




一、亲自体验
1.通过 Gemini 官网 (普通用户最推荐)
(1)访问 gemini.google.com。
(2)Gemini Advanced 订阅用户:通常可以立即使用最新的 Gemini 3 Pro 模型。请检查界面顶部的模型切换器,选择“Gemini Advanced”或查看是否有“Gemini 3”的选项。
(3)免费版用户:Google 可能会逐步向免费版推出 Gemini 3 的轻量化版本(如 Flash 版),或者您目前仍在使用 Gemini 2.5/2.0 Flash,具体取决于 Google 的推送策略。
2.通过 Google AI Studio (开发者/极客推荐)
- 如果您懂一点技术,可以访问 aistudio.google.com。
- 登录您的 Google 账号。
- 在右侧的“Model”下拉菜单中,您应该能看到 gemini-3-pro-preview 或类似的选项。
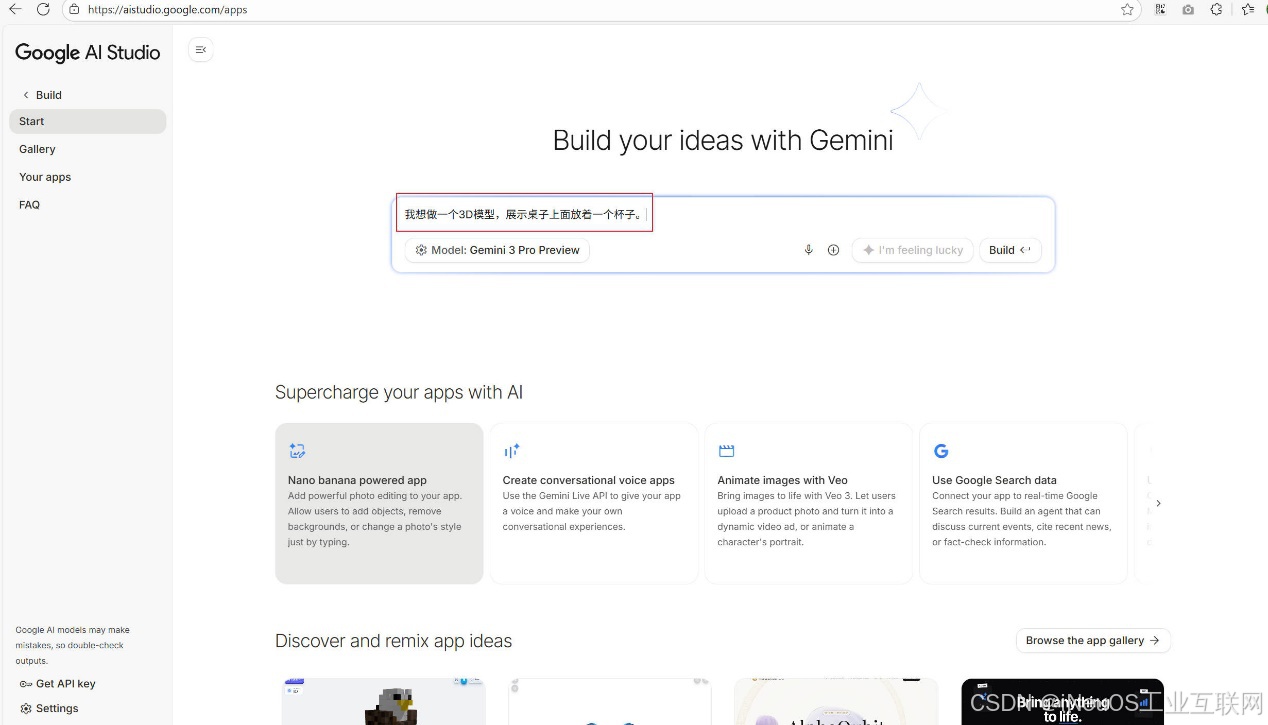
我们使用开发平台,输入提示词:我想做一个3D模型,展示桌子上面放着一个杯子。如下图:
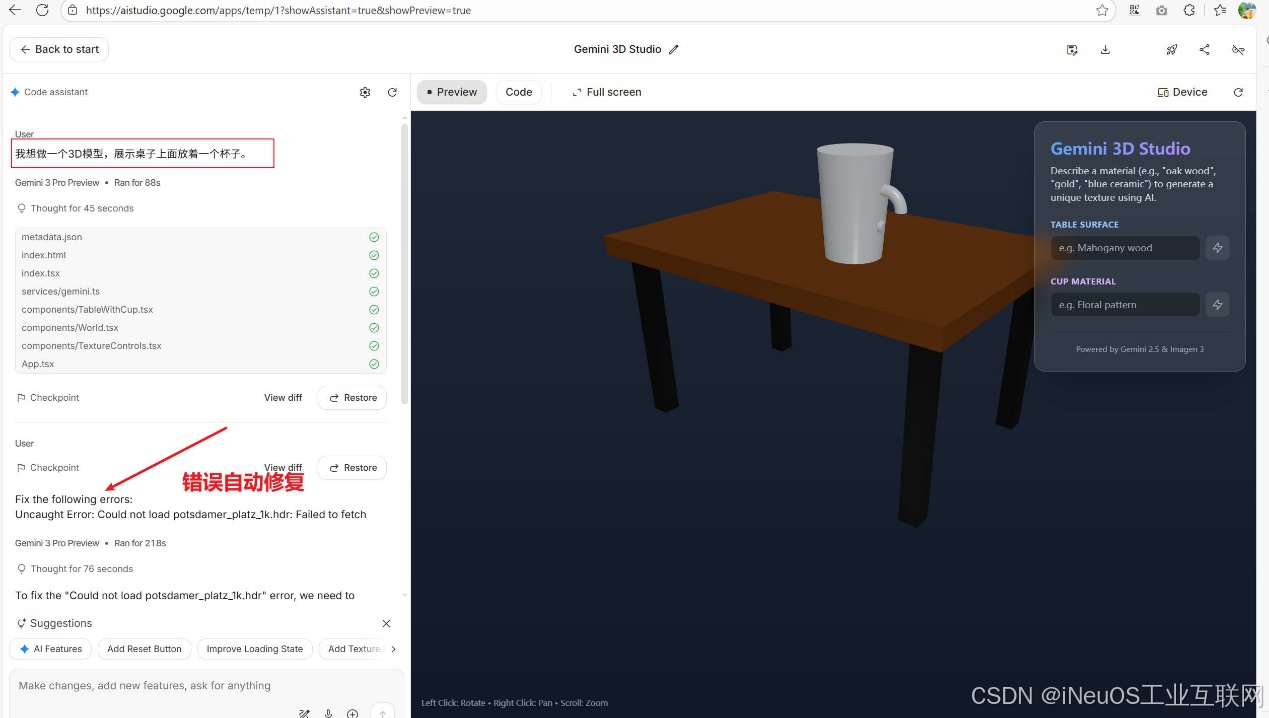
构建好的代码工程,如果发现有错误,会自动修复。如下图:
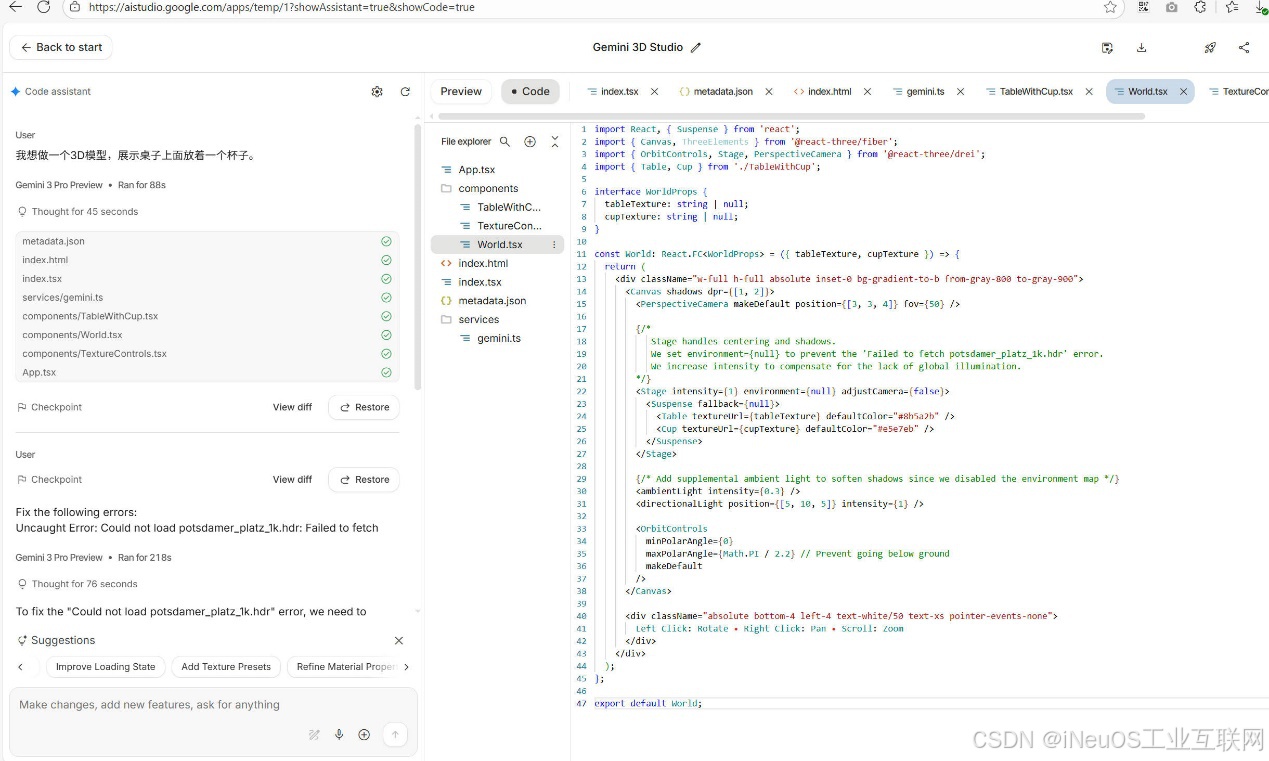
代码如下图:
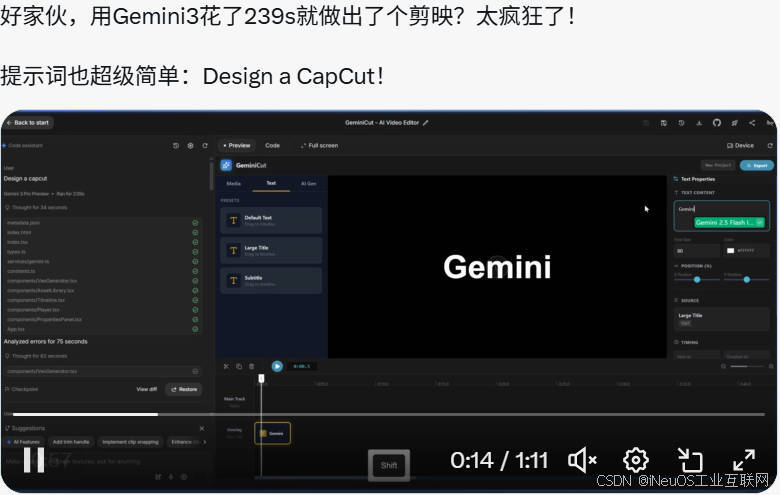
在X平台上也有很多各种测试,例如有利用Gemini3开发类似剪映的,如下图:
二、Gemini3介绍
基于 2025 年 11 月 18 日 Google 发布的最新技术白皮书和发布会内容,以下是对 Gemini 3 的全面深度介绍。
