



 本文展示了如何通过抽取变化部分为参数和创建公共父类来优化Java DAO层代码,以减少重复。此外,还实现了通用的分页查询功能,包括MySQL的LIMIT分页,并提供了前台分页的标签实现,简化了前后端交互。
本文展示了如何通过抽取变化部分为参数和创建公共父类来优化Java DAO层代码,以减少重复。此外,还实现了通用的分页查询功能,包括MySQL的LIMIT分页,并提供了前台分页的标签实现,简化了前后端交互。
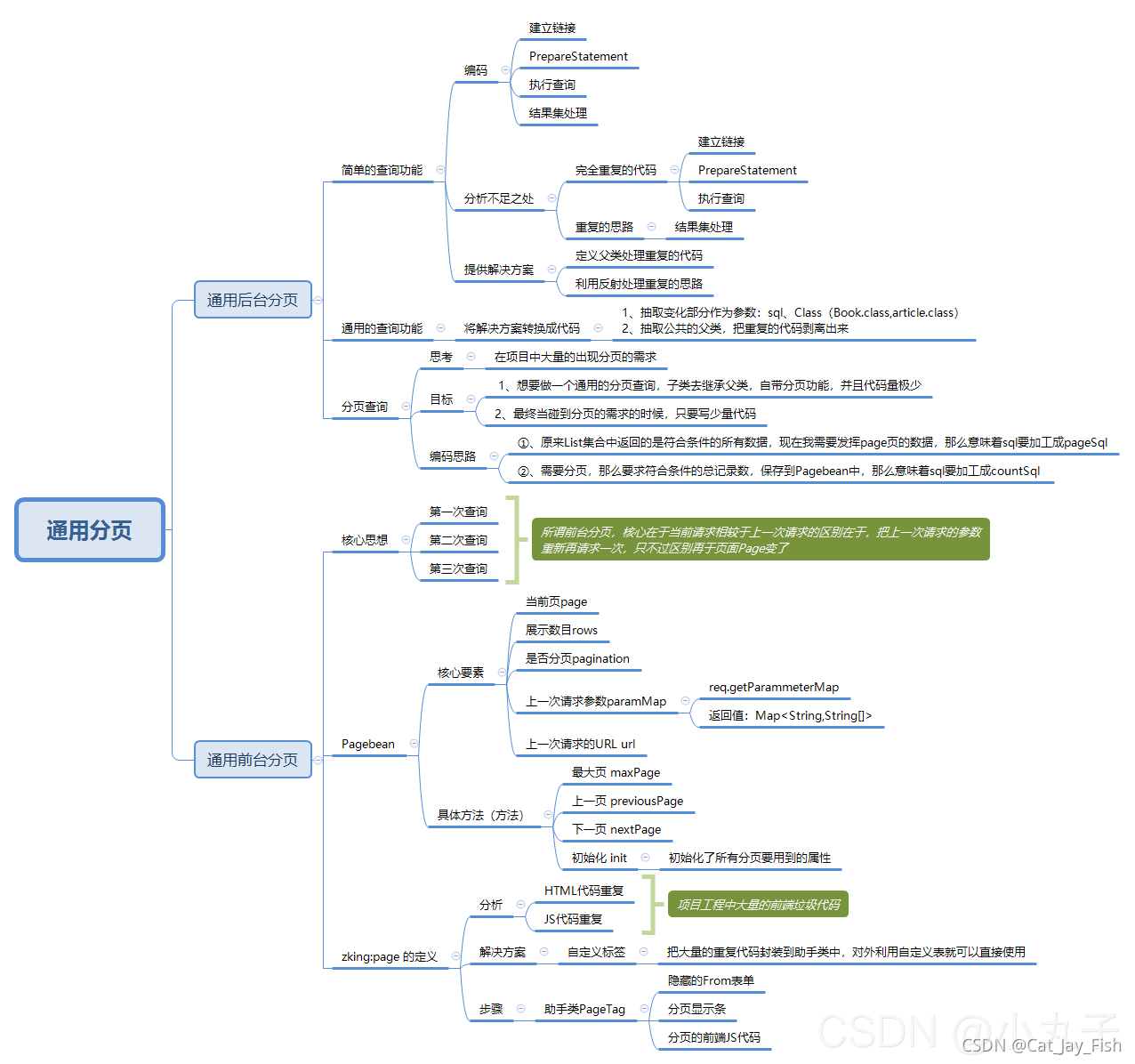
一,后台分页
原生的
package com.lsy.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import com.lsy.entity.Book;
import com.lsy.util.DBAccess;
import com.lsy.util.PageBean;
import com.lsy.util.StringUtils;
public class BookDao extends BaseDao<Book>{
/**
* 简单的查询方法
* 1.建立数据库连接
* 2.预编译对象 preparestatement
* 3.查询结果集
* 4.处理结果集
*
* 分析不足之处 t_jsoup_article
* 1.换表查询以上步骤都需要重复
* 2.都是要返回数据库表对应的集合
* 集合中的对象都是不同的
* 3.都是要处理结果集
* 代码不一样,具体体现在,不同的表会有不同的字段,实体类对应的属性就会不一样
总结:需要写大量的重复代码,系统中的查询功能越多,重复代码量越大
提供解决方案
1.抽取变化部分作为参数
2.抽取公共的父类,把重复性的代码剥离出来
*/
public List<Book> list(Book book) throws Exception{
List<Book> books=new ArrayList<Book>();
String sql="select * from t_mvc_book where 1=1";
//书籍名称
String bname=book.getBname();
//书籍名称模糊查询 圣墟最终是前台jsp页面传过来的
if(StringUtils.isNotBlank(bname)) {
sql+=" and bname like '%"+bname+"%'";
