



AWK 介绍
功能: 报告生成器,模式化文本输出,同时也是一门语言:模式扫描和处理语言
一、awk的基本语法概念
-
awk [options] 'program' var=value file… -
awk [options] -f programfile var=value file… -
awk [options] 'BEGIN{action;… }pattern{action;… }END{action;… }' file ...- program通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块,共3部分组成,通常放置于单引号或双引号中
- program格式:BEGIN{ action;… } pattern{ action;… } END{ action;… }
- pattern:决定动作语句何时触发及触发事件
- action statements:对数据进行处理,放在{}内指明
-
选项
- -F:指明输入时用到的字段分隔符,默认以空格作为分隔符
- -v var=value:自定义变量
-
分隔符、域、记录
- 文件的每一行称为记录,每一列称为字段(域)
- awk执行时,由分隔符分隔的字段(域)称为域标识,标记为$1, $2…$n,$0为所有域。
- 注意:此处的$ 与shell中变量 $ 符号含义不同
- 省略action,则默认执行print $0 的操作
二、awk的工作原理
- 第一步:执行BEGIN{action;…}语句
- BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
- 第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
- pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print $0 },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
- 第三步:当读至输入流末尾时,执行END{action;…}语句块
- END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
三、print语句
语法:print item1,item2,…
- 逗号分隔符
- 输出的item可以字符串,也尅是数值;当前记录的字段、变量或者awk的表达式
- 省略item,相当于print $0
示例如下:
awk '{print "hello word"}'
#等待标准输入,每一行后面追加“hello word”
awk '{print}' /etc/passwd
#打印 /etc/passwd的每一行
awk '{print "yijie"}' /etc/passwd
#每读入/etc/passwd一行,就打印一行“yijie”
awk -F: '{print $1}' /etc/passwd
#以":"为分隔符,打印/etc/passwd每一行的第一列
awk -F: '{print $0}' /etc/passwd
#逐条打印/etc/passwd
awk -F: '{print $1,$3}' /etc/passwd
#以":"为分割符,打印/etc/passwd每一行的第一列 第三列,以空格作为分隔符输出
awk -F: '{print $1"\n"$3}' /etc/passwd
#以":"为分隔符,打印/etc/passwd每一行的第一列,第三列,以制表符为分隔符输出
tail -3 /etc/fstab | awk '{print $2,$4}'
#以默认空格作为分隔符,打印 /etc/fstab的后三行,其中每一行的第二列 第四列
grep '^UUID' /etc/fstab | awk '{print $2,$4}'
#/etc/fstab中以“UUID”开头的行传递给awk,然后以空格符作为分隔符打印每一行的第二列和第四列
AWK 变量
一、内置变量
- FS:输入字段分隔符,默认为空白字符,可以在program中引用
awk -v FS=':' '{print $1,FS,$3}' /etc/passwd
awk -v FS=':' '{print $1FS$3}' /etc/passwd
注意二者区别,print里面的一个逗号代表一个空格 - awk变量也可以引用Shell变量,便于脚本编写
fs=":";awk -v FS=$fs '{print $1,FS,$4}' /etc/passwd
[root@Centos7 ~]#fs=":" ; awk -v FS=$fs '{print $1,FS,$4}' /etc/passwd
root : 0
bin : 1
daemon : 2
adm : 4
lp : 7
sync : 0
- OFS:输出字段分隔符,默认为空白字符
awk -v FS=":" -v OFS="|" '{print $1,$3,$7}' /etc/passwd
```bash
[root@Centos7 ~]#awk -v FS=":" -v OFS="|" '{print $1,$3,$7}' /etc/passwd
root|0|/bin/bash
bin|1|/sbin/nologin
daemon|2|/sbin/nologin
adm|3|/sbin/nologin
```
