



muduo 与 libevent2 吞吐量对比
2010年09月05日 18:43:00 陈硕 阅读数 28577
libevent 是一款非常好用的 C 语言网络库,它也采用 Reactor 模型,正好可以与 muduo 做一对比。
本文用 ping pong 测试来对比 muduo 和 libevent2 的吞吐量,测试结果表明 muduo 吞吐量平均比 libevent2 高 18% 以上,个别情况达到 70%。
测试对象
- libevent 2.0.6-rc (http://monkey.org/~provos/libevent-2.0.6-rc.tar.gz)
- muduo 0.1.1 (http://muduo.googlecode.com/files/muduo-0.1.1-alpha.tar.gz) SHA1 Checksum: a446ea8a22915f439063d2bc52eb2dc4b9caf92d
测试环境与测试方法
测试环境与前文《muduo 与 boost asio 吞吐量对比》相同。
我自己编写了 libevent2 的 ping pong 测试代码,地址在 http://github.com/chenshuo/recipes/tree/master/pingpong/libevent/。由于这个测试代码没有使用多线程,所以本次测试只对比单线程下的性能。
测试内容为:客户端与服务器运行在同一台机器,均为单线程,测试并发连接数为 1/10/100/1000/10000 时的吞吐量。
在同一台机器测试吞吐量的原因:
- 现在的 CPU 很快,即便是单线程单 TCP 连接也能把 Gigabit 以太网的带宽跑满。如果用两台机器,所有的吞吐量测试结果都将是 100 MiB/s,失去了对比的意义。(或许可以对比哪个库占的 CPU 少。)
- 在同一台机器上测试,可以在 CPU 资源相同的情况下,单纯对比网络库的效率。也就是说单线程下,服务端和客户端各占满 1 个 CPU,比较哪个库的吞吐量高。
测试结果
单线程吞吐量测试,数字越大越好:

以上结果让人大跌眼镜,muduo 居然比 libevent 快 70%!跟踪 libevent2 的源代码发现,它每次最多从 socket 读取 4096 字节的数据 (证据在 buffer.c 的 evbuffer_read() 函数),怪不得吞吐量比 muduo 小很多。因为在这一测试中,muduo 每次读取 16384 字节,系统调用的性价比较高。
buffer.c:#define EVBUFFER_MAX_READ 4096
为了公平起见,我再测了一次,这回两个库都发送 4096 字节的消息。

