



第一次使用yolov8跑出错了。具体错误如截图所示: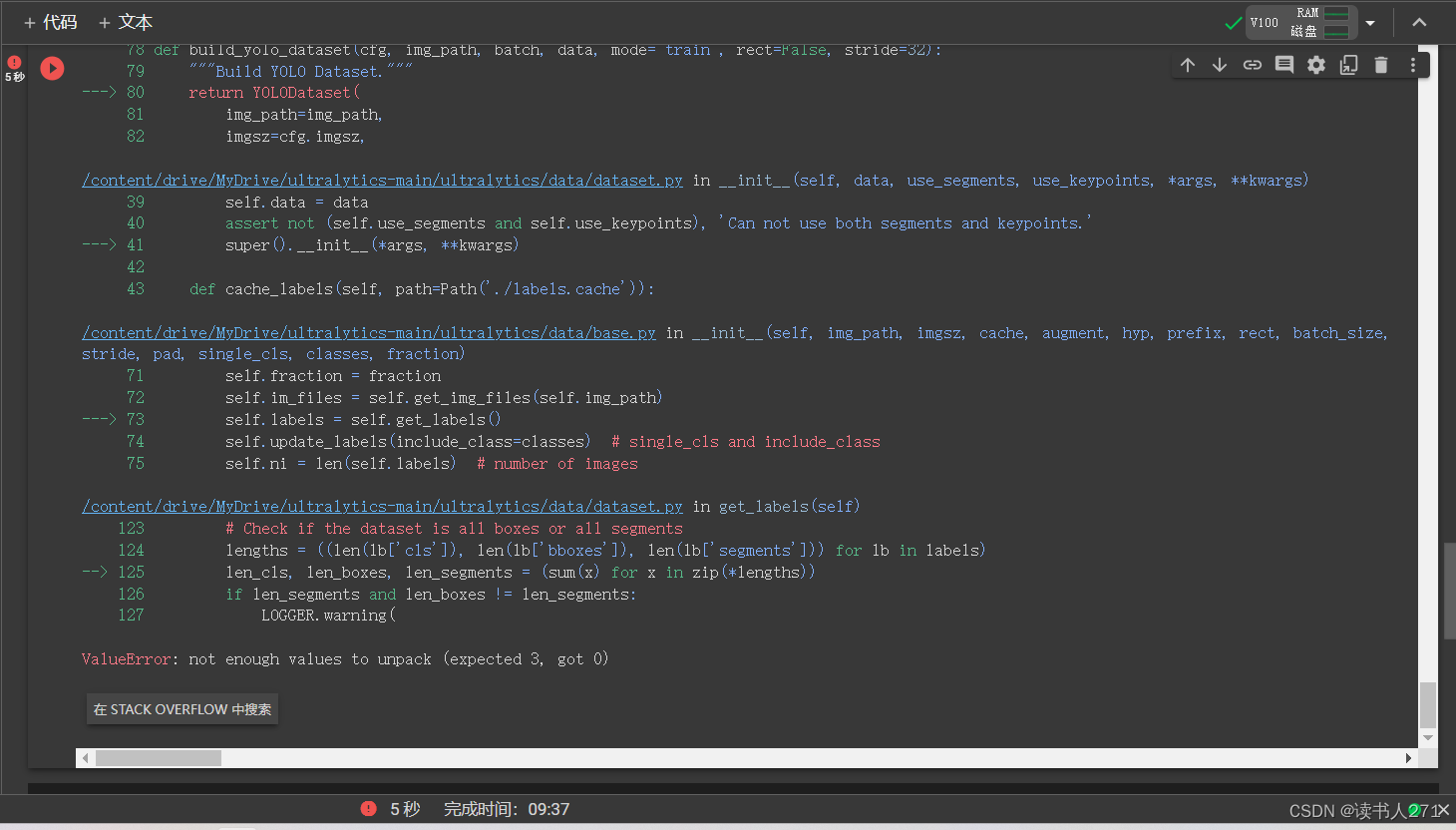
暂时还没找到很好的解决方法,看到网上有博客说是官方最新代码有误(我的日期为2023.10.24下载),等我回退版本后跑一下再来反馈。
 用户在使用Yolov8时遇到错误,怀疑是由于最新官方代码的问题。他们计划回退到旧版本进行测试并反馈结果。
用户在使用Yolov8时遇到错误,怀疑是由于最新官方代码的问题。他们计划回退到旧版本进行测试并反馈结果。
第一次使用yolov8跑出错了。具体错误如截图所示:
暂时还没找到很好的解决方法,看到网上有博客说是官方最新代码有误(我的日期为2023.10.24下载),等我回退版本后跑一下再来反馈。
您可能感兴趣的与本文相关的镜像

Yolo-v5
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的Joseph Redmon 和Ali Farhadi 开发。 YOLO 于2015 年推出,因其高速和高精度而广受欢迎
 916
3797
2936
1544
916
3797
2936
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























