




 本文提出MSCap模型,用于多风格图像字幕生成。该模型由五个子网络组成,通过对抗学习网络,仅利用图像字幕数据原有标签和不成对的风格化字幕来生成多风格字幕。还设计了依赖风格的字幕生成器,引入反向翻译模块保证字幕与图像内容一致,并进行了定量和定性分析。
本文提出MSCap模型,用于多风格图像字幕生成。该模型由五个子网络组成,通过对抗学习网络,仅利用图像字幕数据原有标签和不成对的风格化字幕来生成多风格字幕。还设计了依赖风格的字幕生成器,引入反向翻译模块保证字幕与图像内容一致,并进行了定量和定性分析。
MSCap: Multi-Style Image Captioning with Unpaired Stylized Text
时间:2019 CVPR
题外话,这篇文章思路写的非常清楚,读起来很舒服
Intro
当前的image captioning方法通常生成一些客观的描述,而没有关于语言学上的研究,如图,展示了不同风格的caption
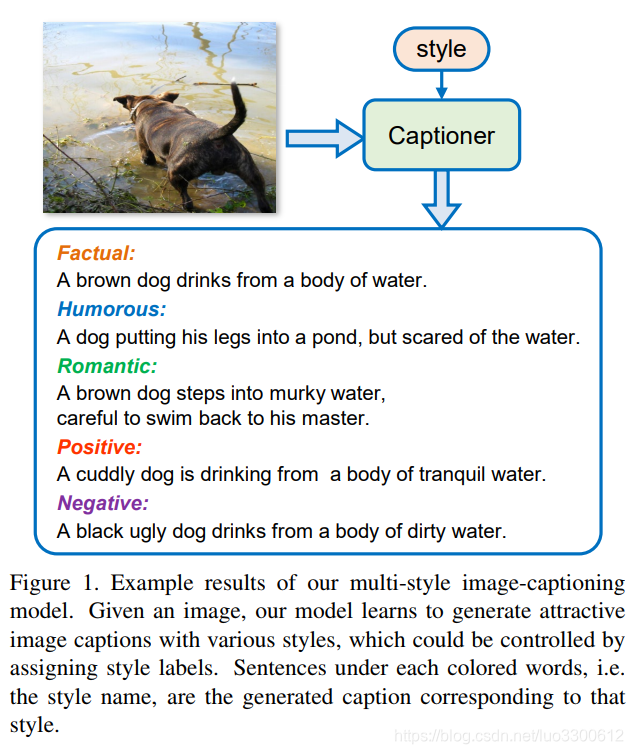
之前的相关工作也有将image caption的表达更丰富化的工作,但它们都无法同时生成多个风格的caption,为了生成
k
k
k种不同的表达,往往需要
k
k
k个不同的模型,为了解决这个问题,我们提出了一个multi-style image captioning(MSCap)模型,通过对抗学习网络来同时生成多风格的image caption,仅仅使用image caption数据上的原有img-caption标签和unpaired的风格化的caption。
本文的贡献:
- 提出了MSCap,一个生成多风格的caption的模型
- 设计了style-dependent的caption generator,可以利用不成对的风格化caption作为预训练,然后引入back-translation模块来保证生成的caption和图像内容一致
- 进行了定量和定性分析
MSCap for Multi-Style Image Captioning
overview
如图所示
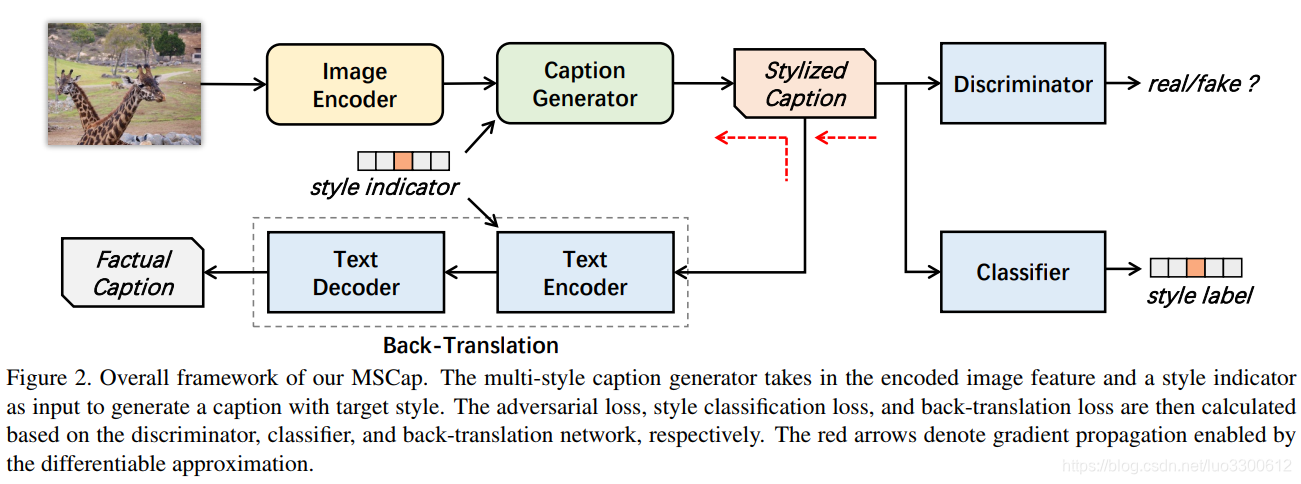
整个模型由五个子网络组成,image Encoder
E
E
E,caption generator
G
G
G,caption discriminator
D
D
D,style classifier
C
C
C,和back-translation network
T
T
T,给定数据集
P
=
(
x
,
y
^
f
)
P={(x,\hat{y}_f)}
P=(x,y^f),以及unpaired的风格化的corpse
P
u
=
(
y
^
s
,
s
)
,
s
∈
{
s
1
,
.
