




 本文深入探讨Spark Streaming的应用,包括依赖配置、单次与累计统计代码示例,以及如何利用updateStateByKey进行状态更新。同时,介绍了如何将数据保存至Redis,并讲解了Spark Streaming的输出操作。
本文深入探讨Spark Streaming的应用,包括依赖配置、单次与累计统计代码示例,以及如何利用updateStateByKey进行状态更新。同时,介绍了如何将数据保存至Redis,并讲解了Spark Streaming的输出操作。
依赖:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
</dependency>
代码:单次统计
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NetworkWordCount {
def main(args: Array[String]) {
/*指定时间间隔为5s*/
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
.setMaster("local[2]")
// new SparkContext()
val ssc = new StreamingContext(sparkConf, Seconds(3))
/*创建文本输入流,并进行词频统计*/
val lines = ssc.socketTextStream("hdp-1", 9999)
lines.flatMap(_.split(" ")).map(x => (x, 1))
.reduceByKey(_ + _).print()
/*启动服务*/
ssc.start()
/*等待服务结束*/
ssc.awaitTermination()
}
}
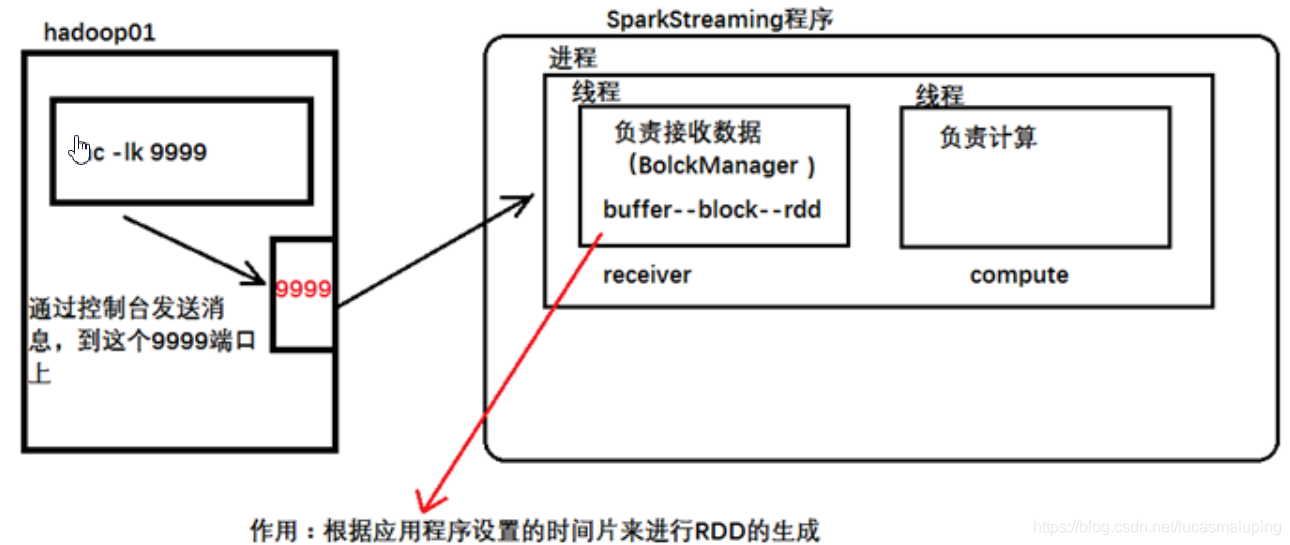
如果在计算的时候,指定–master时 使用的是local 并且只指定了一个线程,那么只有receiver线程工作,计算的线程不会工作,所以在指定线程数的时候,最少指定2个。
代码:累计统计
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NetworkUpdateStateWordCount {
/**
* String : 单词 hello
* Seq[Int] :单词在当前批次出现的次数
* Option[Int] : 历史结果
*/
// val i : Int = 11;
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))}
}
def main(args: Array[String]) {
// LoggerLevel.setStreamingLogLevels()
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("NetworkUpdateStateWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
//做checkpoint 写入共享存储中
ssc.checkpoint("c://aaa")
val lines = ssc.socketTextStream("hdp-1", 9999)
//reduceByKey 结果不累加
//val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
//updateStateByKey结果可以累加但是需要传入一个自定义的累加函数:updateFunc
val results = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
除了能够支持RDD的算子外,DStream还有部分独有的transformation算子,这当中比较常用的是updateStateByKey
使用updateStateByKey算子,你必须使用ssc.checkpoint()设置检查点,这样当使用updateStateByKey算子时,它会去检查点中取出上一次保存的信息,并使用自定义的updateFunction函数将上一次的数据和本次数据进行相加,然后返回。
文中iter.flatMap{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))}中为什么用{}?