-
RS:输入记录分隔符,指定输入时的换行符,原换行符仍有效
awk -v RS=":" '{print $1}' /etc/passwd
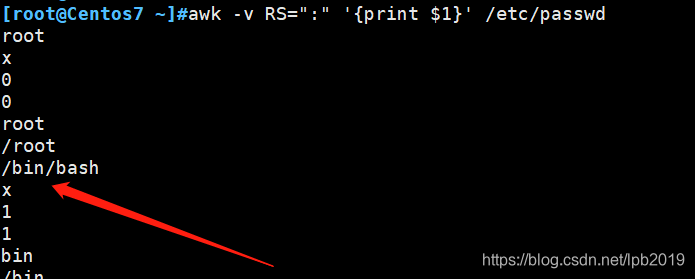
- 注意到当指定以":"作为记录分隔符时,输出每条记录的第1个字段时,除了第1条记录外,其他记录的用户名信息都丢失了。
- 原因在于文件每一行行尾的换行符,当指定其他符号为记录分隔符后,其自身的换行功能得到保留,所以每一行行尾的shell信息和下一行的用户名信息被视作为一条记录,而记录的第一个字段为bash信息,用户名信息没有打印。

-
ORS:输出记录分隔符,输出时用指定符号代替换行符
awk -v RS=":" -v OFS="###" '{print }' /etc/passwd

-
NF:字段数量
awk '{print NF,$0}' /etc/fstab,打印 /etc/fstab 的每一行并在行首标明所在行的字段总数量(以空格符为字段分隔符)
[root@Centos7 ~]#awk '{print NF,$0}' /etc/fstab 0 1 # 2 # /etc/fstab 10 # Created by anaconda on Fri Oct 11 19:26:48 2019 1 # 9 # Accessible filesystems, by reference, are maintained under '/dev/disk' 12 # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info 1 # 6 UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 / xfs defaults 0 0 6 UUID=3b5ca6bb-0d70-4b40-970b-ec57424622bf /boot xfs defaults 0 0 6 UUID=f5d9456c-83cd-4b48-81a6-2819b851d1d8 /data xfs defaults 0 0 6 UUID=4b4a8a3d-f232-42ac-908c-bec4ef59d7b0 swap swap defaults 0 0awk -F: '{print $(NF-1)}' /etc/passwd打印以":"为分隔符,每一行倒数第二个字段
[root@Centos7 ~]#awk -F: '{print $(NF-1)}' /etc/passwd /root /bin /sbin /var/adm /var/spool/lpd /sbin -
NR:行号
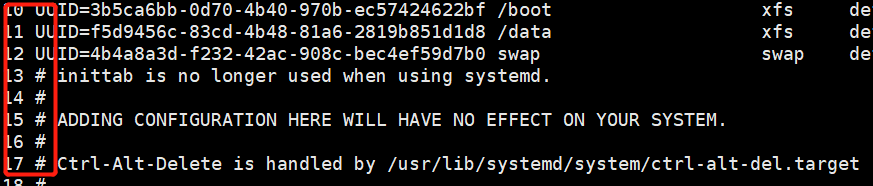
awk '{print NR,$0}' /etc/fstab打印每一行的内容以及前面带上行号
[root@Centos7 ~]#awk '{print NR,$0}' /etc/fstab 1 2 # 3 # /etc/fstab 4 # Created by anaconda on Fri Oct 11 19:26:48 2019 5 # 6 # Accessible filesystems, by reference, are maintained under '/dev/disk' 7 # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info 8 # 9 UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 / xfs defaults 0 0 10 UUID=3b5ca6bb-0d70-4b40-970b-ec57424622bf /boot xfs defaults 0 0 11 UUID=f5d9456c-83cd-4b48-81a6-2819b851d1d8 /data xfs defaults 0 0 12 UUID=4b4a8a3d-f232-42ac-908c-bec4ef59d7b0 swap swap defaults 0 0awk '{print NR,$0}' /etc/fstab /etc/inittab可以同时打印多个文件,但是行号是连续的
-
FNR:各文件分别计数,行号
awk '{print FNT,$0}' /etc/fstab /etc/inittab

-
FILENAME:当前文件名
[root@Centos7 ~]#awk '{print FILENAME}' /etc/fstab
/etc/fstab
/etc/fstab
/etc/fstab
- ARGC:命令行参数的个数
awk 'BEGIN {print ARGC}' /etc/fstab /etc/inittab,下图每一个红框代表一个参数

- ARGV:数组,保存的是命令行所给定的各参数
awk 'BEGIN {print ARGV[0]}' /etc/fstab /etc/inittab
awk 'BEGIN {print ARGV[1]}' /etc/fstab /etc/inittab
awk 'BEGIN {print ARGV[2]}' /etc/fstab /etc/inittab
[root@Centos7 ~]#awk 'BEGIN {print ARGC}' /etc/fstab /etc/inittab
3
