



 本文深入探讨Spark作为新一代大数据计算引擎的核心概念与操作,包括RDD的创建与转换、Transformations和Actions详解,以及KeyValue对RDDs的高效处理技巧。
本文深入探讨Spark作为新一代大数据计算引擎的核心概念与操作,包括RDD的创建与转换、Transformations和Actions详解,以及KeyValue对RDDs的高效处理技巧。
概述:Spark是新一代大数据计算引擎,具有内存计算的特性,计算速度比hadoop更快。本文涉及Spark基础概念RDD,KeyValueRDD以及RDD的常用Transformation和Action操作等内容,更多内容请参考慕课网Terby老师的《Spark从零开始》
1、一个RDD是一个不可改变的分布式集合对象
在spark中,所有的计算都是通过RDDs的创建、转换操作完成的
一个RDD内部由许多分片(partitions)组成
#分片
var rdd=sc.parallelize(Array(1,2,3,4),4)
rdd .count()
rdd.foreach(println)
#创建变量还可以使用val 但该变量值不可修改
val lines=sc.textFile("/root/data/statistics.txt")
lines=sc.textFile("/root/data/statistics.txt) #error
2、scala匿名函数和类型推断
#查找包含指定单词的行
var lines=sc.textFile("/root/data/statistics.txt")
#line 不需要指定类型(String),scala会自动推断出来,代表每一行,=>表示匿名函数
var lines2=lines.filter(line=>line.contains("enthusiasm"))
#打印输出
lines.foreach(print)
3、Transformations
(1) map()接收函数,将函数应用到RDD的每一个元素,返回新的RDD
