




这是我在百度文库下载的两个文档,一个是高中词汇文档,一个是四级词汇文档。我将文档中的单词与短语过滤出来,并进行去重,经过对比得出相似度!!!
精髓代码如下(仅供参考):
from docx import Document
x = 1
able = []
ablex = []
def input(doc):
global x
gg = 0
able1 = []
yes = []
add = 0
ll = ""
for i in range(0, len(doc.paragraphs)):
b = (doc.paragraphs[i].text).split()
p = 0
o = 0
for j in range(0, len(b)):
k = b[j]
for n in range(0, len(k)):
if ("a" <= k[n] <= "z" or "A" <= k[n] <= "Z" or k[n] == "/"):
add += 1
if (add == len(k) and add > 1):
able1.append(k)
add = 0
yes.append(p)
else:
add = 0
p += 1
yes.append(-1)
for i in range(len(yes) - 1):
if (yes[i] + 1 == yes[i + 1]):
ll = ll + able1[o] + " "
o += 1
else:
ll = ll + able1[o]
o += 1
if(x==1):
able.append(ll)
else:
ablex.append(ll)
ll = ""
yes.clear()
able1.clear()
o = 0
if(x==2):
ableupdata1 = []
ableupdata2 = []
for i in able:
if i not in ableupdata1:
ableupdata1.append(i)
for i in ablex:
if i not in ableupdata2:
ableupdata2.append(i)
for i in range(0, len(ableupdata1)):
for j in range(0, len(ableupdata2)):
if (ableupdata1[i] ==ableupdata2[j]):
gg += 1
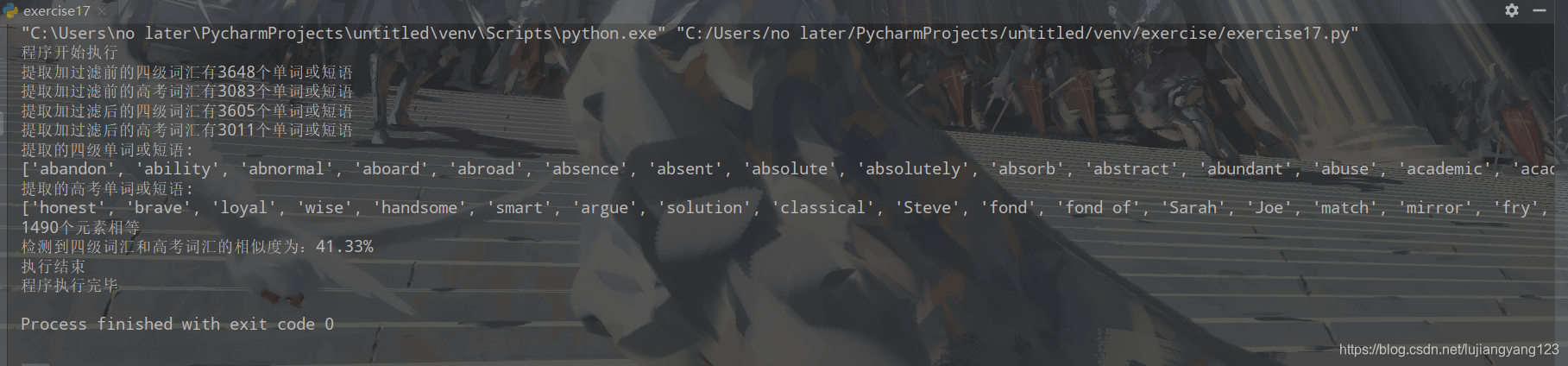
print("提取加过滤前的四级词汇有%d个单词或短语" % len(able))
print("提取加过滤前的高考词汇有%d个单词或短语" % len(ablex))
print("提取加过滤后的四级词汇有%d个单词或短语"%len(ableupdata1))
print("提取加过滤后的高考词汇有%d个单词或短语"%len(ableupdata2))
print("提取的四级单词或短语:")
print(ableupdata1)
print("提取的高考单词或短语:")
print(ableupdata2)
print("%d个元素相等" %gg)
print("检测到四级词汇和高考词汇的相似度为:%.2f%%"%((gg/len(ableupdata1))*100))
print("执行结束")
else:
x += 1
def main():
print("程序开始执行")
doc = Document('B:\\english\\四级词汇.docx')
input(doc)
doc = Document('B:\\english\\高中词汇.docx')
input(doc)
print("程序执行完毕")
if __name__ == '__main__':
main()
运行结果:
觉得这个代码很不错,分享一下!!!
很多人会想,你是怎么辨别单词跟短语的???
只要能解决这个问题,那么辨别单词跟短语这个问题就迎刃而解!
问题:有这么两个列表,一个是全是数字,一个全是单词,如何根据全是数字列表的相邻数字是否有连续性,通过模仿来拼接另一个列表的字符串呢?
举个例子:
比如,这有个列表[“my”,“name”,“is”,“xizi”,“and”,“my”,“family”,“good”]如何根据number=[1,2,3,0,4,7,8,9]中的相邻数字是否有连续性,生成一个新的列表[‘my name is’, ‘xizi’, ‘and’, ‘my family good’]!
精髓代码如下(仅供参考):
able1=[]
able=["my","name","is","xizi","and","my","family","good"]
number=[1,2,3,0,4,7,8,9]
ll=""
o=0
number.append(-99)
for i in range(len(number) - 1):
if (number[i] + 1 == number[i + 1]):
ll = ll + able[o] + " "
o += 1
else:
ll = ll + able[o]
o += 1
able1.append(ll)
ll = ""
print(able1)
#运行结果:
#['my name is', 'xizi', 'and', 'my family good']
有小伙伴感兴趣的!可以加一下下面的qq群,要一下高中词汇文档跟四级词汇文档,当然了,你也可以自己在百度文库下载,但是文档必须符合标准!
来一波,推送吧!
群号:781121386
群名:人生苦短,我学编程
欢迎大家加入我们,一起交流技术!!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









