




MonoScene:基于单目RGB图像的3D语义场景补全框架
摘要
论文地址: https://arxiv.org/abs/2112.00726
论文仓库地址: https://github.com/astra-vision/MonoScene
原文: MonoScene proposes a 3D Semantic Scene Completion (SSC) framework, where the dense geometry and semantics of a scene are inferred from a single monocular RGB image. Different from the SSC literature, relying on 2.5 or 3D input, we solve the complex problem of 2D to 3D scene reconstruction while jointly inferring its semantics. Our framework relies on successive 2D and 3D UNets, bridged by a novel 2D3D features projection inspired by optics, and introduces a 3D context relation prior to enforce spatio-semantic consistency. Along with arci9tectural contributions, we introduce novel global scene and local frustums losses. Experiments show we outperform the literature on all metrics and datasets while hallucinating plausible scenery even beyond the camera field of view. Our code and trained models are available at https://github.com/cv-rits/MonoScene.
翻译: 本文提出了一种单目3D语义场景补全(SSC)框架,能够从单一单目RGB图像推断场景的稠密几何结构与语义信息。与现有依赖2.5D或3D输入的SSC研究不同,我们通过联合推理语义与三维重建,解决了从2D到3D场景重建的复杂问题。该框架的核心在于: 级联的2D-3D UNet结构,通过受光学启发的新型2D-3D特征投影模块实现跨维度特征传递;3D上下文关系先验,用于强化空间-语义一致性;创新的损失函数设计(全局场景损失与局部视锥体损失)。实验表明,本方法在所有指标和数据集上均超越现有技术,并能生成超出摄像机视野的合理场景推测。代码与训练模型已开源:https://github.com/cv-rits/MonoScene.
注:
1. 2.5D传感器是获取物体表面的深度信息(即每个点到传感器的距离),但数据是从单一视角采集的,无
法还原物体的完整三维结构。只能看到物体朝向传感器的一面,背面或侧面信息缺失。类似于“2D图像+深度”,
形成深度图(Depth Map)。
2. 3D传感器能获取物体的完整三维几何信息(X/Y/Z坐标),通常通过多视角扫描或主动投射结构化光实
现,可重建物体的360°模型。如:工业CT扫描、激光雷达(LiDAR)、结构光扫描仪。
1. 引言
原文: Estimating 3D from an image is a problem that goes back to the roots of computer vision [54]. While we, humans, naturally understand a scene from a single image, reasoning all at once about geometry and semantics, this was shown remarkably complex by decades of research [57, 75, 80]. Subsequently, many algorithms use dedicated depth sensors such as Lidar [36, 50, 62] or depth cameras [2, 15, 19], easing the 3D estimation problem. These sensors are often more expensive, less compact and more intrusive than cameras which are widely spread and shipped in smartphones, drones, cars, etc. Thus, being able to estimate a 3D scene from an image would pave the way for new applications.
翻译: 从单张图像估计三维信息是一个可以追溯到计算机视觉起源领域的问题[54]。尽管人类能够自然地通过单幅图像理解场景,同时对几何结构和语义信息进行综合推理,但数十年的研究[57,75,80]表明这一过程具有惊人的复杂性。因此,许多算法转而采用专用深度传感器(如激光雷达[36,50,62]或深度相机[2,15,19])来简化三维估计问题。但这些传感器往往比广泛配置于智能手机、无人机、汽车等设备的摄像头成本更高、体积更大且更具侵入性。因此,实现从单幅图像估计三维场景的能力将开拓诸多新应用领域。
原文: 3D Semantic Scene Completion (SSC) addresses scene understanding as it seeks to jointly infer its geometry and semantics. While the task gained popularity recently [56], the existing methods still rely on depth data (i.e. occupancy grids, point cloud, depth maps, etc.) and are custom designed for either indoor or outdoor scenes.