[root@Centos7 ~]#awk 'BEGIN {print ARGV[0]}' /etc/fstab /etcinttab
awk
[root@Centos7 ~]#awk 'BEGIN {print ARGV[1]}' /etc/fstab /etc/inttab
/etc/fstab
[root@Centos7 ~]#awk 'BEGIN {print ARGV[2]}' /etc/fstab /etc/inttab
/etc/inttab
二、自定义变量
- 自定义变量区分大小写,有两种定义方式
- -v 选项定义
- 在program中定义
- 实验:自定义变量的使用
awk -v test="hello,gawk" 'BEGIN {print test}',直接使用V选项定义awk 'BEGIN {test="hello,gawk" print test}',在program中定义
[root@Centos7 ~]#awk 'BEGIN {print ARGV[2]}' /etc/fstab /etc/inttab
/etc/inttab
[root@Centos7 ~]#awk -v test='hello,gawk' 'BEGIN{print test}'
hello,gawk
[root@Centos7 ~]#awk 'BEGIN{test="hello.gawk"; print test}'
hello.gawk
awk -F: '{sex="male; print $1,sex,age;age="18"}' /etc/passwd
首行没有第三个字符,因为要打印到第三个字段才会赋值age,之后的每一个行打印时都有赋值,显示如下
[root@Centos7 ~]#awk -F: '{sex="male";print $1,sex,age;age=18}' /etc/passwd
root male
bin male 18
daemon male 18
adm male 18
- 也可以将program部分写入文件中,使用awk的-f选项导入
echo '{print script $1,$2}' > awkscript
awk -F: -f awkscript -v script="awk" /etc/passwd
[root@Centos7 /data]#echo '{print script,$1,$2}' > awkscript
[root@Centos7 /data]#awk -F: -f awkscript -v script="awk" /etc/passwd
awk root x
awk bin x
awk daemon x
awk adm x
awk lp x
awk sync x
Printf 命令:实现格式化输出
-
语法:printf “FORMAT”,item1,item2,…
- 必须指定FORMAT
- 不会自动换行,需要显式给出换行控制符:\n
- FORMAT中需要分别为后面每个item指定格式符
-
格式符:与item对应
- %c:显示字符的ASCII码
- %d, %i:显示十进制整数
- %e, %E:显示科学计数法数值
- %f:显示为浮点数
- %g, %G:以科学计数法或浮点形式显示数值
- %s:显示字符串
- %u:无符号整数
- %%:显示%自身
-
修饰符
- #[.#]:第一个#控制显示的宽度,第二个#表示小数点后精度,%3.1f
- -:左对齐(默认右对齐)%-15s
- +:显示数值的正负符号%+d
-
实验示例:printf 的使用
- 显示/etc/passwd文件以冒号为分隔符的第1,3列,并且第1列宽20左对齐,第3列宽10右对齐
awk '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
- 显示/etc/passwd文件以冒号为分隔符的第1,3列,并且第1列宽20左对齐,第3列宽10右对齐
[root@Centos7 /data]#awk -F: '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
- 显示/etc/passwd文件以冒号为分隔符的第1,3列,格式:“Username: 第1列内容 , ID: 第3列内容”,其中第1列内容宽15左对齐
awk -F: '{printf "Username: %-15s" "ID: %d\n",$1,$3}' /etc/passwd
[root@Centos7 /data]#awk -F: '{printf "Username: %-15s" "ID: %d\n",$1,$3}' /etc/passwd
Username: root ID: 0
Username: bin ID: 1
Username: daemon ID: 2
Username: adm ID: 3
AWK 操作符
-
算术操作符:
x+y, x-y, x*y, x/y, x^y, x%y
-x: 转换为负数
+x: 转换为数值 -
赋值操作符:
=, +=, -=, *=, /=, %=, ^=
++, – -
比较操作符:
==, !=,>, >=, <, <= -
模式匹配符:
~:左边是否匹配右边
!~:左边是否不匹配右边 -
示例
#打印/etc/passwd文件包含"root"内容行的第一个字段(以":"分隔)
[root@Centos7 ~]#awk -F: '$0 ~ /root/{print $1}' /etc/passw
