






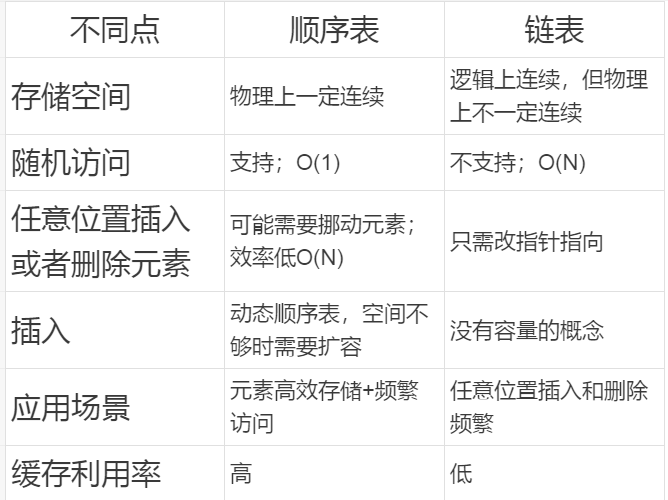
 本文讨论了顺序表和链表在缓存利用率上的差异,指出顺序表由于连续存储和较高的缓存命中率,使得CPU访问更有效率,而链表的非连续存储导致访问命中率较低,可能造成缓存污染和空间浪费。
本文讨论了顺序表和链表在缓存利用率上的差异,指出顺序表由于连续存储和较高的缓存命中率,使得CPU访问更有效率,而链表的非连续存储导致访问命中率较低,可能造成缓存污染和空间浪费。
关于缓存利用率
顺序表扩容有代价,可能用不完,造成空间浪费。但是为什么顺序表的缓存利用率是高于链表的呢?
这就涉及到cpu访问数据时的过程了。
计算机的存储是分层的。大致如下
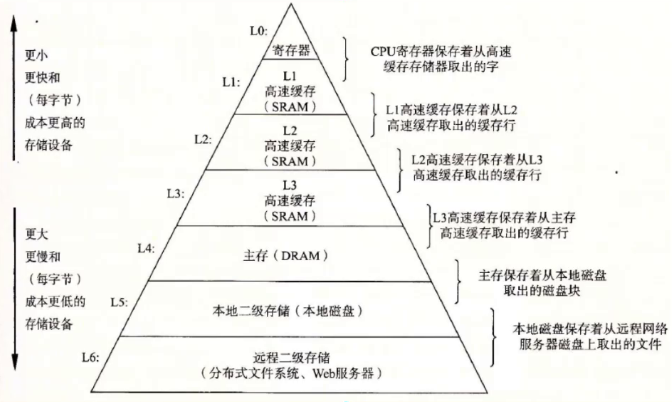
其中L3以上的存储可以分为一部分,他们都是围绕cpu周围的。
而平时的数据一般在L4主存中,叫第二层。而所谓的数据结构就是管理内存中的数据。cpu要处理数据就会从内存中读取数据。但是cpu太快了,内存会跟不上。于是就有了寄存器和缓存。这两读取数据就会快很多。所以cpu会先看缓存中有没有要的数据,没有就优先加载数据到缓存中。
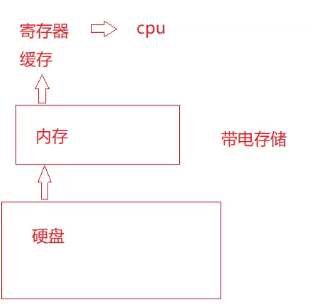
内存是带点存储,而硬盘不需要带电就能存储。如果没有保存到硬盘中,掉电就会失去数据。比如你写代码,写着写着断电了,但是没存到硬盘,那就完蛋蛋了。
接着来解释缓存利用率。
cpu处理数据时会优先在缓存中查找数据,如果数据在缓存中,就叫访问命中。
如果不在缓存,就会把数据先加载到缓存中。
而cpu一访问就会加载一段数据。比如要访问4个字节,但是cpu会直接加载16个字节(不一定这么多,只是举例子)因为cpu只加载4个字节和加载几十个字节的成本是一样的。cpu访问这些数据是通过数据总线的。而这就好像开大巴去接人,一辆大巴坐4个人和16个人的成本是一样的。
访问四个数字,访问顺序表的话就要将一长段顺序表加载下来,如果第一个数据不是要访问的,就叫没有命中 ,但是因为顺序表是连续存储,所以往后遍历,很快就能和找到所要的数据,也就是访问命中。而链表的存储在空间上不是连续的,访问命中率低。而且链表还可能造成缓存污染。比如一辆大巴要拉一个班的4个人去体检,但是大巴直接拉了一个班的一大半人,完了到医院发现那四个人没拉上。这就造成资源的浪费了。回到缓存中就是,加载了一堆数据,但是就是没找到需要的链表的数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