}
Connection con=DBAccess.getConnection();
PreparedStatement pst = con.prepareStatement(sql);
ResultSet rs=pst.executeQuery();
while(rs.next()) {
books.add(new Book(rs.getInt("bid"), rs.getString("bname"), rs.getFloat("price")));
}
return books;
}
public List<Book> list2(Book book) throws Exception{
List<Book> books=new ArrayList<Book>();
String sql="select * from t_mvc_book where 1=1";
//书籍名称
String bname=book.getBname();
//书籍名称模糊查询 圣墟最终是前台jsp页面传过来的
if(StringUtils.isNotBlank(bname)) {
sql+=" and bname like '%"+bname+"%'";
}
return super.list(sql, Book.class);
}
/**
* 测试通用分页查询
* @param book
* @param pageBean
* @return
* @throws Exception
*/
public List<Book> list3(Book book,PageBean pageBean) throws Exception{
List<Book> books=new ArrayList<Book>();
String sql="select * from t_mvc_book where 1=1";
//书籍名称
String bname=book.getBname();
//书籍名称模糊查询 圣墟最终是前台jsp页面传过来的
if(StringUtils.isNotBlank(bname)) {
sql+=" and bname like '%"+bname+"%'";
}
return super.executeQuery(sql, Book.class, pageBean);
}
/**
* 思考:
* 在项目中大量的出现分页(订单列表,商品列表,学生列表.....)