翻译: 三维语义场景补全(SSC)致力于通过联合推断场景的几何结构与语义信息来实现场景理解。尽管该任务近年来备受关注[56],但现有方法仍依赖于深度数据(如占据栅格、点云、深度图等),且通常仅针对室内或室外场景进行专门设计。
原文: Here, we present MonoScene which – unlike the literature – relies on a single RGB image to infer the dense 3D voxelized semantic scene working indifferently for indoor and outdoor scenes. To solve this challenging problem, we project 2D features along their line of sight, inspired by optics, bridging 2D and 3D networks while letting the 3D network self-discover relevant 2D features. The SSC literature mainly relies on cross-entropy loss which considers each voxel independently, lacking context awareness. We instead propose novel SSC losses that optimize the semantic distribution of group of voxels, both globally and in local frustums. Finally, to further boost context understanding, we design a 3D context layer to provide the network with a global receptive field and insights about the voxels semantic relations. We extensively tested MonoScene on indoor and outdoor, see Fig. 1, where it outperformed all comparable baselines and even some 3D input baselines. Our main contributions are summarized as follows.
• MonoScene: the first SSC method tackling both outdoor and indoor scenes from a single RGB image.
• A mechanism for 2D Features Line of Sight Projection bridging 2D and 3D networks (FLoSP, Sec. 3.1).
• A 3D Context Relation Prior (3D CRP, Sec. 3.2) layer that boosts context awareness in the network.
• New SSC losses to optimize scene-class affinity (Sec. 3.3.1) and local frustum proportions (Sec. 3.3.2).
翻译: 本文提出的MonoScene与现有研究不同,它仅需单张RGB图像即可推断稠密的三维体素化语义场景,并同时适用于室内外场景。针对这一挑战性问题,我们受光学原理启发,将二维特征沿视线方向投影,在连接二维与三维网络的同时,使三维网络能自主发现关键的二维特征。现有语义场景补全研究主要依赖逐体素独立计算的交叉熵损失,缺乏上下文感知能力。为此,我们提出新型语义场景补全损失函数,从全局和局部视锥两个层面优化体素群的语义分布。此外,为增强上下文理解能力,我们设计了三维上下文关联层,使网络具备全局感受野并理解体素间的语义关联。如图1所示,MonoScene在室内外场景的广泛测试中均超越所有可比基线方法,甚至优于部分基于三维输入的基线。主要贡献如下:
• MonoScene框架:首个通过单目RGB图像实现室内外场景统一处理的语义场景补全方法
• 视线投影机制(FLoSP,第3.1节):通过二维特征视线投影桥接二维与三维网络
• 三维上下文关联先验层(3D CRP,第3.2节):增强网络上下文感知能力
• 新型损失函数:包含场景类别亲和度优化(第3.3.1节)与局部视锥比例优化(第3.3.2节)。

2. 网络结构
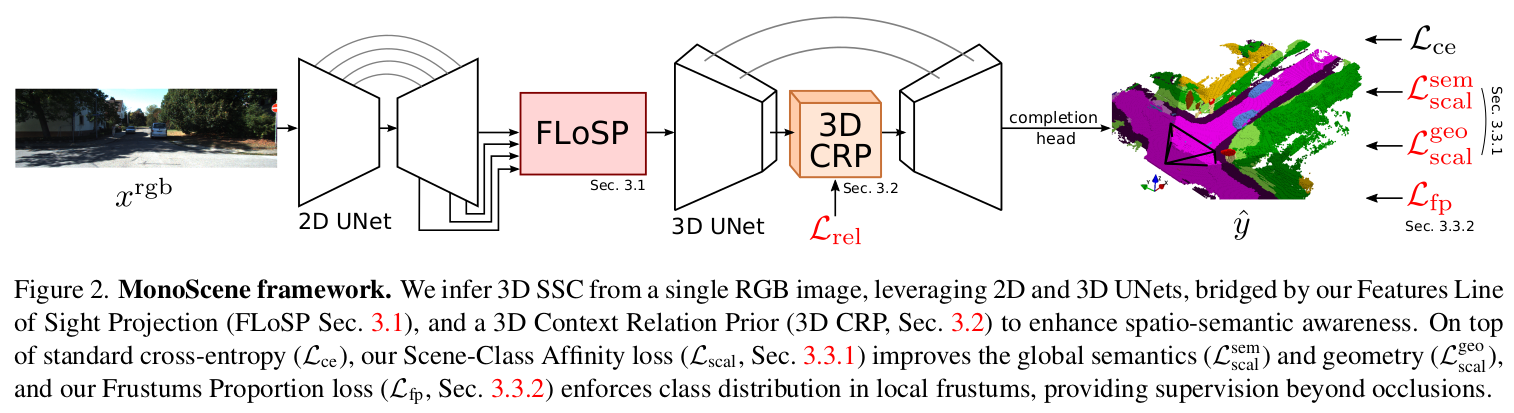
输入为单帧的 RGB 图像,首先经过 2D Unet 提取不同分辨率下的图像特征;接着通过 FLoSP(Features Line of Sight Projection)模块,将 2D 特征转换为 3D 特征;再通过 3D Unet 加强深度维度之间的联系,在其中插入 3D CRP(Context Relation Prior)模块用来提升空间语义的响应能力;最后在补全头(Completion head)中输出 3D 语义。
3. 创新点
• 视线投影机制(FLoSP):通过二维特征视线投影桥接二维与三维网络