测试结果表明 muduo 吞吐量平均比 libevent2 高 18% 以上。
讨论
由于 libevent2 每次最多从网络读取 4096 字节,大大限制了它的吞吐量。
================================================================================================
================================================================================================================================================================================================
Mbit/s的意思是每秒中传输10^6 bit的数据,也写成Mbps
MB/s的意思是每秒中传输10^6 byte的数据
MiB/s的意思是每秒中传输2^20 byte的数据,不太常用
PS:所以如果一个运营商声称自己的传输带宽是1 Mbps
按照MB/s来算的话,它只有0.125 MB/s (megabyte per second);
按照MiB/s来算的话,它更是只有0.1192 MiB/s (mebibyte per second)
具体的换算公式是:
Mbit/s / 8 = MB/s
因为:
Mbit/s = 10^6 bit/s
MiB/s = 2^20 * 8 bit/s
所以:
Mbit/s = MiB/s * 0.1192
100 MiB * 0.1=10 Mbit/ s = 1MB/s = 10^6 byte/s
================================================================================================================================================================================================================================================================================================
================================================================================================================================================================================================================================================================================================
6.5.2 击鼓传花:对比muduo 与libevent2 的事件处理效率
《Linux多线程服务端编程:使用muduo C++网络库》本书重点讲解多线程网络服务器的一种IO 模型,即one loop per thread。本节为大家介绍击鼓传花:对比muduo 与libevent2 的事件处理效率。
作者:陈硕来源:电子工业出版社|2013-01-23 15:07
收藏
分享
6.5.2 击鼓传花:对比muduo 与libevent2 的事件处理效率
前面我们比较了muduo 和libevent2 的吞吐量, 得到的结论是muduo 比libevent2 快18%. 有人会说,libevent2 并不是为高吞吐量的应用场景而设计的,这样的比较不公平,胜之不武。为了公平起见,这回我们用libevent2 自带的性能测试程序(击鼓传花)来对比muduo 和libevent2 在高并发情况下的IO 事件处理效率。
测试用的软硬件环境与前一小节相同,另外我还在自己的DELL E6400 笔记本电脑上运行了测试,结果也附在后面。
测试的场景是:有1000 个人围成一圈,玩击鼓传花的游戏,一开始第1 个人手里有花,他把花传给右手边的人,那个人再继续把花传给右手边的人,当花转手100次之后游戏停止,记录从开始到结束的时间。
用程序表达是,有1000 个网络连接(socketpair(2) 或pipe(2)),数据在这些连接中顺次传递,一开始往第1 个连接里写1 个字节,然后从这个连接的另一头读出这1 个字节,再写入第2 个连接,然后读出来继续写到第3 个连接,直到一共写了100 次之后程序停止,记录所用的时间。
以上是只有一个活动连接的场景,我们实际测试的是100 个或1000 个活动连接(即100 朵花或1000 朵花,均匀分散在人群手中),而连接总数(即并发数)从100 ~100 000(10 万)。注意每个连接是两个文件描述符,为了运行测试,需要调高每个进程能打开的文件数,比如设为256 000。
libevent2 的测试代码位于test/bench.c,我修复了2.0.6-rc 版里的一个小bug。修正后的代码见已经提交给libevent2 作者,现在下载的最新版本是正确的。
muduo 的测试代码位于examples/pingpong/bench.cc。
测试结果与讨论
第一轮,分别用100 个活动连接和1000 个活动连接,无超时,读写100 次,测试一次游戏的总时间(包含初始化)和事件处理的时间(不包含注册event watcher)随连接数(并发数)变化的情况。具体解释见libev 的性能测试文档19,不同之处在于我们不比较timer event 的性能,只比较IO event 的性能。对每个并发数,程序循环25 次,刨去第一次的热身数据,后24 次算平均值。测试用的脚本20 是libev 的作者Marc Lehmann 写的,我略做改用,用于测试muduo 和libevent2。
第一轮的结果(见图6-6),请先只看“+”线(实线)和“”线(粗虚线)。“”线是libevent2 用的时间,“+”线是muduo 用的时间。数字越小越好。注意这个图的横坐标是对数的,每一个数量级的取值点为1,2,3,4,5,6,7.5,10。
total time per iteration(迭代) 100 activive clients
file descriptor 文件描述符
1000 active clients
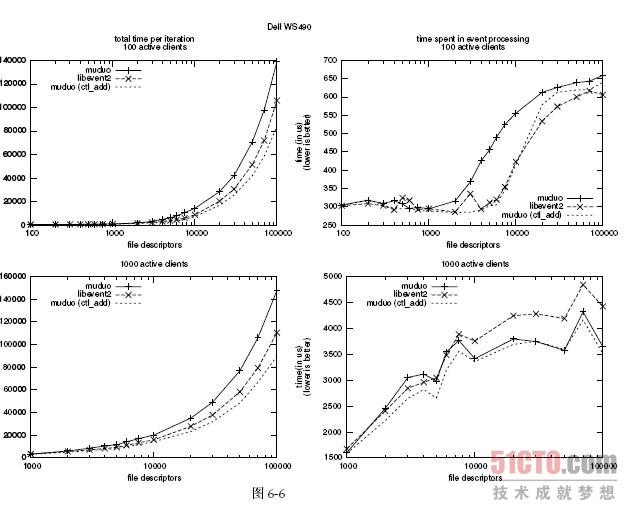 |
从两条线的对比可以看出:
1. libevent2 在初始化event watcher 方面比muduo 快20% (左边的两个图)。
2. 在事件处理方面(右边的两个图)
a. 在100 个活动连接的情况下,
当总连接数(并发数)小于1000 或大于30 000 时,二者性能差不多;
当总连接数大于1000 或小于30 000 时,libevent2 明显领先。
b. 在1000 个活动连接的情况下,
当并发数小于10 000 时,libevent2 和muduo 得分接近;
当并发数大于10 000 时,muduo 明显占优。
这里有两个问题值得探讨:
1. 为什么muduo 花在初始化上的时间比较多?
2. 为什么在一些情况下它比libevent2 慢很多?
我仔细分析了其中的原因,并参考了libev 的作者Marc Lehmann 的观点21,结论是:在第一轮初始化时,libevent2 和muduo 都是用epoll_ctl(fd, EPOLL_CTL_ADD, ...) 来添加文件描述符的event watcher。不同之处在于,在后面24 轮中,muduo 使用了epoll_ctl(fd, EPOLL_CTL_MOD, ...) 来更新已有的event watcher;然而libevent2 继续调用epoll_ctl(fd, EPOLL_CTL_ADD, ...) 来重复添加fd,并忽略返回的错误码EEXIST (File exists)。在这种重复添加的情况下,EPOLL_CTL_ADD将会快速地返回错误,而EPOLL_CTL_MOD 会做更多的工作,花的时间也更长。于是libevent2 捡了个便宜。
为了验证这个结论,我改动了muduo,让它每次都用EPOLL_CTL_ADD 方式初始化和更新event watcher,并忽略返回的错误。
第二轮测试结果见图6-6 的细虚线,可见改动之后的muduo 的初始化性能比libevent2 更好,事件处理的耗时也有所降低(我推测是kernel 内部的原因)。
这个改动只是为了验证想法,我并没有把它放到muduo 最终的代码中去,这或许可以留作日后优化的余地。(具体的改动是muduo/net/poller/EPollPoller.cc 第138 行和173 行,读者可自行验证。)
同样的测试在双核笔记本电脑上运行了一次,结果如图6-7 所示。(我的笔记本电脑的CPU 主频是2.4 GHz,高于台式机的1.86 GHz,所以用时较少。)
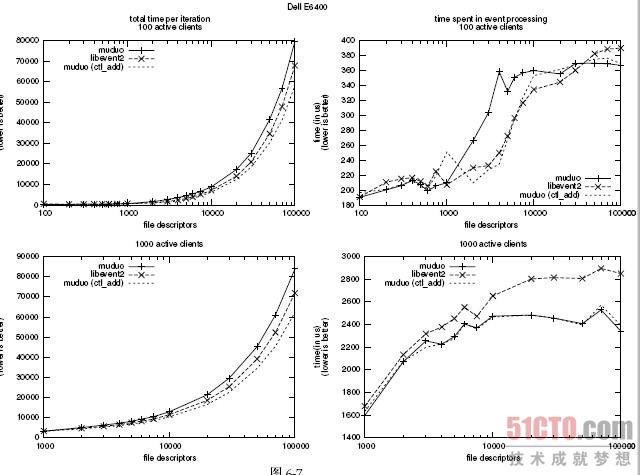 |
结论:在事件处理效率方面,muduo 与libevent2 总体比较接近,各擅胜场。在并发量特别大的情况下(大于10 000),muduo 略微占优。
================================================================================================================================================================================================================================================================================================
=

















 173万+
173万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