* 目标:
* 想要做一个通用的分页查询,子类去继承父类,自带了分页功能
* 最终当碰到分页的需求的时候,只需要写少量的代码
* 实现:
* 1.mysql分页
* 分页通常有关键的因素,第page页,显示数目(rows),符合查询条件的总记录数(total)
* 2.编码思路
* 2.1原来list集合中返回的是符合条件的所有的数量
* 现在需要返回第page页的数据,那么意味着sql要加工成countSql
* 2.2需要分页,那么要求出符合条件的总记录数,保存到pagebean中
* 共N页的算法:total % rows ==0 ? total /rows :total / rows +1;
*
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
BookDao bookDao=new BookDao();
Book book=new Book();
book.setBname("圣墟");
// List<Book> list = bookDao.list1(book);
// List<Book> list = bookDao.list2(book);
PageBean pageBean=new PageBean();
//查第二页的数据 模拟从jsp传递页码2到后台
// pageBean.setPage(2);
//项目开发中,下拉框的需求,不分页 模拟从jsp传递不分页的信息pagination=false
pageBean.setPagination(false);
List<Book> list = bookDao.list3(book,pageBean);
for (Book b : list) {
System.out.println(b);
}
}
}
上面代码也有做测试
缺点总结:需要写大量重复代码
解决方案:
1、抽取变化部分作为参数:sql、Class
2、抽取公共的父类,把重复的代码剥离出来
通用分页,所有层的父类
package com.lsy.dao;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import com.lsy.entity.Book;
import com.lsy.util.DBAccess;
import com.lsy.util.PageBean;
import com.lsy.util.StringUtils;
/**
* 提供解决方案
1.抽取变化部分作为参数
2.抽取公共的父类,把重复性的代码剥离出来
* @author zjjt
*
*/
/**
* 所有Dao层的父类
* @author zjjt
*
* @param <T>
*/
public class BaseDao<T> {
public List<T> list(String sql,Class<T> clz) throws Exception{
//不确定list集合中装了什么东西 子类的Dao层会继承BaseDao<T>,子类传递什么类.class,那么list集合中放的就是什么
List<T> list=new ArrayList<T>();
Connection con=DBAccess.getConnection();
PreparedStatement pst = con.prepareStatement(sql);
ResultSet rs=pst.executeQuery();
while(rs.next()) {
// books.add(new Book(rs.getInt("bid"), rs.getString("bname"), rs.getFloat("price")));
/**
* 分析
* 1.实例化了一个对象
* 2.从resultset的对象的属性获取值,赋值给了前面的实例化对象
* 3.把已经赋值了的对象,添加到list集合中
*/
//Book b=new Book();
T t = clz.newInstance();
//2.从resultset的对象的属性获取值,赋值给了前面的实例化对象
Field[] fields = clz.getDeclaredFields();
for (Field f : fields) {
//打开访问权限
f.setAccessible(true);
f.set(t, rs.getObject(f.getName()));
}
list.add(t);
}
return list;
}
/**
* 通用分页查询
* @param sql
* @param clz
* @return
* @throws Exception
*/
public List<T> executeQuery(String sql,Class<T> clz,PageBean pageBean) throws Exception{
List<T> list=new ArrayList<T>();
Connection con=DBAccess.getConnection();
PreparedStatement pst = null;
ResultSet rs=null;
//是否需要分页?无需分页(项目中的下拉框,查询条件,教员下拉框)
//必须分页(项目中的列表类需求,订单列表,商品列表,学生列表.....)
if(pageBean != null && pageBean.isPagination()) {
//分页(列表需求)
String countSQL=getCountSQL(sql);
pst=con.prepareStatement(countSQL);
rs=pst.executeQuery();
if(rs.next()) {
pageBean.setTotal(String.valueOf(rs.getObject(1)));
}
//挪动到下面,是因为最后才处理返回的结果集
// sql=SELECT * FROM t_mvc_book WHERE bname like '%圣墟%'
// pageSql=sql limit (page-1)*rows,rows 对应某一页的数据
// countSql=select count(1) from (sql) t 符合条件的总记录数
String pageSQL=getPageSQL(sql,pageBean);//符合条件的某一页数据
pst=con.prepareStatement(pageSQL);
rs=pst.executeQuery();
}else {
//不分页(select需求)
pst=con.prepareStatement(sql);//符合条件的所有数据
rs=pst.executeQuery();
}
while(rs.next()) {
T t = clz.newInstance();
Field[] fields = clz.getDeclaredFields();
for (Field f : fields) {
f.setAccessible(true);
f.set(t, rs.getObject(f.getName()));
}
list.add(t);
}
return list;
}
/**
* 将原生SQL转换成符合条件的总记录数countSQL
* @param sql
* @return
*/
private String getCountSQL(String sql) {
// countSql=select count(1) from (sql) t;
return "select count(1) from ("+sql+") t";
}
/**
* 将原生SQL转换成pageSQL
* @param sql
* @param pageBean
* @return
*/
private String getPageSQL(String sql,PageBean pageBean) {
