




 本文深入解析了KNN(K-近邻算法)和SVM(支撑向量机)两种经典机器学习算法的原理及应用。KNN通过计算新数据与训练集中数据的距离,依据最近邻居的类别进行投票,确定新数据的分类。SVM则通过Bias Trick简化模型,实现数据的分类。文章详细介绍了L1和L2距离计算方法及其在算法中的作用。
本文深入解析了KNN(K-近邻算法)和SVM(支撑向量机)两种经典机器学习算法的原理及应用。KNN通过计算新数据与训练集中数据的距离,依据最近邻居的类别进行投票,确定新数据的分类。SVM则通过Bias Trick简化模型,实现数据的分类。文章详细介绍了L1和L2距离计算方法及其在算法中的作用。
KNN(K-近邻算法)
原理
有监督学习。
已有一堆正确分类的数据集,对于新的数据,通过计算在新数据的一定距离内的数据中,哪类数据占优(投票),判定新的数据的类别。
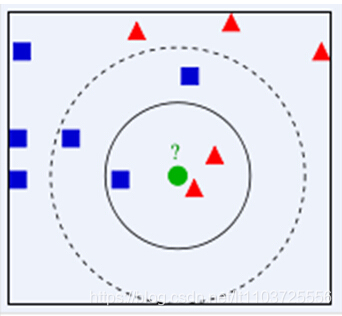
k——离新数据最近的数据个数(总投票数)
距离
L1距离或L2距离,见CS231n学习笔记
L1距离:d1(I1,I2)=∑p∣I1p−I2p∣d_1\left ( I_1,I_2 \right )=\sum_p\left | I_1^p-I_2^p \right |d1(I1,I2)=∑p∣I1p−I2p∣
又称曼哈顿距离,即每个对应位置相减再求和
L2距离:d2(I1,I2)=∑p(I1p−I2p)2d_2\left ( I_1,I_2 \right )=\sqrt{\sum_p\left ( I_1^p-I_2^p \right )^2}d2(I1,I2)=∑p(I1p−I2p)2
又称欧式距离,每个对应位置相减平方和开根
区别:L1距离依赖于数据的坐标系统,也就是说数据的向量的每个值都有不同的意义时用L1更合适
L2距离的矩阵描述
矩阵的欧式距离
参考https://blog.youkuaiyun.com/frankzd/article/details/80251042
算法描述
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
SVM(支撑向量机)
Bias Trick
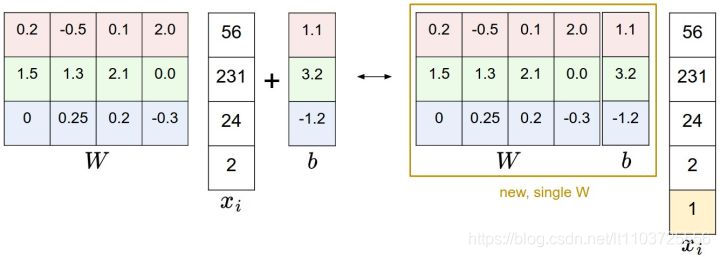
WTx+bW^Tx+bWTx+b,这样的话就要更新W矩阵和b向量,我们可以直接把W和b合并,然后给xxx增加一个1,这样原式就变成了合并后的矩阵×x合并后的矩阵\times x合并后的矩阵×x,更新时只用更新一个矩阵就好了,不过缺点是x和w都要增加一个维度,W增加的是b,x增加的是1
零均值中心化
就是每个图像减去所有图像的均值,让每个像素点的范围保持在-127~127


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









