




 UltraSPARC T2处理器通过每个内核管理8个线程提升了性能,相比T1的4个线程有所增强。采用65nm工艺,包含5.03亿晶体管,工作频率1.4GHz。其核心结构包括两个整数执行管道、一个浮点执行管道和一个内存管道,线程被分为两组共享资源。在遇到长时间延迟如缓存缺失时,线程会被标记为不可用,并在延迟解决后继续执行。指令调度策略处理了潜在的硬件冒险和流水线冲突,确保了多线程间的高效协同。此外,处理器还包括用于密码学的流处理单元。
UltraSPARC T2处理器通过每个内核管理8个线程提升了性能,相比T1的4个线程有所增强。采用65nm工艺,包含5.03亿晶体管,工作频率1.4GHz。其核心结构包括两个整数执行管道、一个浮点执行管道和一个内存管道,线程被分为两组共享资源。在遇到长时间延迟如缓存缺失时,线程会被标记为不可用,并在延迟解决后继续执行。指令调度策略处理了潜在的硬件冒险和流水线冲突,确保了多线程间的高效协同。此外,处理器还包括用于密码学的流处理单元。
UltraSPARC T2
T2
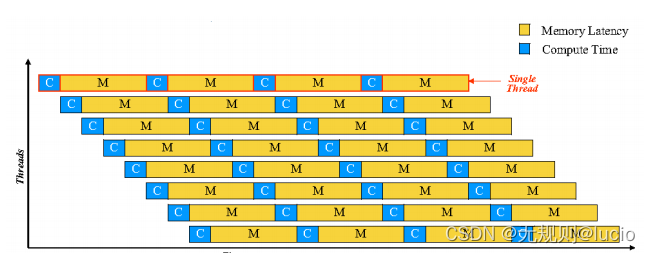
我们可以看到T2的吞吐量计算,对于一个线程来讲,memory延时才是真正改善性能的瓶颈。
T2的处理器比T1的处理器优化的一点是在原来基础上每个内核管理4个线程到每个内核管理8个线程,但是内核数保持不变。
采用了65 nm工艺,拥有5.03亿晶体管,工作频率1.4GHz。
T2 core
每个SPARC core支持八个线程,两个整数执行管道,一个浮点数执行管道,一个内存管道。
浮点和内存流水线被八个线程共享。八个线程分为两组,一组四个线程,一组的四个线程共享一个整数管道。
尽管八个线程同时运行,但是最多只有两个线程可以同时在物理内核中运行。 线程的切换是在硬分区的四个线程之间逐个循环切换,使用最近发出的最小优先级方案。
当strand 遇到了一个长延迟时间(比如缓存缺失),将被标记为不可用。指令直到长延时时间得以解决才从这个strand继续出发进行,继续执行剩余的可用线程。
每个物理核心还包含一个流处理单元(SPU),以加速密码学。
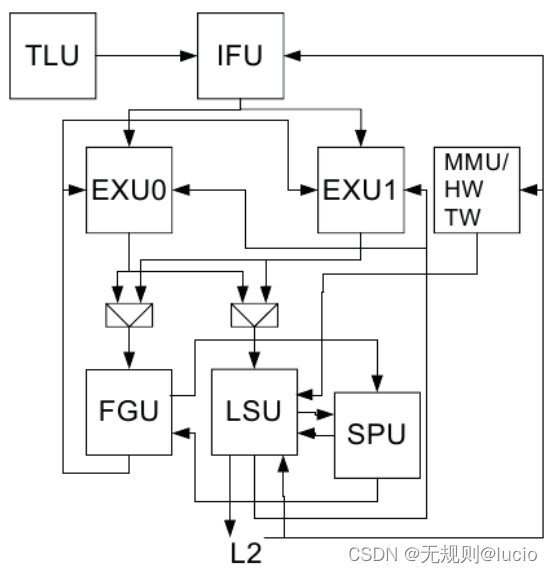
IFU Instruction Fetch Unit
EXU0/1 Integer Execution Units
LSU Load/Store Unit
FGU Floating-Point/Graphics Unit
SPU Stream Processing Unit/Cryptographic coprocessor
TLU Trap Logic Unit (Updates machine state, handles exceptions and interrupts)
MMU Memory Management Unit
T2 pipeline
整数流水线