var lines=sc.parallelize(Array("Hello","spark","hello","world","Hello","!"),4)
lines.foreach(println)
#map
var lines2=lines.map(word=>(word,1)).foreach(println)
lines2.foreach(println)
(2) filter()接收函数,返回只包含满足filter()函数的元素的新RDD
#接(1)
var lines3=lines.filter(word=>word.contains("Hello"))
lines3.foreach(println)
(3) flatMap() 对每个输入元素,输出多个输出元素,flat表示压缩,将RDD中元素压缩后返回一个新的RDD
val inputs=sc.textFile("/root/data/statistics.txt")
inputs.foreach(println)
#压缩
val inputs=sc.textFile("/root/data/statistics.txt")
var lines=inputs.flatMap(line=>line.split(" "))
lines.foreach(print)
# 链式写法: sc.textFile("/root/data/statistics.txt").flatMap(line=>line.split(" ")).foreach(print)
#使用map
lines.map(word=>(word,1)).foreach(println)
(4) 集合运算
val rdd1=sc.parallelize(Array("China","American","Russia","Canada","Russia","Japan","Koran"))
val rdd2=sc.parallelize(Array("China","American","England","Canada","Japan","French","England"))
#去重
val rdd1_distinct=rdd1.distinct()
rdd1_distinct.foreach(println)
val rdd2_distinct=rdd2.distinct()
rdd2_distinct.foreach(println)
#并集
val rdd_union=rdd1.union(rdd2)
rdd_union.foreach(println)
#交集
val rdd_inter=rdd1.intersection(rdd2)
rdd_inter.foreach(println)
#差集
val rdd_sub=rdd1.subtract(rdd2).foreach(println)
4、Actions
(1) 常见Actions
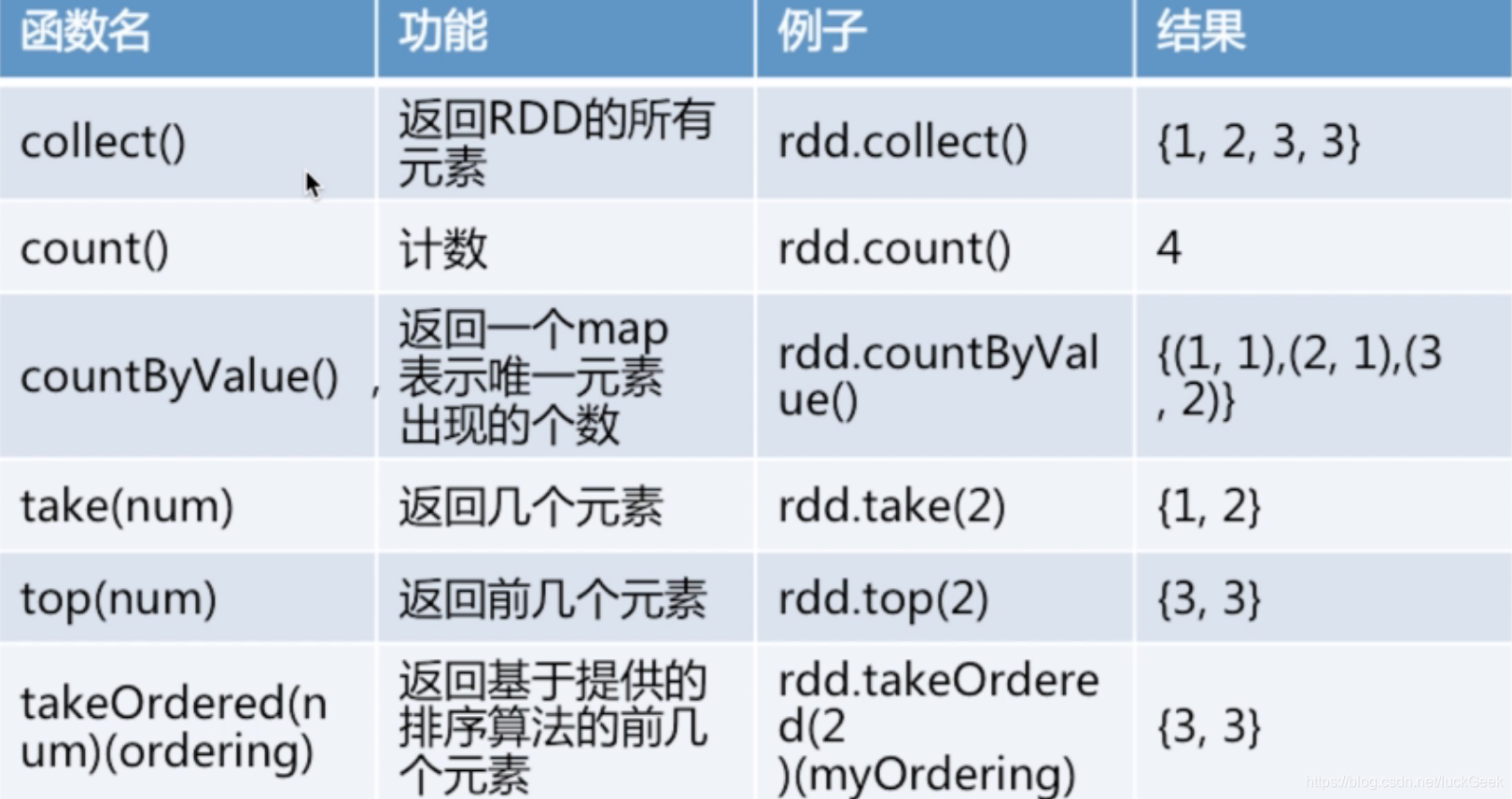
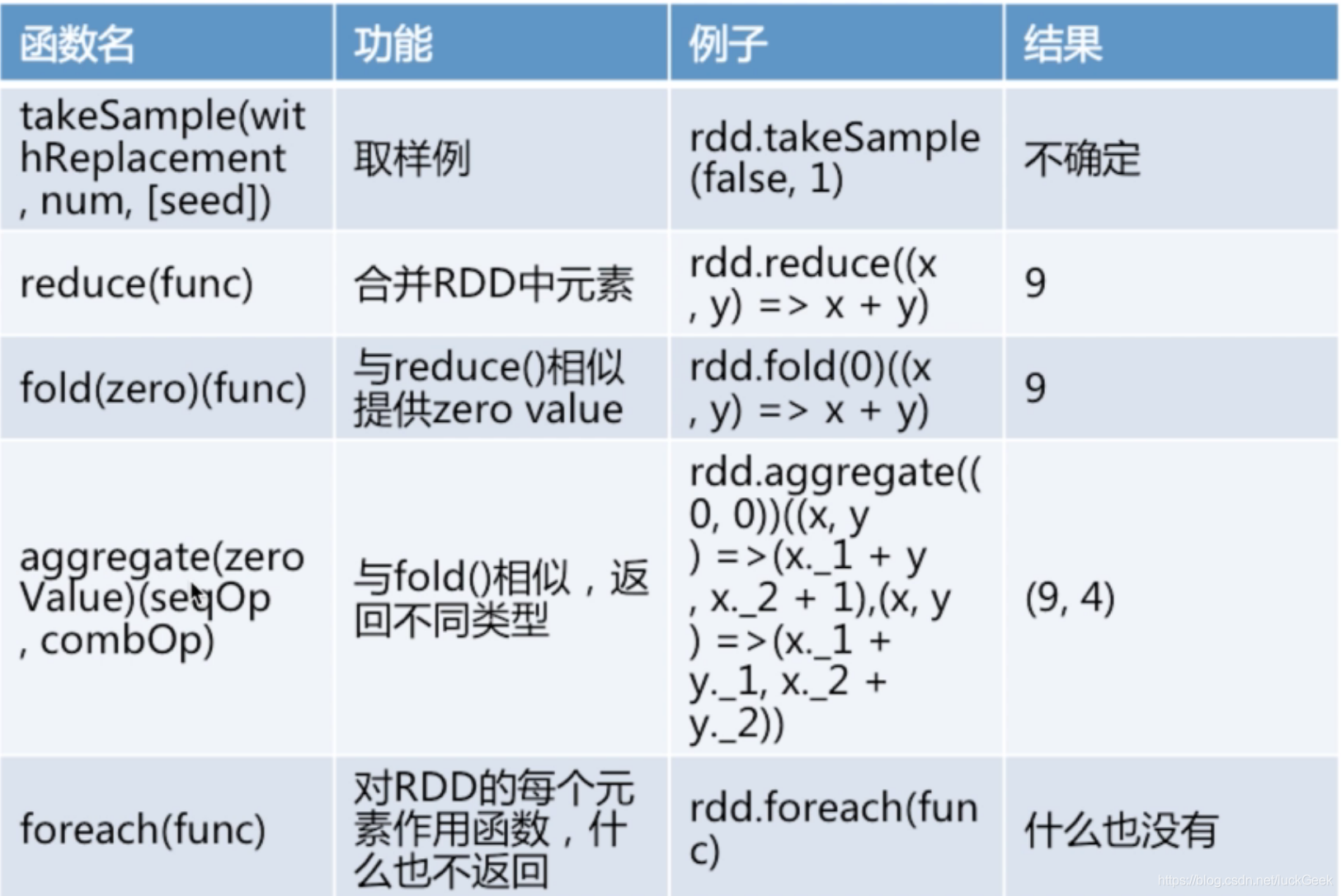
- reduce() 接收一个函数,作用在RDD两个类型相同的元素上,返回新元素,可以实现RDD中元素的累加、计数和其他类型的聚合操作
val rdd=sc.parallelize(Array(1,4,6,5,3,2,1,4,2))
#遍历数组
rdd.collect()
rdd.take(2)
#从大到小排序
rdd.top(10)
#求数组总和
rdd.reduce((x,y)=>x+y)
#打印输出
rdd.foreach(println)
- collect() 遍历整个RDD,向Driver program返回RDD的内容
需要单机内存能够容纳下(因为数据要拷贝给Driver,测试使用)
大数据时,使用savaAsTextFile() action等
- take(n) 返回RDD的n个元素(同时尝试访问最少的partitions),结果是无序的,测试时使用