Gemini 3 被 Google 定义为从“通用大模型”向“通用代理(General Purpose Agent)”跨越的里程碑式版本。它不再仅仅是一个对话机器人,而是一个能感知、规划并代表用户执行复杂任务的智能体。
(1)核心架构与技术突破
原生多模态架构 (Native Any-to-Any)
与早期版本不同,Gemini 3 从训练之初就是完全端到端的多模态模型。
输入与输出:它可以同时接收文本、图像、音频、视频和代码输入,并能原生输出这些模态。
意味着什么:它不需要外挂TTS(语音合成)或画图模型。当你和它语音对话时,它直接“听”到声音的情感语调,并直接“生成”带有情感的声音,延迟低至 100ms 级,接近人类直觉反应。
1000万+ Token 上下文窗口 (Infinite Context)
Gemini 1.5 Pro 曾以 100-200 万 token 惊艳业界,Gemini 3 将标准版(Pro)的上下文窗口扩展到了 1000 万 tokens。
能力:它可以一次性“读”完一个季度的财报、观看长达 10 小时的视频素材、或分析整个大型软件项目的代码库,并保持极高的“大海捞针(Needle In A Haystack)”准确率。
动态计算(Dynamic Compute)
Gemini 3 引入了更智能的 MoE(混合专家)架构。它能根据问题的难易程度,动态[3][4]调动不同数量的参数。
效果:对于简单问题(如“今天天气”),它消耗极低能源;对于复杂逻辑(如“推导量子物理公式”),它会自动进入“深思模式(Deep Thinking)”,花费更多时间进行多步推理,显著减少了幻觉。
(2)四大核心特性