浮点数流水线

T2 多线程(multithread)
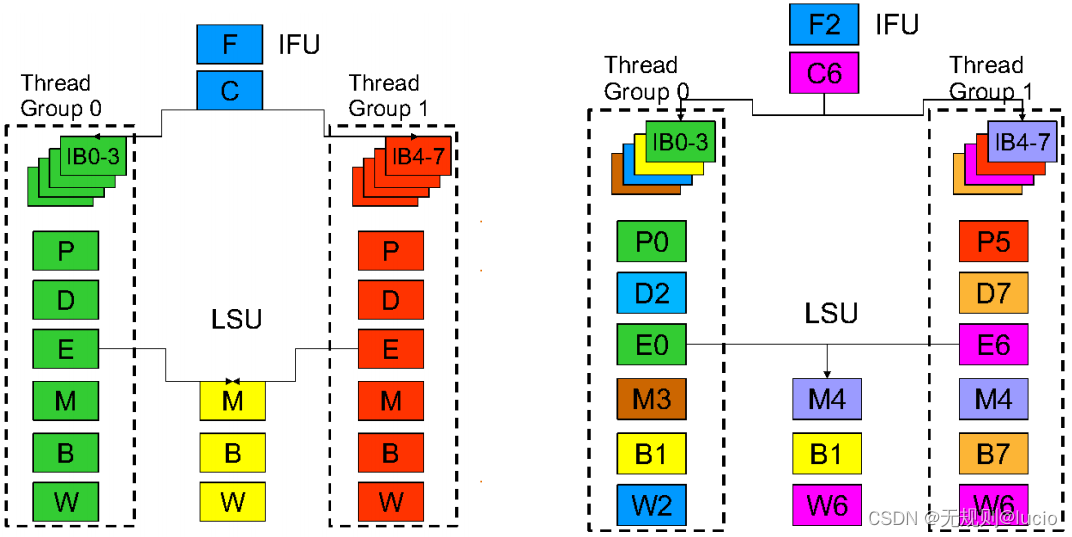
IFU 提供指令给剩余的内核。IFU产生PC和维护指令缓存。
IFU包含:fetch unit ,pick unit 和 decode unit。
IF:每周期fetch unit 一个线程可以最多获取4个指令。
Pick:pick unit是尝试在八个不同线程中找到两个要执行的指令,他们被分成两线程组(每四个线程一组):TG0和TG1。同一周期每个线程组各拿到一个FGU指令,但因为OpenSPARC T2 只有一个FGU,就会产生硬件冒险(harzard)。
Decode unit:decode unit 每周期从每个线程组解码一个指令。整数操作数从IRF读取,整数存储也是从IRF读取。会存在一些冒险:
- TG0和TG1指令同时需要LSU和FGU单元(storeFGU-storeFGU harzard)
- TG0和TG1指令同时需要LSU(load-load hazard)
- TG0和TG1指令同时需要FGU(FGU-FGU hazard)
- TG0和TG1其中一个为乘法,且乘法块滞留(stall)(乘法块hazard)
- TG0和TG1其中一个需要FGU单元,且PDIST块生效(PDIST块hazard)
在T2中,FGU执行所有的乘除法,指令调度(instruction scheduling)将这些操作FGU操作,同时也把MULSCC,POPC和像素比较识别为FGU操作。
LSU执行浮点加载(load)操作,指令调度就将这类操作视为load操作。
LSU和FGU都参加load操作。
而load-load hazard发生在当两指令同时解码时,且都需要LSU。这时解码单元需要两个周期来执行整数指令。
IRF和FRF各有两个写端口:W1和W2
所有的整数指令使用IRF的W1端口,其他不能在正常整数或浮点数管道执行的操作(比如,miss the dcache 和 整数除法)使用W2端口。
所有的浮点数指令使用FRF的W1端口,其他不能满足正常浮点管道的操作(像浮点load和浮点除法)使用W2端口。
整数操作在FGU执行并产生整数结果,在其中一条指令解码后的四个周期内,在始发线程组的整数管道中创建了一个孔。这个孔是通过阻止任何指令解码而产生的,整数结果在FB(floating bypass)期间通过IRF的W1写入。FGU整数指令在线程间进行流水线操作。这些操作的完成信号在bypass期间产生。

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