// TODO Auto-generated method stub
return sql + " limit "+pageBean.getStartIndex()+","+pageBean.getRows();
}
}
举例
package com.lsy.dao;
import java.util.List;
import com.lsy.entity.Acticle;
import com.lsy.util.PageBean;
import com.lsy.util.StringUtils;
public class ActicleDao extends BaseDao<Acticle>{
public List<Acticle> list(Acticle acticle) throws Exception{
return super.list("select * from t_jsoup_article", Acticle.class);
}
/**
* 文章的分页查询 1页展示5条
* @param args
* @throws Exception
*/
public List<Acticle> list2(Acticle acticle,PageBean pageBean) throws Exception{
String sql="select * from t_jsoup_article where 1=1";
String title=acticle.getTitle();
if(StringUtils.isNotBlank(title)) {
sql += " and title like '%"+title+"%'";
}
return super.executeQuery("select * from t_jsoup_article", Acticle.class,pageBean);
}
public static void main(String[] args) throws Exception {
ActicleDao acticleDao=new ActicleDao();
// List<Acticle> list=acticleDao.list(null);
Acticle a=new Acticle();
PageBean pageBean=new PageBean();
List<Acticle> list=acticleDao.list2(a,pageBean);
for (Acticle acticle : list) {
System.out.println(acticle);
}
}
}
PageBean
package com.lsy.util;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
/**
* 分页工具类
*
*/
public class PageBean {
private int page = 1;// 页码
private int rows = 10;// 页大小
private int total = 0;// 总记录数
private boolean pagination = true;// 是否分页
private String url;//保存上一次请求的URL
private Map<String, String[]> paraMap = new HashMap<>();//保存上一次请求的参数
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Map<String, String[]> getParaMap() {
return paraMap;
}
public void setParaMap(Map<String, String[]> paraMap) {
this.paraMap = paraMap;
}
/**
* 初始化pagebean的,保存上一次请求的重要参数
* @param req
*/
private void setRequest(HttpServletRequest req) {
// 1.1 需要保存上一次请求的URL
this.setUrl(req.getRequestURI().toString());
// * 1.2 保留上一次请求的参数 bname price
this.setParaMap(req.getParameterMap());
// * 1.3 需要保存上一次请求的分页设置 pagination
this.setPagination(req.getParameter("pagination"));
// * 1.4 需要保存上一次请求的条目数
this.setRows(req.getParameter("rows"));
// * 1.5 初始化请求的页码 page
this.setPage(req.getParameter("page"));
}
public void setPage(String page) {
if(StringUtils.isNotBlank(page)) {
this.setPage(Integer.valueOf(page));
}
}
public void setRows(String rows) {
if(StringUtils.isNotBlank(rows)) {
this.setRows(Integer.valueOf(rows));
}
}
public void setPagination(String pagination) {
//只要在前台jsp填写了pagination=false,才代表不分页
if(StringUtils.isNotBlank(pagination)) {
this.setPagination(!"false".equals(pagination));
}
}
public PageBean() {
super();
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
public int getRows() {
return rows;
}
public void setRows(int rows) {
this.rows = rows;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public void setTotal(String total) {
this.total = Integer.parseInt(total);
}
public boolean isPagination() {
return pagination;
}
public void setPagination(boolean pagination) {
this.pagination = pagination;
}
/**
* 获得起始记录的下标
*
* @return
*/
public int getStartIndex() {
return (this.page - 1) * this.rows;
}
/**
* 最大页
* @return
*/
public int maxPage() {
return this.total % this.rows==0? this.total / this.rows : this.total / this.rows + 1;
}
/**
* 下一页
* @return
*/
public int nextPage() {
//如果当前页小于最大一页,那么就说明下一页为当前页加1,如果不小于,说明当前页就是最大页,那就无需加1
return this.page < this.maxPage() ? this.page + 1 : this.page;
}
/**