root
operator
#打印/etc/passwd文件行首为"root"的行
[root@Centos7 ~]#awk '$0 ~ "^root"' /etc/passwd
root:x:0:0:root:/root:/bin/bash
#打印/etc/passwd文件不包含"root"内容的所有行
[root@Centos7 ~]#awk '$0 !~ /root/' /etc/passwd
#二者是一个意思
[root@Centos7 ~]#awk '$0 !~ "root"' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
#打印/etc/passwd文件以":"分隔的第三个字符等于0的所有行
[root@Centos7 ~]#awk -F: '$0==3' /etc/passwd
root:x:0:0:root:/root:/bin/bash
- 逻辑操作符:与&&,或||,非!
- 示例如下:
#打印root用户和系统用户名称(CentOS 7)
[root@Centos7 ~]#awk -F: '$3>=0 && $3<1000 {print $1}' /etc/passwd
root
bin
daemon
adm
#打印root用户和普通用户的名称(CentOS 7)
[root@Centos7 ~]#awk -F: '$3==0 || $3>=1000 {print $1}' /etc/passwd
root
nfsnobody
yijie
#打印除root用户外的所有用户名称
[root@Centos7 ~]#awk -F: '!($3==0) {print $1}' /etc/passw
bin
daemon
adm
#打印root用户和系统用户的UID(CentOS 6)
[root@Centos7 ~]#awk -F: '!($3>=1000) {print $3}' /etc/passwd
0
1
2
- 函数调用:function_name(argu1, argu2, …)
- 条件表达式(三目表达式):
语法:selector?if-true-expression:if-false-expression
示例:
打印用户名称,若是普通用户则其后输出"Common User",否则输出"Sysadmin or SysUser",中间以":"分割。用户名称宽15右对齐,其后的类型信息左对齐(CentOS 7)
[root@Centos7 ~]#awk -F: '{$3>=1000?usertype="Common User":usertype="Sysadmin or Sysuser";printf "%15s: %-s\n",$1,usertype}' /etc/passwd
root: Sysadmin or SysUser
bin: Sysadmin or SysUser
daemon: Sysadmin or SysUser
adm: Sysadmin or SysUser
lp: Sysadmin or SysUser
AWK Pattern
- PATTERN:根据pattern条件,过滤匹配的行,再做处理, 如果未指定:空模式,匹配每一行
- 一、正则表达式:/regular expression/
仅处理模式匹配到的行,需要用"/ /"括起来 - 二、关系表达式:结果为“真”才会被处理
- 真:结果为非0值,非空字符串
- 假:结果为空字符串或0值
- 三、line ranges,行范围
/pat1/,/pat2/:支持使用正则表达式描述,不支持直接给出数字格式 - (四)BEGIN/END模式
- BEGIN{}:仅在开始处理文件中的文本之前执行一次
- END{}:仅在文本处理完成之后执行一次
- 示例:pattern中正则表达式和关系表达式的用法
#打印/etc/fstab文件以UUID开头的行的第1列
[root@Centos7 ~]#awk '/^UUID/{print $1}' /etc/fstab
UUID=ca02ca33-a08a-498a-83d8-337b8cc99508
UUID=3b5ca6bb-0d70-4b40-970b-ec57424622bf
UUID=f5d9456c-83cd-4b48-81a6-2819b851d1d8
UUID=4b4a8a3d-f232-42ac-908c-bec4ef59d7b0
#打印/etc/fastab文件不以UUID开头的行的第1列
[root@Centos7 ~]#awk '!/^UUID/{print $1}' /etc/passwd
#
#
#
#program第1条语句关系判断为真(i=1),故打印本行;第2条语句关系判断为真(j=1),故打印i和j值
[root@Centos7 ~]#awk -F: 'i=1{print $0};j=1{print i,j}' /etc/passwd
[root@Centos7 ~]#awk -F: 'i=1;j=1{print i,j}' /etc/passwd
#前面两行命令是一个意思,第二行是第一行的简化
root:x:0:0:root:/root:/bin/bash
1 1
bin:x:1:1:bin:/bin:/sbin/nologin
1 1
daemon:x:2:2:daemon:/sbin:/sbin/nologin
1 1