下面的问题,表面上看是小括号与花括号的问题。
// map方法这样写不能编译通过
scala> List(2).map( case 2 => “OK” )
// 换做花括号就可以了
scala> List(2).map{ case 2 => “OK” }
不了解原因的话,觉得很诡异。分析一下,首先,map方法接受一个函数,这个函数将List中的元素映射为其他类型。
实际上case 2 => “OK” 不是一段lambda表达式(也就是说它不是函数),它是一段模式匹配语句。
那为什么在第二行可以编译通过呢?
方法的花括号有2种意思:
1)scala中函数的小括号,可以用花括号来表示,即foo{xx} 与 foo(xx)是一回事儿。(这里一回事是指函数的小括号)
2)对于只有一个参数的方法,其小括号是可以省略的,map(lambda)可写为 map lambda,即这块{case 2 => “OK”} 连同花括号整体是一个lambda(函数字面量)。
这个就是最上面的问题的答案了。
这儿显然是第2个(追究原因就要看编译器在语法解析式的优先级了,看样子把花括号对待为lambda字面量的一部分要高于把花括号当作小括号来对待),那么为什么加了花括号的{case 2 => “OK” }就可以当作一段函数字面量?
这要引出偏函数的概念,所谓偏函数(也叫部分函数)与完全函数想对应,普通的方法都是完全函数,即 f(i:Int) = xxx 是将所有Int类型作为参数的,是对整个Int集的映射;而偏函数则是对部分数据的映射,比如上面{case 2=> “OK” }就仅仅只对2做了映射。偏函数的实现都是通过模式匹配来表达的。
scala> val p:PartialFunction[Int,String] = { case 2 => “OK” }
因为偏函数是通过 { case x => y } 这种特殊的方式来描述的,上面的{case 2=>“OK”}就被当作了一段偏函数字面量,而偏函数背后的类型PartialFunction[A,B]是继承自Function1[A,B]的,所以将这段匿名的偏函数传给map方法是ok的。
小结:表达式 {case x=>y}会被当作偏函数字面量。
foreachRDD
依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
object NetworkWordCountToRedis {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCountToRedis").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
/*创建文本输入流,并进行词频统计*/
val lines = ssc.socketTextStream("hdp-1", 9999)
val pairs: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_ + _)
/*保存数据到Redis*/
pairs.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
var jedis: Jedis = null
try {
jedis = JedisPoolUtil.getConnection
jedis.auth("lucas")
partitionOfRecords.foreach(record => jedis.hincrBy("wordCount", record._1, record._2))
} catch {
case ex: Exception =>
ex.printStackTrace()
} finally {
if (jedis != null) jedis.close()
}
}
}
ssc.start()
ssc.awaitTermination()
}
}
JedisPoolUtil
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolUtil {
/* 声明为volatile防止指令重排序 */
private static volatile JedisPool jedisPool = null;
private static final String HOST = "hdp-1";
private static final int PORT = 6379;
/* 双重检查锁实现懒汉式单例 */
public static Jedis getConnection() {
if (jedisPool == null) {
synchronized (JedisPoolUtil.class) {
if (jedisPool == null) {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(30);
config.setMaxIdle(10);
jedisPool = new JedisPool(config, HOST, PORT);
}
}
}
return jedisPool.getResource();
}
}
在实际计算时,Spark会将对RDD操作分解为多个Task,Task运行在具体的Worker Node上。在执行之前,Spark会对任务进行闭包,之后闭包被序列化并发送给每个Executor,而Jedis显然是不能被序列化的
SparkStreaming的输出方式:
Spark Streaming支持以下输出操作:
1、print() 在运行流应用程序的driver节点上打印DStream中每个批次的前十个元素。用于开发调试。
2、saveAsTextFiles(prefix, [suffix]) 将DStream的内容保存为文本文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。
3、saveAsObjectFiles(prefix, [suffix]) 将DStream的内容序列化为Java对象,并保存到SequenceFiles。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。
4、saveAsHadoopFiles(prefix, [suffix]) 将DStream的内容保存为Hadoop文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS [.suffix]”。
5、foreachRDD(func) 最通用的输出方式,它将函数func应用于从流生成的每个RDD。此函数应将每个RDD中的数据推送到外部系统,例如将RDD保存到文件,或通过网络将其写入数据库。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