- top() 排序(根据RDD中数据的比较器,可以自定义)
- foreach() 计算RDD中的每个元素,但不返回到本地,可配合print/println打印输出
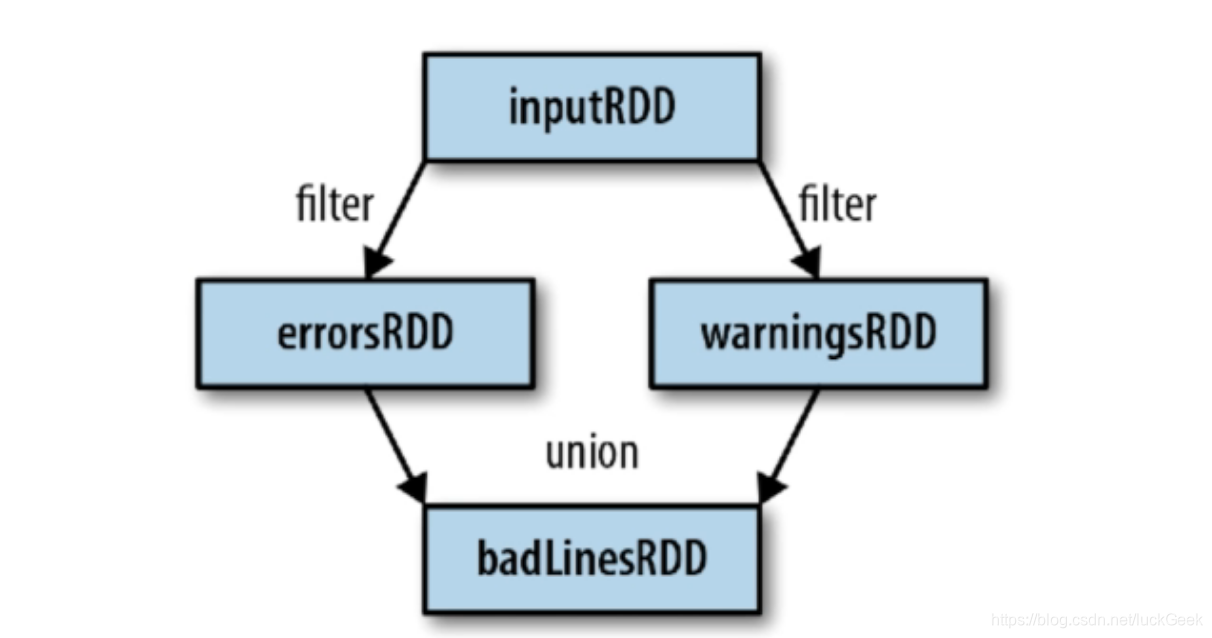
RDDs的特性
- 血统关系图
指Spark维护的RDDs之间的依赖关系,Spark使用血统关系来计算每个RDD的需求和恢复丢失的数据
- 延迟加载
Spark第一次使用action操作时才对RDDs进行计算有助于减少大数据处理中的数据传输
- RDD.persist()
默认每次在RDDs上进行action操作时,Spark都重新计算Rdds,使用RDD.persist()可以重复利用RDD
unpersist()方法可以从缓存中移除RDD
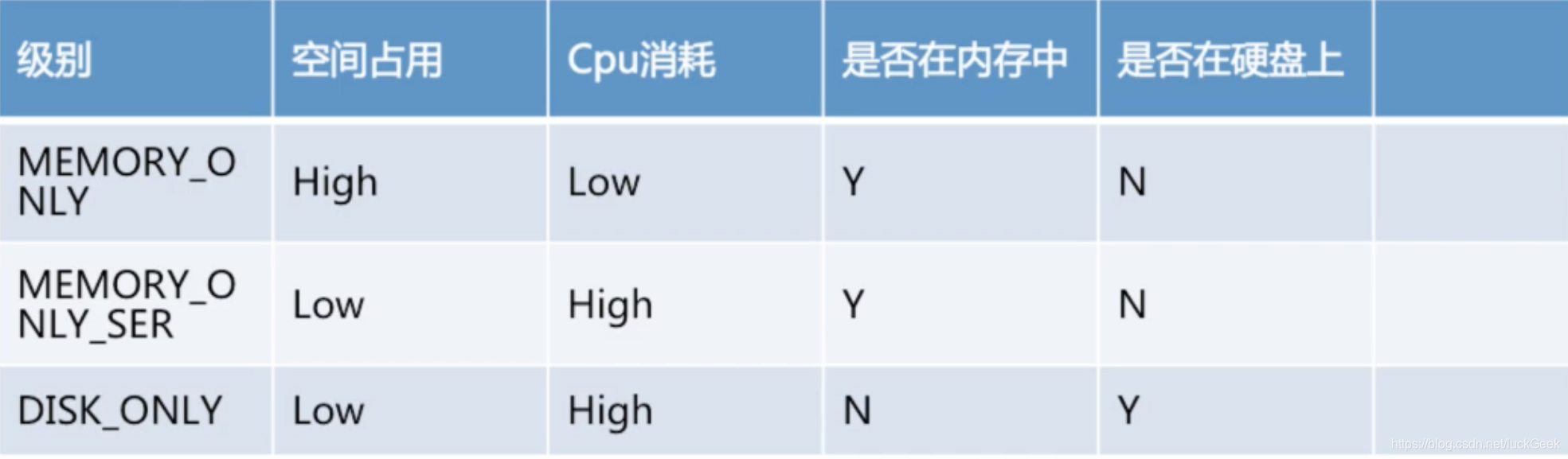
RDD.persist() 中可以传入级别作为参数,含义分别如下
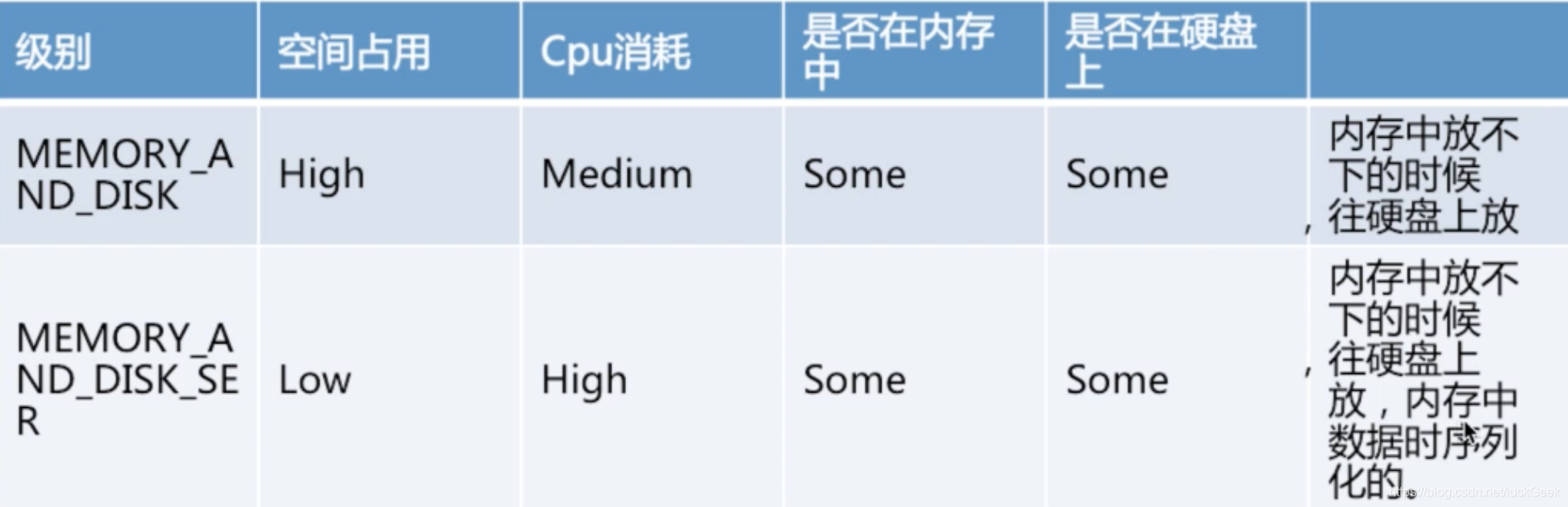
5、KeyValue对RDDs的创建与操作
(1) 创建KeyValue对RDDs,使用map()函数,返回key/value对
eg:RDD包含多行数据,将每行数据的第一个单词作为key
val rdd=sc.textFile("/root/data/statistics.txt")
val rdd2=rdd.map(line=>(line.split(" ")(0),line))
rdd2.foreach(println)
#数组元素为key/value
val rdd=sc.parallelize(Array((1,2),(3,4),(3,9),(1,3),(6,6)))
rdd.foreach(println)
#reduceByKey的使用(key相同,值相加)
val rdd2=rdd.reduceByKey((x,y)=>x+y)
rdd2.foreach(println)

#groupByKey()无须参数
val rdd3=rdd.groupByKey()
rdd3.foreach(println)


rdd3.keys.foreach(println)
rdd3.values.foreach(println)
rdd3.sortBykey.foreach(println)

(2) combineByKey()
(createCombiner,mergeValue,mergeCombiners,partitioner)
是最常用的基于key的聚合函数,返回值可以与输入类型不一样
遍历partition中的元素,根据元素key是否已存在调用不同函数
- 新元素,使用createCombiner()
- 已存在,使用mergeValue()
- 合计每个partition的结果时,使用mergeCombiners()
eg:求平均值
val scores=sc.parallelize(Array(("Jim",88.0),("Jim",82.0),("Jim",80.0),("Bob",92.0),("Bob",86.0),("Bob",90.0)))
scores.foreach(println)
#求分数总和
val score2=scores.combineByKey(score=>(1,score),(c1:(Int,Double),newScore)=>(c1._1+1,c1._2+newScore),(c1:(Int,Double),c2:(Int,Double))=>(c1._1+c2._1,c1._2+c2._2))
score2.foreach(println)
#求平均值
val avg=score2.map{case(name,(num,score))=>(name,score/num)}
age.foreach(println)


















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