#非0即为真,全部打印,后面为空。默认是{print $0}
[root@Centos7 ~]#awk '!0' /etc/passwd
#非1即为假,一行也不打印
[root@Centos7 ~]#awk '!1' /etc/passwd
#打印/etc/passwd文件以":"为分隔符的第3列数值大于等于1000的行的第1和第3列
[root@Centos7 ~]#awk -F: '$3>=1000 {print $1,$3}' /etc/passwd
nfsnobody 65534
yijie 1000
#打印/etc/passwd文件以":"为分隔符的第3列数值小于1000的行的第1和第3列
[root@Centos7 ~]#awk -F: '$3<1000 {print $1,$3}' /etc/passwd
root 0
bin 1
daemon 2
adm 3
#打印/etc/passwd文件以":"为分隔符的最后一列是"/bin/bash"的行的第1列和最后1列
[root@Centos7 ~]#awk -F: '$NF=="/bin/bash" {print $1,$NF}' /etc/passwd
root /bin/bash
yijie /bin/bash
#打印/etc/passwd文件以":"为分隔符的最后一列是以"bash"作为行尾的行的第1列和最后1列
[root@Centos7 ~]#awk -F: '$NF ~ /bash$/ {print $1,$NF}' /etc/passwd
root /bin/bash
yijie /bin/bash
#读入第1行时,i值取反为1所以打印本行,读入第2行时,i值为1取反后为0所以不打印本行
#读入第3行与读入第1行相似,读入第4行与读入第2行相似,以此类推,所以结果为打印奇数行
[root@Centos7 ~]#seq 10 | awk 'i=!i'
1
3
5
7
9
#与上述描述一样,打印偶数行
[root@Centos7 ~]#seq 10 | awk '!(i=!i)'
2
4
6
8
10
[root@Centos7 ~]#seq 10 |awk -v i=1 'i=!i'
2
4
6
8
10
- 示例:pattern中行范围和BEGIN/END模式的用法
#打印/etc/passwd文件从行首是"root"单词的行至行首是"nobody"单词的行中以":"作为分隔符的第1列
[root@Centos7 ~]#awk -F: '/^root\>/,/^nobody\>/ {print $1}' /etc/passwd
root
bin
daemon
adm
lp
sync
#BEGIN和END模式适用于打印表头和表尾
[root@Centos7 ~]#awk -F: 'BEGIN{printf "%-8s%s\n---------\n","USER","UID"}/^root\>/,/^sync\>/ {printf "%-8s%d\n",$1,$3}END{printf "========\n"}' /etc/passwd
USER UID
---------
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
=========
AWK Action
-
常用的action分类
(1) Expressions:算术,比较表达式等
(2) Control statements:if, while等
(3) Compound statements:组合语句
(4) input statements
(5) output statements:print等 -
一、awk控制语句:if-else
-
功能:对awk取得的整行或某个字段做条件判断
-
语法:
if(condition) {statement;…} [else statement]
if(condition1) {statement1} else if(condition2){statement2} else {statement3} -
示例如下
#打印普通用户名称和UID(CentOS 7)
[root@Centos7 ~]#awk -F: '{if($3>=1000) print $1,$3}' /etc/passwd
nfsnobody 65534
yijie 1000
#打印/etc/passwd文件以":"为分隔符的最后一列是"/bin/bash"的行的第1列
[root@Centos7 ~]#awk -F: '{if($NF=="/bin/bash") print $1}' /etc/passwd
root
yijie
#打印/etc/fstab文件以空格为分隔符字段数大于5的行
[root@Centos7 ~]#awk '{if(NF>5) print $0}' /etc/fstab
# Created by anaconda on Fri Oct 11 19:26:48 2019
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 / xfs defaults 0 0
UUID=3b5ca6bb-0d70-4b40-970b-ec57424622bf /boot xfs defaults 0 0
UUID=f5d9456c-83cd-4b48-81a6-2819b851d1d8 /data xfs defaults 0 0
