



久违了朋友们。是的,我诈尸了,你没看错。已两年多没有登陆这个公众号,再打开真的回忆满满,不知不觉甚至热泪盈眶。在这期间,我的生活发生天翻地覆变化,对人生有了非常非常多新的认知,不断的去打断迭代自己。不论幸福的还是痛苦的,未来都希望有机会可以一一分享。很感激,如今还能收到看到这篇文章的你们,让我觉得始终可以有人在听我说话,看我文字,来日方长。
话不多说,今天分享我已经鸽子了很久很久的一篇文章。
本文将回答的问题:
实验背后的统计学原理是什么?
实验的评估方式是什么?
提升实验灵敏度有哪些方法?

AB实验的本质-假设检验
“这个p值很小说明实验显著了”
“这个实验目前还没置信,再开几天等等”
——以上是我们常见的对于实验结论的表述
但很多同学对于p值的含义及上述表述的严谨与可靠性都存疑。这背后其实涉及到了一套分析统计问题的框架——「假设检验」。
假设检验:假设检验是需要我们回答一个是或否的判断问题时进行判断的过程。假设检验中,存在一个相对保守的选项原假设,并有一套证据力度的评判体系。它通常会有以下一些原则:
需要明确的定性回答:实验组与对照组比,在某个指标比如平均App时长上有没有明显改变,需要给出是或否的定性判断;
奉行保守的无罪推定,即谁主张谁举证:例如目前线上运行的对照组版本没有什么大的问题,因此除非有足够证据证明新策略更好,否则我们不能进行新策略的迭代。这是一个相对保守的选项;
要有一套判断证据强弱的定量标准:我们采用p值来衡量证据的强弱,以p<0.05的阈值标准来评判证据够不够强;
我觉得走这条路是对的(建立原假设),那我们继续在这条路上走,到终点时看是不是走偏了,如果偏得很远那就只能放弃这条路(拒绝原假设);但如果偏差在一个可接受的范围内,那么就暂且在这条路上呆会(不拒绝原假设);
在实际实验中,我们往往倾向于保守态度,即除非有足够多的证据证明实验组比对照组更好,不然我们不会轻易改变现状。因此,我们在心里期望实验组效果更好,但依然会把对照组作为基准,然后通过假设检验的数据去尝试推翻“实验组和对照组没有差异”的基本原假设;
实验评估方式
Significance显著性
假设我们做了实验,对照组指标为0.87%,实验组指标是0.83%,二者有4.6%的相对差异diff,这个diff存在两种可能:
「策略有用」:实验组指标确实比对照组指标低,实验策略有效果;
「策略没用」:策略没有效果,本身指标存在一定波动性所以观测出4.6%的相对差异;
要回答上述问题,就需要通过实验数据告诉我们这4.6%的相对差异应该归因给以上哪种可能性,这个归因的过程就是实验显著性的计算。
显著性我们可以理解为,计算「假设实验没有效果的情况下,diff波动的正常范围的区间是多少」,当实际观测到的组间diff超出这个区间时,我们就可以说观测到的实验diff无法完全用自然波动去解释,有比较大的把握去认为这个diff是实验带来的效果。