代理能力 (Agentic Workflow) —— 最大的亮点
这是 Gemini 3 与前代最大的区别。它具备了自主规划和工具使用的高级能力。
场景举例:你只需说“帮我策划下周去日本的旅行,预算2万,订好机票酒店并把行程加到日历。”
执行过程:Gemini 3 会自主拆解任务 -> 搜索航班 -> 浏览酒店评价 -> 对比价格 -> 调用 API 预订(需授权) -> 发送确认邮件 -> 写入 Google Calendar。全过程无需人工一步步干预。
视觉与物理世界理解
Gemini 3 的视觉能力不再局限于识别图片内容,它能理解物理规律和3D空间。
视频理解:它可以实时观看视频流,并回答关于视频中动作、因果关系的问题(例如:“为什么那个瓶子掉下来了?”)。
应用:这使得 Gemini 3 成为了机器人(Robotics)大脑的首选,能更好地指挥机械臂或导航。
- 长期记忆 (Episodic Memory)
Google 为 Gemini 3 引入了跨会话的长期记忆机制(用户可控)。
它不再是每次对话都重置的陌生人。它会记住你的编程习惯、饮食禁忌、家庭成员结构等。
当你下一次说“像上次一样写个 Python 脚本”时,它知道“上次”指的是什么风格。
逻辑与编程的飞跃
在 AlphaCode 技术的加持下,Gemini 3 在编程能力上达到了新高度。
它不仅仅是补全代码,而是能重构整个代码库、自动编写单元测试、并修复 Bug。在 HumanEval 和 SWE-bench 等基准测试中,Gemini 3 刷新了历史记录。


















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