UUID=4b4a8a3d-f232-42ac-908c-bec4ef59d7b0 swap swap defaults 0 0
#普通用户输出"Common User",其他用户输出"Sysadmin or SysUser",中间以":"分割,
#然后打印用户名称(CentOS 7)
[root@Centos7 ~]#awk -F: '{if($3>=1000) {printf "Common User: %s\n",$1}else {printf "Sysadmin or SysUser: %s\n",$1}}' /etc/passwd
Sysadmin or SysUser: root
Sysadmin or SysUser: bin
Sysadmin or SysUser: daemon
Sysadmin or SysUser: adm
#检查磁盘分区占用率,发现占用率大于等于的分区将分区名称和占用率打印出来
[root@Centos7 ~]#df | awk -F% '/\dev\/sda/ {print $1}' | awk '$NF>8 {print $1,$NF}'
[root@Centos7 ~]#df | awk -F " +|%" '/\/dev\/sda/ {print $1,$5}' | awk '{if($NF>8) {print $1,$NF}}'
#二者是表述一个意思
/dev/sda2 9
/dev/sda1 17
#普通用户输出"Common User",系统用户输出SysUser",root用户输出"Sysadmin",中间以":"分割,
#然后打印用户名称(CentOS 7)
[root@Centos7 ~]#awk -F: '{if ($3>=1000) {printf "Common User: %s\n",$1} else if ($3==0) {printf "Sysadmin: %s\n",$1} else {printf "Sysuer: %s\n",$1}}' /etc/passwd
Sysadmin: root
SysUser: bin
SysUser: daemon
SysUser: adm
Common User: yijie
- 二、awk控制语句:while循环
- 功能:条件“真”,进入循环;条件“假”,退出循环
- 语法:
while(condition){statement;…} - 使用场景:
- 对一行内的多个字段逐一类似处理时使用
- 对数组中的各元素逐一处理时使用
- 示例如下
#找出/etc/grub2.cfg文件以不定数量(包含0个)空格作为行首后接字符串"linux16"的行,
#以空格为分隔符打印这些行每个字段内容和字段长度
[root@Centos7 ~]#awk '/^[[:space:]]*linux16/{i=1;while (i<=NF) {print $i,length($i);i++}}' /etc/grub2.cfg
linux16 7
/vmlinuz-3.10.0-1062.el7.x86_64 31
root=UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 46
ro 2
crashkernel=auto 16
spectre_v2=retpoline 20
rhgb 4
quiet 5
net.ifnames=0 13
linux16 7
/vmlinuz-0-rescue-3f16d8e7aacb4403935cc3bb698eb2d8 50
root=UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 46
ro 2
crashkernel=auto 16
spectre_v2=retpoline 20
rhgb 4
quiet 5
net.ifnames=0 13
#找出/etc/grub2.cfg文件以不定数量(包含0个)空格作为行首后接字符串"linux16"的行,
#以空格为分隔符找出长度大于10的字段,把字段和字段长度打印出来
[root@Centos7 ~]#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>10) {print $i,length($i)};i++}}' /etc/grub2.cfg
/vmlinuz-3.10.0-1062.el7.x86_64 31
root=UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 46
crashkernel=auto 16
spectre_v2=retpoline 20
net.ifnames=0 13
/vmlinuz-0-rescue-3f16d8e7aacb4403935cc3bb698eb2d8 50
root=UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 46
crashkernel=auto 16
spectre_v2=retpoline 20
net.ifnames=0 13
三、awk控制语句:do-while循环
- 功能:无论真假,至少执行一次循环体
- 语法:
do {statement;…}while(condition)
#从1到100求和
[root@Centos7 ~]#awk 'BEGIN{ sum=0;i=0;do{sum+=i;i++} while (i<100); print sum}'