统计学中有个概念专门用来描述diff波动的正常区间,那就是95%置信区间。意思是当我们重复这个实验尽可能的多次,有大约95%次实验数据算出的区间都会包含真实的自然波动。从理论出发,推导出数据的diff分布,包括平均值和标准差,从而得出95%的置信区间。当样本足够大时,我们可以近似认为所有人均指标都是正态分布,又因两个独立的正态分布可加,因此差值也会是正态分布;
P-Value
我们需要p值来判断显著性,什么是p值?「p值是一种用于评判证据强弱的标准。」也就是当原假设为真时,所得到的样本观察结果或更极端结果出现的概率。
当我扔100次硬币,60次正、40次负。这时候p-value可以告诉我的是:如果硬币是一枚均匀硬币的话,我至少得到55次正面的概率。(在这儿我们的原假设就是硬币是均匀的、样本观察结果则是55次正面、更极端结果则是
56,57,...100次正面)
【follow-up】那么我们可以计算这样的概率是多大(注:要累加二项式公式)
p-value=C(55,100)(1/2)^55(1/2)^45+.....+C(100,100)*(1/2)^100 (1/2) ^0
如果这个最后计算出来的p-value 小于我们设置的alpha(0.05),那么我们拒绝我们的原假设,得出:硬币不是均匀的。
因此,p值越小,就越说明原假设不对,「当p值小到一定程度,我们就可以果断的拒绝原假设」。
p值的判断逻辑是我们先假设原假设成立,在这个前提下来看我们能够看比当前数据更偏离原假设成立的情况的可能性有多大;
如果这个可能性很小,那么就说明我们的数据对原假设的支持力度很弱,那么我们就倾向于拒绝原假设;
如果这个可能性不足够小,那么我们还是倾向于接受保守的结论,也就是没有足够的证据表明原假设不成立;
为什么常常要求p值<0.05?业界经验。实际上可以根据需要去自行调整显著水平,例如在多指标同时判断时,可以调低显著性水平到0.01以具体问题具体分析;
对应到实验结果评估的部分
实验分析是用样本(小流量)去估计总体(全部流量 和全部我们关心的对象) 的过程,这一过程得到的结果有我们采样随机性的影响
我们需要辨别我们观察到的实验组和对照组指标的差异,是来自于真实的两个总体之间的差异(原假设不成立),还是我们采样随机性带来的(原假设成立)
图示:第一类错误与第二类错误 假设我们只考虑单一指标效果 当且仅当统计显著时进行推全

第一类错误是红色阴影部分,是我们错误的拒绝了原假设——在实验版本没有差异的时候,错误的认为存在真实的差异——‘推全了没有效果的改动’
第二类错误是蓝色阴影部分,是我们错误的没有拒绝原假设——实验版本与对照版本真实存在差异(既然真实存在差异这里需要有一个差异的大小幅度)的时候,我们错误的认为看到的差异是来自于随机采样的误差——‘对有效果的改动没有推全’
哪些因素会影响P值?
为什么实验A指标变动1%就是显著的,但实验B指标同样变动1%却是不显著的?
回答这个问题,我们可以回顾一下统计检验量的构成要素公式:
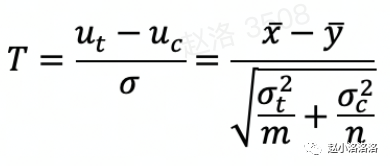
通过上述公式,我们可以知道影响检验统计量值大小的不仅仅是实验组对照组diff,还有方差,而方差又与数据的分布、样本量大小有直接关系。因此,数据具体的分布形态、样本量也会影响着检验统计量,从而影响着p值;

以样本量为例,同样都是1%的提升(实验组对照组diff),也许实验A是100/10000=1%,但实验B是1/100=1%,检验的结果自然就有可能不同。样本量越大,实验评估的灵敏度就会越高,就越容易拒绝原假设;
Power
如下图所示,alpha为第一类错误的概率,beta为第二类错误的概率,则:
Power=1-beta,即‘原假设为假,也正确拒绝了假的原假设的概率’。Power 越大越好,但是通常情况beta越小alpha就会越大,我们需要控制alpha,所以一般我们要求Power>=80%即可;

从power的统计学定义我们就可以知道,这个值我们不可能精确计算,因为我们不会知道原假设事实上的真假,因此power更多作为一条需要满足的前置条件作为输入值。例如我们需要在实验开始前,要求power=80%来计算最小样本量;
MDE
Mininum Detectable Effect,最小可识别变动,MDE常用于评价一个实验的灵敏度。如果一个实验的MDE大于业务预期(例如我们做了一个CGVR策略预期可以降低3%的CGVR,但这个实验的MDE只有5%),就说明当前的实验不够灵敏,难以检测出我们想要辨别的效果。那么就需要相应的放量或者延长实验周期等方式来提高灵敏度。一般认为,MDE越小说明实验灵敏度越高,且实验组相比对照组,只有高于MDE的真实提升才能大概率被当前实验所检测出显著。
【样本与整体】
实验总体是未知的,而样本是从总体中取出的观测对象。我们只能通过已知的样本来推断总体的面貌。因此通过实验数据计算得到的diff提升只是样本均值差,并不等于实验组的真实提升,而t检验就是帮助我们从样本均值差推断真实提升的过程,实际上的推断的对错我们不能知道,我们仅可以通过控制‘犯错概率’来描述推断的客观的准确程度;