.
.
,
s
k
}
P^u={(\hat{y}_s,s)},s\in\{s_1,...,s_k\}
Pu=(y^s,s),s∈{s1,...,sk}包括
k
k
k个不同的caption,
y
^
s
\hat{y}_s
y^s是风格
s
s
s的caption,记
y
^
f
\hat{y}_f
y^f有factual风格,记为
s
0
s_0
s0,记拓展的风格化corpse为
P
′
=
(
y
^
s
,
s
)
,
s
∈
{
s
0
,
.
.
.
,
s
k
}
P'={(\hat{y}_s,s)},s\in\{s_0,...,s_k\}
P′=(y^s,s),s∈{s0,...,sk},我们的目标是生成句子
y
y
y,使得(1)
y
y
y是一个自然的句子,(2)
y
y
y是风格
s
s
s的,(3)(x,y)是相关的
Caption Generator G G G根据图片编码向量 E ( x ) E(x) E(x)和目标风格 s s s来生成句子 y = G ( E ( x ) , s ) y=G(E(x),s) y=G(E(x),s),然后喂给 D , C , T D,C,T D,C,T,来使得它分别满足每个条件,其中discriminator D D D分类器就是分别 y y y是否是自然语言输出,style classifier C C C输出 y y y属于 k + 1 k+1 k+1个类别的概率,back-translation module T T T用来保证 y y y是视觉上基于 x x x的,这通过将 y y y翻译到 y ^ f \hat{y}_f y^f实现
Image Encoder
本文使用context vector c v = E ( x ) c^v=E(x) cv=E(x)
Caption Generator
condition G G G on style labels,本文使用 k + 1 k+1 k+1维one-hot向量来编码风格,然后通过一个embedding层concat到输入的word embedding上得到 w t w_t wt,作为LSTM每步的输入
Enable training on unpaired corpus,在unpaired数据集上训练的常规方法是需要图片特征的,但unpaired数据集上没有这个特征,因此我们采用了merging和style gate(如图(b)所示)
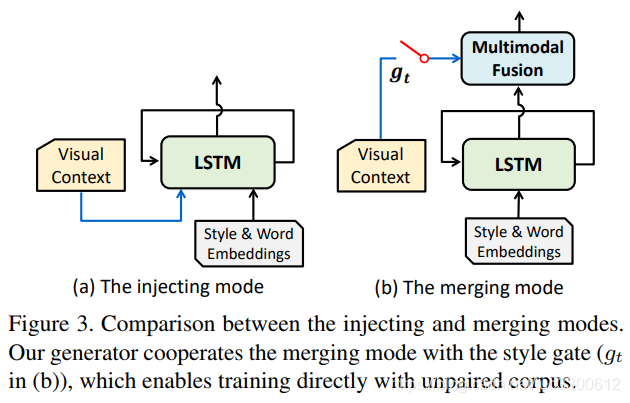
我们首先将visual context移出LSTM,让LSTM仅仅建模语言信息,然后引入一个额外的multimodal fusion module来融合visual context
c
v
c^v
cv和liguistic context
c
t
l
c^l_t
ctl来预测词。style gate为词的预测提供了一个plan B,当没有图片时仅仅依赖
c
t
l
c^l_t
ctl,综合的信息取两者的加权和
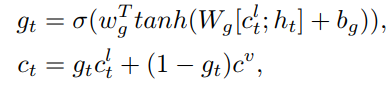
c
t
c_t
ct是mixed context vector,
h
t
h_t
ht是LSTM的隐藏状态,且
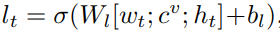
c
t
l
=
l
t
⊙
t
a
n
h
(
m
t
)
