



 本文通过示例代码解释了在多线程环境下,使用i++操作可能导致的结果不准确问题。原因是CPU缓存的非同步写回主内存,导致并发更新时的数据竞争。线程安全问题在并发编程中至关重要,理解这一概念有助于避免并发错误。
本文通过示例代码解释了在多线程环境下,使用i++操作可能导致的结果不准确问题。原因是CPU缓存的非同步写回主内存,导致并发更新时的数据竞争。线程安全问题在并发编程中至关重要,理解这一概念有助于避免并发错误。
江湖人都在传说,i++操作在多线程并发执行场景下不安全!!!Why?
一、示例
那么我们来看如下代码:
int i = 0;
int num = 10000;
public void addCount(){
List<Thread> list = new ArrayList<Thread>();
for (int j = 0; j < num; j++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
i ++;
}
});
list.add(t);
}
for (Thread t:list) {
t.start();
}
for (Thread t:list) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("执行结果:i="+i);
}
执行结果:i=9998
通常情况,结果 i 小于10000。
二、原因分析
首先,我们要理解 i++的真实语法~
get ii = i + 1set i
没错!!!这才是CPU在执行 i++时的真实语法结构!
然后,我们来看一张丑图
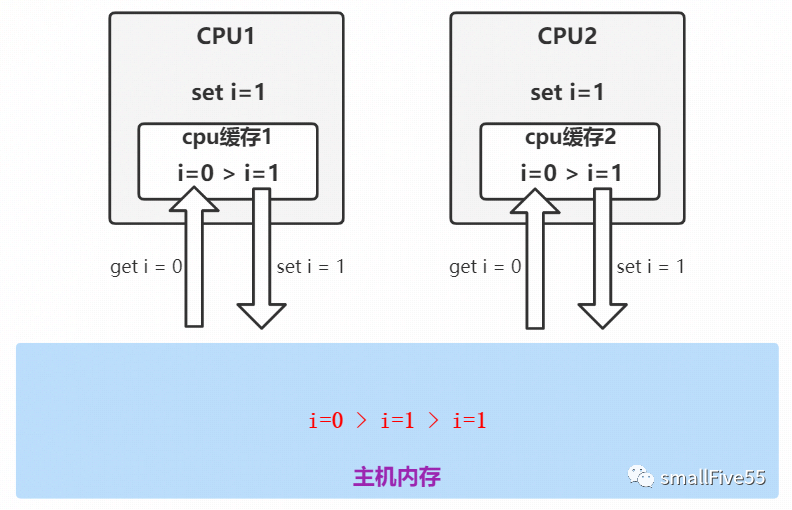
我们知道,在CPU内核中,存在一块高速缓冲区,简单理解为CPU缓存。多核CPU中每一个内核都拥有自己独立的缓冲区。
破案:当多线程并发执行 i++时,如图:两个CPU分别执行两个线程,CPU1与CPU2并行执行时,同时从主内存获取到 i=0,两边同时进行+1操作并写回,导致最终结果 i 等于1而不是2。
如 i++语法所示,只要在线程1执行第三步前,其他线程通过另外的CPU从主内存获取的 i 一定是0,那么便会导致错误。
三、最后
实际情况,就算线程1执行完第三步,其他线程通过另外的CPU从主内存也不一定能取得最新的 i 值。
因为,CPU缓存并不是同步实时写回主内存的!
------------------------------------
若文中有任何错误,烦请指正~
如有疑惑,也欢迎一起探讨!


















 171万+
171万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