* 上一页
* @return
*/
public int previousPage() {
return this.page>1 ? this.page - 1 : this.page;
}
@Override
public String toString() {
return "PageBean [page=" + page + ", rows=" + rows + ", total=" + total + ", pagination=" + pagination + "]";
}
}
MySQL分页关键字limit
Dao类
package com.lsy.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import com.lsy.entity.Book;
import com.lsy.util.DBAccess;
import com.lsy.util.PageBean;
import com.lsy.util.StringUtils;
public class BookDao extends BaseDao<Book>{
/**
* 简单的查询方法
* 1.建立数据库连接
* 2.预编译对象 preparestatement
* 3.查询结果集
* 4.处理结果集
*
* 分析不足之处 t_jsoup_article
* 1.换表查询以上步骤都需要重复
* 2.都是要返回数据库表对应的集合
* 集合中的对象都是不同的
* 3.都是要处理结果集
* 代码不一样,具体体现在,不同的表会有不同的字段,实体类对应的属性就会不一样
总结:需要写大量的重复代码,系统中的查询功能越多,重复代码量越大
提供解决方案
1.抽取变化部分作为参数
2.抽取公共的父类,把重复性的代码剥离出来
*/
public List<Book> list(Book book) throws Exception{
List<Book> books=new ArrayList<Book>();
String sql="select * from t_mvc_book where 1=1";
//书籍名称
String bname=book.getBname();
//书籍名称模糊查询 圣墟最终是前台jsp页面传过来的
if(StringUtils.isNotBlank(bname)) {
sql+=" and bname like '%"+bname+"%'";
}
Connection con=DBAccess.getConnection();
PreparedStatement pst = con.prepareStatement(sql);
ResultSet rs=pst.executeQuery();
while(rs.next()) {
books.add(new Book(rs.getInt("bid"), rs.getString("bname"), rs.getFloat("price")));
}
return books;
}
public List<Book> list2(Book book) throws Exception{
List<Book> books=new ArrayList<Book>();
String sql="select * from t_mvc_book where 1=1";
//书籍名称
String bname=book.getBname();
//书籍名称模糊查询 圣墟最终是前台jsp页面传过来的
if(StringUtils.isNotBlank(bname)) {
sql+=" and bname like '%"+bname+"%'";
}
return super.list(sql, Book.class);
}
/**
* 测试通用分页查询
* @param book
* @param pageBean
* @return
* @throws Exception
*/
public List<Book> list3(Book book,PageBean pageBean) throws Exception{
List<Book> books=new ArrayList<Book>();
String sql="select * from t_mvc_book where 1=1";
//书籍名称
String bname=book.getBname();
//书籍名称模糊查询 圣墟最终是前台jsp页面传过来的
if(StringUtils.isNotBlank(bname)) {
sql+=" and bname like '%"+bname+"%'";
}
return super.executeQuery(sql, Book.class, pageBean);
}
/**
* 思考:
* 在项目中大量的出现分页(订单列表,商品列表,学生列表.....)
* 目标:
* 想要做一个通用的分页查询,子类去继承父类,自带了分页功能
* 最终当碰到分页的需求的时候,只需要写少量的代码
* 实现:
* 1.mysql分页
* 分页通常有关键的因素,第page页,显示数目(rows),符合查询条件的总记录数(total)
* 2.编码思路
* 2.1原来list集合中返回的是符合条件的所有的数量
* 现在需要返回第page页的数据,那么意味着sql要加工成countSql
* 2.2需要分页,那么要求出符合条件的总记录数,保存到pagebean中
* 共N页的算法:total % rows ==0 ? total /rows :total / rows +1;
*
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
BookDao bookDao=new BookDao();
Book book=new Book();
book.setBname("圣墟");
// List<Book> list = bookDao.list1(book);
// List<Book> list = bookDao.list2(book);
PageBean pageBean=new PageBean();
//查第二页的数据 模拟从jsp传递页码2到后台
// pageBean.setPage(2);
//项目开发中,下拉框的需求,不分页 模拟从jsp传递不分页的信息pagination=false
pageBean.setPagination(false);
List<Book> list = bookDao.list3(book,pageBean);
for (Book b : list) {
System.out.println(b);
}
}
}
二、通用前台分页

PageTag
package com.lsy.tag;
import java.io.IOException;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.JspWriter;
import javax.servlet.jsp.tagext.BodyTagSupport;
import com.lsy.entity.PageBean;
import com.sun.org.apache.xml.internal.serializer.ToHTMLStream;
public class PageTag extends BodyTagSupport{
private PageBean pageBean=new PageBean();//包含所有分页相关的东西
//get/set方法
public PageBean getPageBean() {
return pageBean;
}
public void setPageBean(PageBean pageBean) {
this.pageBean = pageBean;
