




配置pom
Maven地址
https://mvnrepository.com/tags/maven
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>出现bug

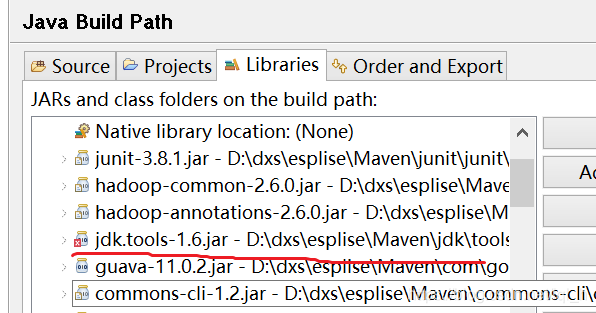
解决bug
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>C:/Program Files/Java/jdk1.8.0_74/lib/tools.jar</systemPath>
</dependency>代码
地址
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Windows运行
将hadoop补丁路径配置到环境变量
变量名:HADOOP_HOME
变量值:D:\buding\hadoop-2.6.0
变量名:Path
变量值:C:\ProgramData\Oracle\Java\javapath;%HADOOP_HOME%\bin
将文件复制到System32下
hadoop.dll
hinutils
将log4j.properties复制到源目录resources下

Run Configurations
MainClass:com.pcitc.hdfs.Test
Program arguments:D:\data\wc.txt D:\data\out
运行效果
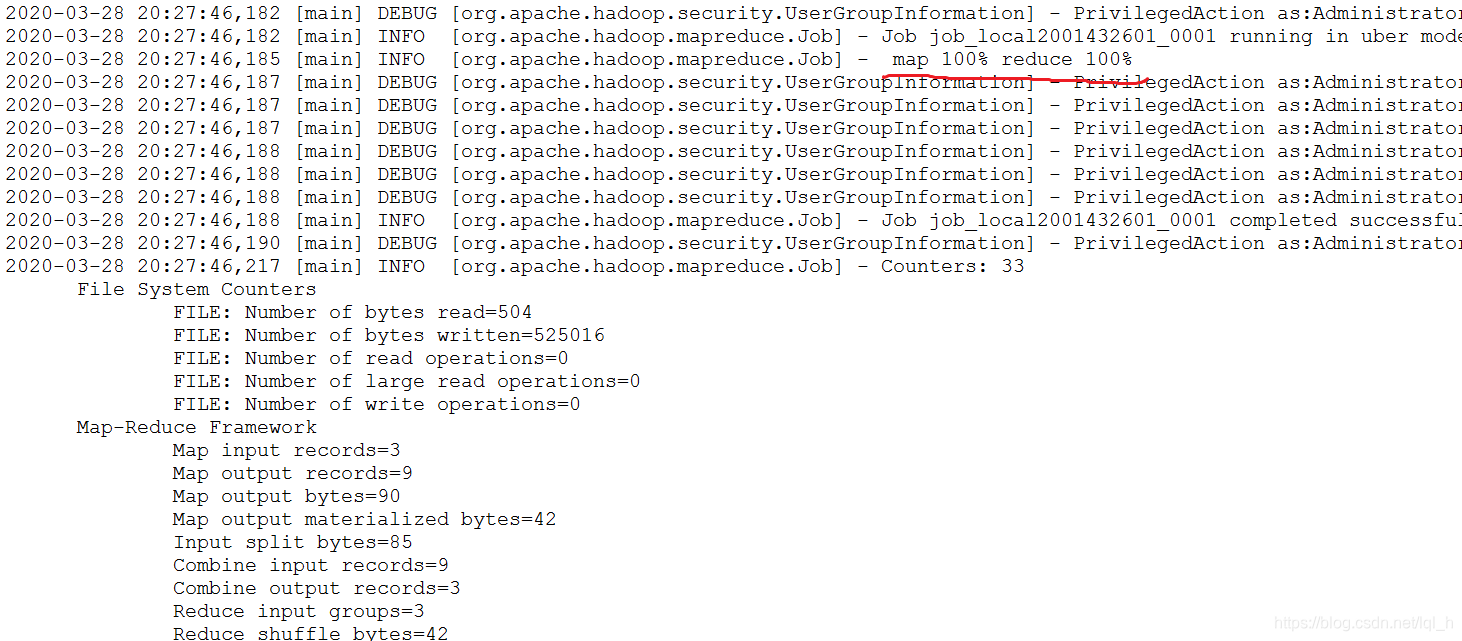
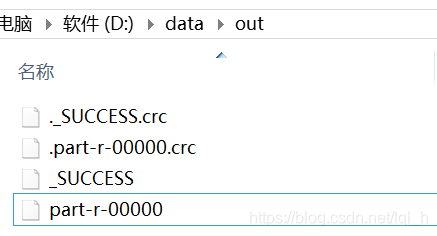
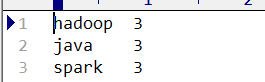
Linux运行
打包上传
Run as -> aven install
运行查看
bin/hadoop jar /root/app/hadoop-0.0.1-SNAPSHOT.jar com.pcitc.hadoop.WordCount /test/wd.txt /test/output2
bin/hdfs dfs -cat /test/output2/*
通过maven管理多个MapReduce
查找源码搜hadoop
ExampleDriver源码地址
配置maven-shade-plugin插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<manifestEntries>
<Main-Class>com.pcitc.hadoop.ExampleDriver</Main-Class>
<X-Compile-Source-JDK>${maven.compile.source}</X-Compile-Source-JDK>
<X-Compile-Target-JDK>${maven.compile.target}</X-Compile-Target-JDK>
</manifestEntries>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build> 源码
import org.apache.hadoop.util.ProgramDriver;
/**
* A description of an example program based on its class and a
* human-readable description.
*/
public class ExampleDriver {
public static void main(String argv[]){
int exitCode = -1;
ProgramDriver pgd = new ProgramDriver();
try {
pgd.addClass("wordcount", WordCount.class,
"A map/reduce program that counts the words in the input files.");
exitCode = pgd.run(argv);
}
catch(Throwable e){
e.printStackTrace();
}
System.exit(exitCode);
}
}
[root@cdh1 hadoop]# bin/hadoop jar /root/app/hadoop-0.0.2-SNAPSHOT.jar wordcount /test/wd.txt /test/output3运行查看
bin/hdfs dfs -cat /test/output3/*

















 2671
2671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