c^l_t=l_t\odot tanh(m_t)
ctl=lt⊙tanh(mt)
其中
l
t
l_t
lt是gate vector,
m
t
m_t
mt是memory cell state,然后预测下一个词
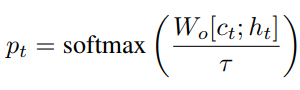
其中
τ
\tau
τ是temperature parameter,训练的unpaired的数据的时候,将
g
t
g_t
gt设置为1即可,此时模型完全依赖于linguistic context
我们在paired的数据和unpaired的数据上预训练caption generator,通过最大化对数似然
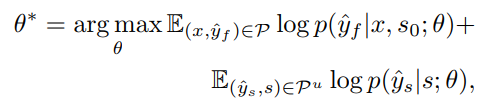
Adversarial Loss
discriminator
D
D
D用来区分generator
G
G
G的生成结果
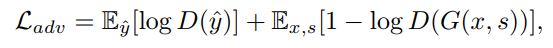
其中
y
^
\hat{y}
y^是真实的caption
Style Classification Loss
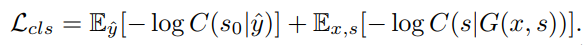
Back-Translation Loss
这一步将生成的caption和image关联起来,基于假设
x
x
x和
y
^
f
\hat{y}_f
y^f拥有相同的信息,则生成的caption
y
y
y和图片
x
x
x的相关性就可以通过
y
y
y和ground truth
y
^
f
\hat{y}_f
y^f来估计,所以我们限制
y
y
y和
y
^
f
\hat{y}_f
y^f的内容一致,这通过使用back-translation module T将
y
y
y翻译会
y
f
y_f
yf来实现,即
T
(
y
,
s
)
→
y
^
f
T(y,s)\to\hat{y}_f
T(y,s)→y^f,T通过multilingual neural machine translation(NMT) network来实现,以encoder和decoder组成,目标是最小化
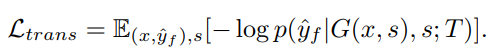
另一种方法是将
y
y
y直接翻译成图片,但这比较困难
Full Objectives
最终的损失函数为
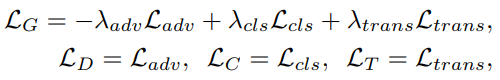
Training Strategy
由于训练的不稳定和方差大等问题,我们使用了WGAN等的训练策略
Experimental Setup
数据集
- COCO
- FlickrStyle10K
- SentiCap
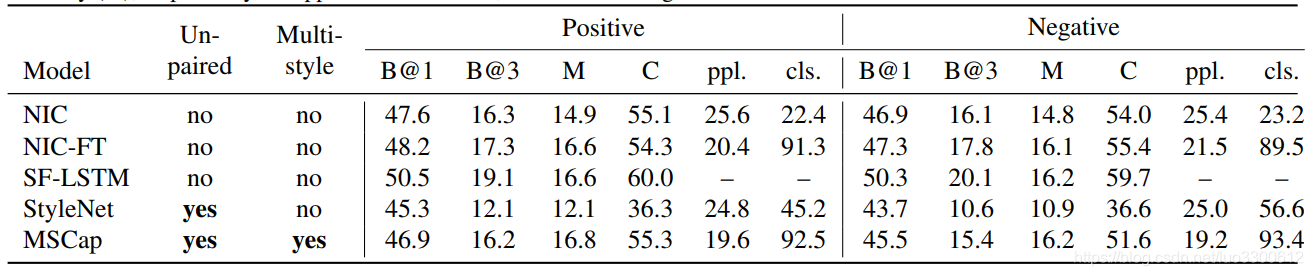
Result
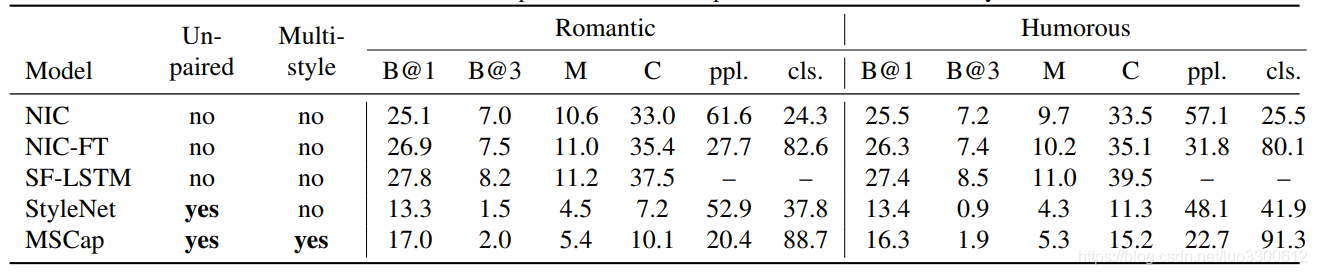

结论
本文使用unpaired的数据训练了一个能够生成多个style的Image caption模型
问题
- unpaired的数据如何度量生成caption的质量?实际上数据是paired的
- 同style的unpaired数据在 G G G上训练的时候如何相互区分?如果连输入图片都没有的话?

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









