newproc1第一个参数fn是新创建goroutine需执行的函数,fn的结构体类型为funcval,其定义如下:
type funcval struct {fn uintptr// variable-size, fn-specific data here}
newproc1第二个参数argp是fn第一个参数的地址,第三个参数为fn的参数以字节为单位的大小,要了解的是newproc1是在g0栈上运行的,来分段看下源码。
首先是runtime/proc.go文件第3248行:
// Create a new g running fn with narg bytes of arguments starting// at argp. callerpc is the address of the go statement that created// this. The new g is put on the queue of g's waiting to run.func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {//因为已经切换到g0栈,所以无论什么场景都有 _g_ = g0,当然这个g0是指当前工作线程的g0//对于我们这个场景来说,当前工作线程是主线程,所以这里的g0 = m0.g0_g_ := getg()......_p_ := _g_.m.p.ptr() //初始化时_p_ = g0.m.p,从前面的分析可以知道其实就是allp[0]newg := gfget(_p_) //从p的本地缓冲里获取一个没有使用的g,初始化时没有,返回nilif newg == nil {//new一个g结构体对象,然后从堆上为其分配栈,并设置g的stack成员和两个stackgard成员newg = malg(_StackMin)casgstatus(newg, _Gidle, _Gdead) //初始化g的状态为_Gdead//放入全局变量allgs切片中allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.}......//调整g的栈顶置针,无需关注totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frametotalSize += -totalSize & (sys.SpAlign - 1) // align to spAlignsp := newg.stack.hi - totalSizespArg := sp//......if narg > 0 {//把参数从执行newproc函数的栈(初始化时是g0栈)拷贝到新g的栈memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))// ......}
上述代码主要是在堆上分配一个g结构体对象,并为这个newg分配一个2048字节大小的栈,并设置好newg的stack成员,然后将newg需要执行的函数的参数从执行newproc的栈(初始化时g0栈)上拷贝到newg的栈,此后newg状态如下所示:
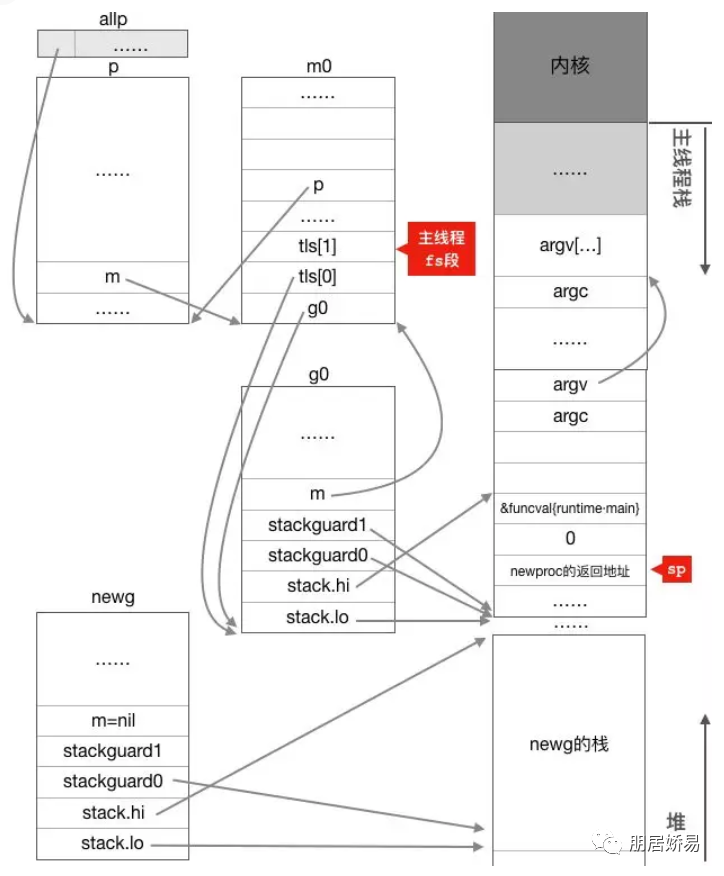
可以看到此时程序中多了个称为newg的g结构体对象,其以获取到从堆上分配而来的2K大小的栈空间,newg的stack.hi和stack.lo分别指向其栈空间的起始地址。
来继续看newproc1的源码,位置是runtime/proc.go文件3314行:
//把newg.sched结构体成员的所有成员设置为0memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))//设置newg的sched成员,调度器需要依靠这些字段才能把goroutine调度到CPU上运行。newg.sched.sp = sp //newg的栈顶newg.stktopsp = sp//newg.sched.pc表示当newg被调度起来运行时从这个地址开始执行指令//把pc设置成了goexit这个函数偏移1(sys.PCQuantum等于1)的位置,//至于为什么要这么做需要等到分析完gostartcallfn函数才知道newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same functionnewg.sched.g = guintptr(unsafe.Pointer(newg))gostartcallfn(&newg.sched, fn) //调整sched成员和newg的栈
上述代码首先对newg的sched进行初始化,其包含了调度器代码调度goroutine到CPU运行时所必须用到的一些信息,其中sched的sp成员表示newg被调度起来运行时应使用的栈的栈顶,sched的pc成员表示newg被调度起来运行时从此地址开始执行指令。
来看下gostartcallfn源码来聊聊为什么上述代码中new.sched.pc被设置成goexit的第二条指令,而不是fn.fn?