实验中使用到MDE的场景有两种:
第一个场景是在实验开始前,MDE作为输入值帮助我们计算所需的样本量;
第二个场景是在实验开始后,逐渐积累了一部分实验数据后,需要把MDE作为输出值,帮助我们评估本次实验的灵敏度;
实验决策流程
需要结合p值和MDE共同决策:

实验灵敏度提升
Trigger
在实验中有时会出现「分流用户和真正被实验作用的用户不一致」的现象,导致实验被稀释渗透率低。
例如,tiktok上线了针对关注页的策略,那么对于一个用户来说,他打开APP就会被分流给既定的对照组还是实验组,但他真正被实验影响是在点击进入到关注页后。如果这个用户没有进入到关注页就关闭了产品,那么他就完全不会被实验策略所影响。即使他名义上被分配到实验组,但因为他没有体验到实验策略所以这个用户的行为和对照组用户不会有什么差异。那么这么用户就是被分流给实验组,但是没有被实验组所影响。在实验分析时,保留真正被实验影响过的用户做分析而不是所有分流用户,可以提高实验的灵敏度。
实际案例:video审核流程实验的分流时机需要注意,例如举报实验正常情况下实验设计应该是内容被举报进而触发实验分流。但如果实验设计是投稿即分流,那么就需要用到上述trigger的方法去剔除那些根本没有走到被举报流程的内容的数据,以提升实验的灵敏度。
cuped提升灵敏度效果和什么有关?用户指标前后数据相关性。
Reduce variance降低方差
去除异常值
异常值是我们认为不合理的数据,例如一个用户单日有10w的click。我们推测异常数据大概率是由数据采集、加工埋点、存储过程系统问题所造成,因此在后续实验评估中我们可以把异常值进行剔除,避免对实验结果有所干扰。去除异常值可以改变指标的baseline以及降低样本的方差从而提高实验的灵敏度。
去除分流噪声(cuped)
用户表现或多或少存在连续性,一个用户实验期间的表现和实验前表现有很大程度上的关联。理想的实验情况是存在一个平行空间把所有用户都复制一遍,给真实世界和平行空间的用户不同的策略。那么实验期间实验组和对照组用户就是完全的同质性。但在实际操作中,我们只能通过分流的方式来模拟平行空间假设两组用户是完全同质的。
CUPED的方法或许可以对这个问题有所缓解。CUPED:Controlled-experiment using Pre-experiment Data,是一种利用历史信息数据来修正实验指标的方法,主要作用是降低指标方差,提高统计功效;CUPED可以针对用户稀释问题,在effect被稀释的情况下,提高统计Power;
从统计功效推导公式可知,要提升统计功效,可以增大样本量或者降低指标方差,而CUPED的本质就是降低实验指标的方差。在样本量有限的情况下,通过追溯AB组用户实验前的指标数据获取实验前后数据的相关性从而对实验指标方差进行修正,使得实验指标估计的置信区间精度有所提升;
非参检验-长尾指标
长尾指标存在很大的偏度,绝大部分用户的指标都非常小,但有极小部分的头部用户指标数值较大,导致指标方差非常大且拉高了baseline均值。
针对这类型的指标,首先可以考虑上述的极端值处理,其次就是非参检验处理。非参数检验不对指标分布有任何假设依赖,所以对于样本分布极端的实验是比较友好的。非参检验更关注指标的位置次序信息,只关心每个样本在总样本中的位置,但不关心偏离的具体数值。
以上,统计检验与提升实验灵敏度分享完毕,请为我点赞,敬请期待下一篇吧~!


















 2481
2481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









