







 这篇博客介绍了如何在Python环境下安装并配置tesseract进行身份证识别。首先通过PyCharm安装pillow和pytesseract,然后下载tesseract-OCR并设置环境变量。在遇到PyCharm中pytesseract模块路径问题时,需要手动配置pytesseract.py的tesseract_cmd路径。虽然目前只能智能识别英文和数字,作者计划未来更新身份证号码的动态识别源码。
这篇博客介绍了如何在Python环境下安装并配置tesseract进行身份证识别。首先通过PyCharm安装pillow和pytesseract,然后下载tesseract-OCR并设置环境变量。在遇到PyCharm中pytesseract模块路径问题时,需要手动配置pytesseract.py的tesseract_cmd路径。虽然目前只能智能识别英文和数字,作者计划未来更新身份证号码的动态识别源码。
Python上安装及使用tesseract 用于身份证识别
前期准备
下载 pillow和pytesseract直接在 pycharm里面下载即可。
接下来
tesseract-ORT下载,点击这里下载 tesseract-ocr-w64-setup-v4.1.0.20190314.exe
安装的默认目录是C:\Program Files\Tesseract-OCR

紧接着
我们要将其目录添加到系统的环境变量里面
在这里我们做两个事情
第一、添加变量和值 TESSDATA_PREFIX 值里面写tessdata位置

第二、添加路径PATH
这里讲路径写到tesseract-ORT就好

到这里我们cmd里面就可以使用tesseract了,但是在pycharm里面还不行
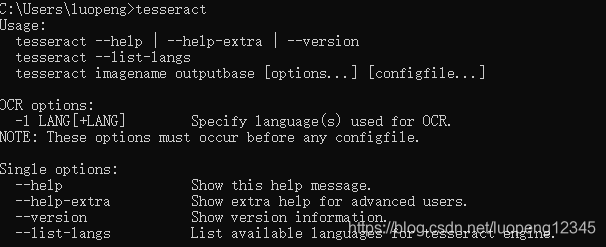
pycharm里面这样显示,这是pycharm里面pytesseract模块路径没有配置的问题
Error opening data file ….
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your “tessdata” directory.
Failed loading language ‘eng’
Teseract couldn’t load any languages!
最后配置pycharm里面的路径
打开 pytesseract.py
这个py在你python环境下面
我的路径是这样的
tesseract_cmd路径修改一下
这里的路径配置成你之前安装tesseract-ORT的路径下的tesseract.exe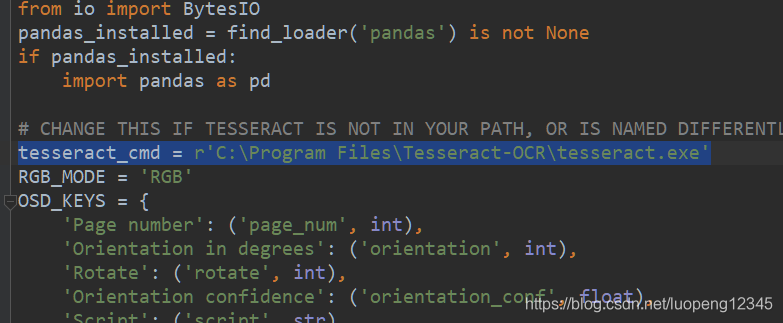
这样就完成了
代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
import pytesseract
from PIL import Image
text =pytesseract.image_to_string(Image.open("timg.jpg"))
print(text)
timg.jpg

识别结果智能识别英文和数字,汉字部分是乱码,这是因为pytesseract中没有汉字识别的包
Pe A REF
©) 32 = Dollor Guo
es Fe ik i
ii | 2014 # 018 178
oO FRI PLU anh PAS
AES SIS 0755955089551195588


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