gostartcallfn源码如下:
// adjust Gobuf as if it executed a call to fn// and then did an immediate gosave.func gostartcallfn(gobuf *gobuf, fv *funcval) {var fn unsafe.Pointerif fv != nil {fn = unsafe.Pointer(fv.fn) //fn: gorotine的入口地址,初始化时对应的是runtime.main} else {fn = unsafe.Pointer(funcPC(nilfunc))}gostartcall(gobuf, fn, unsafe.Pointer(fv))}
gostartcallfn先从fv中提取函数地址(初始化时runtime.main),然后就继续执行gostartcall,来看下gostartcall的源码:
// adjust Gobuf as if it executed a call to fn with context ctxt// and then did an immediate gosave.func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {sp := buf.sp //newg的栈顶,目前newg栈上只有fn函数的参数,sp指向的是fn的第一参数if sys.RegSize > sys.PtrSize {sp -= sys.PtrSize*(*uintptr)(unsafe.Pointer(sp)) = 0}sp -= sys.PtrSize //为返回地址预留空间,//这里在伪装fn是被goexit函数调用的,使得fn执行完后返回到goexit继续执行,从而完成清理工作*(*uintptr)(unsafe.Pointer(sp)) = buf.pc //在栈上放入goexit+1的地址buf.sp = sp //重新设置newg的栈顶寄存器//这里才真正让newg的ip寄存器指向fn函数,注意,这里只是在设置newg的一些信息,newg还未执行,//等到newg被调度起来运行时,调度器会把buf.pc放入cpu的IP寄存器,//从而使newg得以在cpu上真正的运行起来buf.pc = uintptr(fn)buf.ctxt = ctxt}
上述代码主要作用如下:
-
调整newg栈空间,将goexit第二条指令入栈,伪造成goexit调用了fn,从而使fn执行完成后调用ret指令返回到goexit继续执行完成最后的清理工作。
-
重新设置new.buf.pc为需执行函数的地址,也就是fn,在本文中就是runtime.main函数的地址。
调整完成newg的栈和sched之后,来接着看newproc1,源码如下:
newg.gopc = callerpc //主要用于tracebacknewg.ancestors = saveAncestors(callergp)//设置newg的startpc为fn.fn,该成员主要用于函数调用栈的traceback和栈收缩//newg真正从哪里开始执行并不依赖于这个成员,而是sched.pcnewg.startpc = fn.fn......//设置g的状态为_Grunnable,表示这个g代表的goroutine可以运行了casgstatus(newg, _Gdead, _Grunnable)......//把newg放入_p_的运行队列,初始化的时候一定是p的本地运行队列,其它时候可能因为本地队列满了而放入全局队列runqput(_p_, newg, true)......}
上述代码比较直观,先是设置了几个与调度无关的成员变量,然后修改newg状态为_Grunnable并将其放入运行队列,至此程序上真正意义的第一个goroutine构建完成。
此时newg也就是main goroutine状态如下所示:
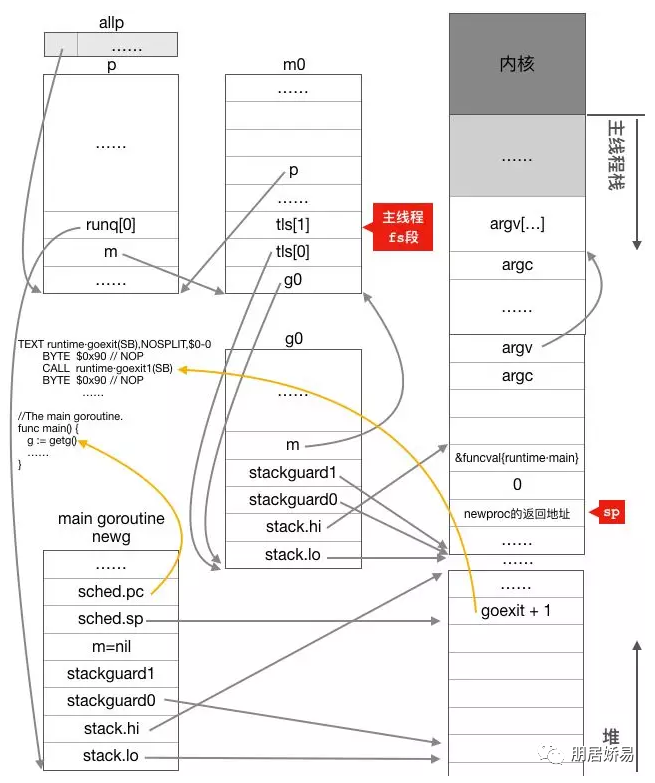
说明如下:
-
main goroutine对应的newg的sched已初始化完成,上图只显示pc(指向runtime.main的第一条指令)和sp(指向newg的栈顶内存单元),sp指向的内存单元保存了runtime.main执行完成后的返回地址,也就是runtime.goexit的第二条指令,在预期中,runtime.main执行完毕后就回去执行runtime.exit的CALL runtime.goexit1(SB)指令。
-
newg已放入当前主线程绑定的p的本地运行队列,因为它是第一个goroutine,所以被放在本地运行队列的头部。
-
newg的m为nil,因为它还没被调度起来运行,也还未跟任何m进行绑定。
本文主要聊的就是程序第一个goroutine也就是main goroutine的创建,下文再来聊聊它是怎么被主工作线程调度到CPU去执行的。
以上仅为个人观点,不一定准确,能帮到各位那是最好的。
好啦,到这里本文就结束了,喜欢的话就来个三连击吧。
扫码关注公众号,获取更多优质内容。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