}
@Override
public int doStartTag() throws JspException {
//没有标签体,要输出内容
JspWriter out = pageContext.getOut();
try {
out.print(ToHTML());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return super.doStartTag();
}
private String ToHTML() {
StringBuffer sb=new StringBuffer();
// 隐藏的form表单--这个就是上一次请求下次重发的奥义所在
//上一次请求的url
sb.append("<form action='"+pageBean.getUrl()+"' id='pageBeanForm' method='post'>");
sb.append(" <input type='hidden' name='page'>");
//上一次请求的参数
Map<String, String[]> paramMap = pageBean.getParamMap();
if(paramMap!=null&¶mMap.size()>0) {
Set<Entry<String, String[]>> entrySet = paramMap.entrySet();
for (Entry<String, String[]> entry : entrySet) {
//参数名
String key=entry.getKey();
//参数值
String[] value = entry.getValue();
for (String values : value) {
//上一次请求的参数,再一次组装成了新的form表单
//注意:page参数每次都会提交,我们需要避免
if(!"page".equals(key)) {
sb.append(" <input type='hidden' name='"+key+"' value='"+values+"'>");
}
}
}
}
sb.append("</form>");
//分页条
sb.append("<ul class='pagination justify-content-center'>");
sb.append(" <li class='page-item "+(pageBean.getPage()==1?"disabled":"")+"'><a class='page-link'");
sb.append(" href='javascript:gotoPage(1)'>首页</a></li>");
sb.append(" <li class='page-item "+(pageBean.getPage()==1?"disabled":"")+"'><a class='page-link'");
sb.append(" href='javascript:gotoPage("+pageBean.previousPage()+")'><</a></li>");//上一页
//sb.append(" <li class='page-item'><a class='page-link' href='#'>1</a></li>");
//sb.append(" <li class='page-item'><a class='page-link' href='#'>2</a></li>");
sb.append(" <li class='page-item active'><a class='page-link' href='#'>"+pageBean.getPage()+"</a></li>");//第几页
sb.append(" <li class='page-item "+(pageBean.getPage()==pageBean.maxPage()?"disabled":"")+"'><a class='page-link' href='javascript:gotoPage("+pageBean.nextPage()+")'>></a></li>");//下一页
sb.append(" <li class='page-item "+(pageBean.getPage()==pageBean.maxPage()?"disabled":"")+"'><a class='page-link' href='javascript:gotoPage("+pageBean.maxPage()+")'>尾页</a></li>");//最大页
sb.append(" <li class='page-item go-input'><b>到第</b><input class='page-link'");
sb.append(" type='text' id='skipPage' name='' /><b>页</b></li>");
sb.append(" <li class='page-item go'><a class='page-link'");
sb.append(" href='javascript:skipPage()'>确定</a></li>");
sb.append(" <li class='page-item'><b>共"+pageBean.getTotal()+"</b></li>");
sb.append("</ul>");
//分页执行的JS代码
sb.append("<script type='text/javascript'>");
sb.append(" function gotoPage(page) {");
sb.append(" document.getElementById('pageBeanForm').page.value = page;");
sb.append(" document.getElementById('pageBeanForm').submit();");
sb.append(" }");
sb.append(" function skipPage() {");
sb.append(" var page = document.getElementById('skipPage').value;");
sb.append(" if (!page || isNaN(page) || parseInt(page) < 1 || parseInt(page) > "+pageBean.maxPage()+") {");//最大页码
sb.append(" alert('请输入1~"+pageBean.getTotal()+"的数字');");
sb.append(" return;");
sb.append(" }");
sb.append(" gotoPage(page);");
sb.append(" }");
sb.append("</script>");
return sb.toString();
}
}
标签库代码
标签库描述文件
<tag>
<name>Page</name>
<tag-class>com.mwy.tag.PageTag</tag-class>
<body-content>JSP</body-content>
<attribute>
<!-- 自定义标签的成员变量名称-->
<name>pageBean</name>
<!-- 该成员变量是否必传 -->
<required>true</required>
<!-- 是否支持EL表达式 -->
<rtexprvalue>true</rtexprvalue>
</attribute>
</tag>

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









