 OpenAI函数调用集成Tavily
OpenAI函数调用集成Tavily




一.背景
在生成式 AI 技术落地过程中,大语言模型(LLM)虽具备强大的自然语言理解与推理能力,但受限于训练数据的时效性与知识边界,面对实时信息查询、专业领域最新动态、个性化场景数据等需求时,常出现 “知识滞后” 或 “幻觉生成” 问题。OpenAI Function Call 作为连接 LLM 与外部工具的核心桥梁,允许模型根据用户需求自主识别、调用第三方工具,将 AI 的推理能力与外部系统的功能(如检索、计算、数据交互)深度结合,彻底突破了 LLM 仅依赖内置知识的局限,成为构建实用化 AI 应用的关键技术。
Tavily 作为专为 LLM 和 AI Agent 设计的实时检索工具,凭借其结构化输出、高精准度检索、快速响应等特性,与传统通用搜索引擎相比,更适配 AI 场景的使用需求:其返回的结果包含清晰的标题、摘要、来源链接等结构化数据,无需 LLM 额外解析非结构化文本;同时支持深度检索、主题过滤、内容提炼等功能,能高效获取目标信息,大幅降低 LLM 处理冗余数据的成本,广泛应用于实时信息查询、专业知识补充、多源数据整合等场景。
在传统 LLM 与检索工具的结合模式中,开发者需手动处理复杂的协同逻辑:包括设计提示词引导模型生成工具调用指令、解析模型输出的非标准化参数、调用 Tavily API 并处理返回结果、将检索信息重新封装为模型可理解的格式等。这一过程不仅代码冗余、耦合度高,还易出现参数解析错误、检索逻辑与模型需求不匹配、多轮交互上下文丢失等问题,尤其在高吞吐、多场景的应用中,维护成本极高。
OpenAI Function Call 的出现为解决上述痛点提供了标准化方案,但在实际落地时仍面临适配挑战:如何定义符合 Tavily API 要求的函数签名以确保模型准确理解参数含义、如何处理检索结果的结构化解析与模型输入的适配、如何实现多轮函数调用中检索需求的动态调整(如补充检索、关键词优化)等。因此,开展 “OpenAI Function Call 结合 Tavily 工具” 的实践探索,核心目标是借助 OpenAI 标准化的函数调用机制,让 LLM 能自主、精准地调用 Tavily 完成实时检索,无需人工介入工具交互细节。这一实践不仅能充分发挥 LLM 的推理决策能力与 Tavily 的高效检索能力,解决实时信息查询场景中的知识滞后问题,还能沉淀标准化的工具集成流程,为后续构建更复杂的 AI Agent(如智能研究助手、实时数据查询机器人、个性化信息聚合工具)奠定基础,具有重要的技术实践价值与业务落地意义。
二.具体实现
1.首先需要访问tavily注册账号,获取token
tavily地址 Tavily - The Web Access Layer for AI Agents
2.创建python工程,引入依赖
import os
import sys
import json
from openai import OpenAI
import requests
# 设置控制台编码为 UTF-8,解决中文乱码问题
if sys.platform == 'win32':
# Windows 系统设置控制台编码
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
# 尝试设置控制台代码页为 UTF-8
try:
os.system('chcp 65001 > nul')
except:
pass3.定义tavily搜索函数
def tavily_search(query: str) -> str:
"""
Tavily 搜索工具
Args:
query: 搜索查询字符串
Returns:
搜索结果字符串
"""
try:
# 使用 Tavily API 进行搜索
# 注意:需要设置 TAVILY_API_KEY 环境变量
api_key = os.getenv("TAVILY_API_KEY", "xxxxxx")
if not api_key:
return "错误:未设置 TAVILY_API_KEY 环境变量"
url = "https://api.tavily.com/search"
payload = {
"api_key": api_key,
"query": query,
"search_depth": "basic"
}
response = requests.post(url, json=payload)
response.raise_for_status()
data = response.json()
# 格式化返回结果
results = []
if "results" in data:
for result in data["results"]:
results.append({
"title": result.get("title", ""),
"url": result.get("url", ""),
"content": result.get("content", "")
})
return json.dumps(results, ensure_ascii=False, indent=2)
except Exception as e:
return f"搜索出错:{str(e)}"4.定义openai,封装function call
client = OpenAI(api_key="xxxxxxxxxxx")
# 定义 Tavily 工具
tools = [
{
"type": "function",
"function": {
"name": "tavily_search",
"description": "使用 Tavily 搜索引擎搜索网络信息。适用于查找最新信息、新闻、事实等。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "要搜索的查询字符串"
}
},
"required": ["query"]
}
}
}
]5.进行大模型调用,并输出
# 创建消息
messages = [
{
"role": "user",
"content": "请搜索一下 Python 的最新版本信息"
}
]
print("正在调用 OpenAI API,使用 Tavily 工具进行搜索...")
try:
# 调用 OpenAI API
response = client.chat.completions.create(
model="gpt-4.0",
messages=messages,
tools=tools,
tool_choice="auto"
)
# 处理响应
message = response.choices[0].message
# 如果有工具调用
if message.tool_calls:
for tool_call in message.tool_calls:
if tool_call.function.name == "tavily_search":
# 解析参数
args = json.loads(tool_call.function.arguments)
query = args.get("query", "")
print(f"\n调用 Tavily 工具,搜索查询:{query}")
# 执行搜索
search_result = tavily_search(query)
# 将搜索结果添加到消息中
messages.append(message)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call.function.name,
"content": search_result
})
# 再次调用 OpenAI 获取最终回答
final_response = client.chat.completions.create(
model="gpt-4.1-2025-04-14",
messages=messages
)
print("\n搜索结果:")
print(final_response.choices[0].message.content)
else:
print("\nAI 回复:")
print(message.content)
except Exception as e:
print(f"错误:{str(e)}")
print("\n提示:请确保已设置以下环境变量:")
print(" - OPENAI_API_KEY: OpenAI API 密钥")
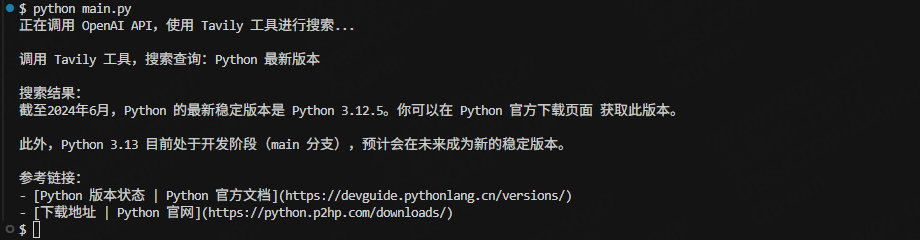
print(" - TAVILY_API_KEY: Tavily API 密钥")6.运行结果如下:


















 2466
2466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