• 三维上下文关联先验层(3D CRP):增强网络上下文感知能力
• 新型损失函数:包含场景类别亲和度优化与局部视锥比例优化。
接下来就对应代码,看一下论文的创新点
3.1 FLoSP
主要通过相机内参将已经划分好的3D网格中心,投影到2D图像上的位置,再通过位置反向将2D特征赋值给3D网格。当然作者也是将不同尺度的2D特征图做了投影
class FLoSP(nn.Module):
def __init__(self, scene_size, dataset, project_scale):
super().__init__()
self.scene_size = scene_size # 3D场景的物理尺寸 (长、宽、高)
self.dataset = dataset # 使用的数据集名称 ("NYU"或"kitti")
self.project_scale = project_scale # 投影比例因子,控制3D体素的下采样率
def forward(self, x2d, projected_pix, fov_mask):
# unet2d 网络有多个不同尺度的特征图(体现在输入时的降采样)
c, h, w = x2d.shape
# 展平特征图 (c, h*w)
src = x2d.view(c, -1)
zeros_vec = torch.zeros(c, 1).type_as(src)
# 拼接零向量 (c, h*w+1),那么索引为h*w的元素为0
src = torch.cat([src, zeros_vec], 1)
# projected_pix是从vox2pix函数得到的投影像素坐标,形状为 (N, 2)
# N 为网格数量,且projected_pix的行索引为网格展平索引
pix_x, pix_y = projected_pix[:, 0], projected_pix[:, 1]
# 将2D坐标转换为1D线性索引 img_indices是一个数组(数组长度是网格总数,数组元素为图片上的索引)
img_indices = pix_y * w + pix_x
# fov 之外的mask 都标记为无效值 h*w fov_mask 其实也是一维数组了
img_indices[~fov_mask] = h * w
# expand(c, -1) 将索引扩展为 (c, N)
# .long() 转换为整数类型,用于索引
# 将img_indices 重复复制c份,达到c维度
img_indices = img_indices.expand(c, -1).long() # c, HWD
# torch.gather根据img_indices从src中收集特征,形状为(C, N)。
# 特征保留:2D特征图中的空间信息被"重排"到3D空间中,但特征值本身不变,只是位置重组
# 多个3D体素可能投影到同一个2D像素位置,这些体素将获得相同的特征值(在各自通道)
# 类似src_feature[i, j] = src[i, img_indices[i, j]]
# 这里我们可以理解i为通道,j为数组索引,也是为网格总数相同
# src_feature的维度应该和img_indices维度相同
src_feature = torch.gather(src, 1, img_indices)
if self.dataset == "NYU":
x3d = src_feature.reshape(
c,
self.scene_size[0] // self.project_scale,
self.scene_size[2] // self.project_scale,
self.scene_size[1] // self.project_scale,
)
x3d = x3d.permute(0, 1, 3, 2)
elif self.dataset == "kitti":
x3d = src_feature.reshape(
c,
self.scene_size[0] // self.project_scale,
self.scene_size[1] // self.project_scale,
self.scene_size[2] // self.project_scale,
)
return x3d
# 网格中心点转到相机坐标系
def vox2world(vol_origin, vox_coords, vox_size, offsets=(0.5, 0.5, 0.5)):
"""Convert voxel grid coordinates to world coordinates."""
vol_origin = vol_origin.astype(np.float32)
vox_coords = vox_coords.astype(np.float32)
# print(np.min(vox_coords))
cam_pts = np.empty_like(vox_coords, dtype=np.float32)
for i in prange(vox_coords.shape[0]):
# x y z 三格坐标
for j  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1902
1902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