4950
四、awk控制语句:for循环
- 语法:
for(expr1;expr2;expr3) {statement;…} - 常见用法:
for(variable assignment;condition;iterationprocess) {for-body} - 特殊用法:能够遍历数组中的元素
语法:for(var in array) {for-body} - 示例如下
#找出/etc/grub2.cfg文件以不定数量(包含0个)空格作为行首后接字符串"linux16"的行,
#以空格为分隔符打印这些行每个字段内容和字段长度
[root@Centos7 ~]#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg
linux16 7
/vmlinuz-3.10.0-1062.el7.x86_64 31
root=UUID=ca02ca33-a08a-498a-83d8-337b8cc99508 46
ro 2
crashkernel=auto 16
spectre_v2=retpoline 20
rhgb 4
quiet 5
net.ifnames=0 13
- 实验:awk, shell脚本和bc的性能比较
#awk来计算1到1000000的总和
[root@Centos7 ~]#time awk 'BEGIN{sum=0;for(i=1;i<=1000000;i++) {sum+=i} print sum}'
500000500000
real 0m0.073s
user 0m0.072s
sys 0m0.001s
[root@Centos7 ~]#time (sum=0;for i in {1..1000000};do let sum+=i;done;echo $sum)
500000500000
real 0m8.228s
user 0m4.754s
sys 0m3.446s
[root@Centos7 ~]#time (sum=0;for ((i=1;i<=1000000;i++));do let sum+=i;done; echo $sum)
500000500000
real 0m6.184s
user 0m5.716s
sys 0m0.440s
[root@Centos7 ~]#
[root@Centos7 ~]#time seq -s "+" 1000000 |bc
500000500000
real 0m0.530s
user 0m0.312s
sys 0m0.213s
可以看出awk执行效率最高,bc次之,shell脚本的效率最差
五、awk控制语句:switch, break, continue, next语句
- switch语句
语法:switch(expression) {case VALUE1 or /REGEXP/: statement1; case VALUE2 or /REGEXP2/: statement2; ...; default: statementn} - break和continue
awk 'BEGIN{sum=0;for(i=1;i<=100;i++) {if(i%2==0)continue;sum+=i}print sum}'
从1至100的奇数求和
awk 'BEGIN{sum=0;for(i=1;i<=100;i++) {if(i==66)break;sum+=i}print sum}'
从1至66求和 - next
提前结束对本行处理而直接进入下一行处理(awk自身循环)
awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd
输出UID为偶数的用户名称和UID
AWK 数组
一、awk数组的基本用法
- awk数组均为关联数组:array[index-expression]
- index-expression格式:
(1) 可使用任意字符串;字符串要使用双引号括起来
(2) 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串” - 若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
- 示例如下:
[root@Centos7 ~]# cat /etc/passwd >> passwd;cat /etc/passwd >> passwd;cat /etc/passwd >> passwd
#输出文件中的每一行,并且输出这是第几次重复本行信息
[root@Centos7 ~]#awk '{arr[$0]++;print $0,arr[$0]}' passwd
yijie:x:1000:1000:yijie:/home/yijie:/bin/bash 1
root:x:0:0:root:/root:/bin/bash 2
bin:x:1:1:bin:/bin:/sbin/nologin 2
daemon:x:2:2:daemon:/sbin:/sbin/nologin 2
adm:x:3:4:adm:/var/adm:/sbin/nologin 2
#删除重复行
[root@Centos7 ~]#awk '!arr[$0]++' passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
#解释:当行信息第一次赋值给数组元素时,数组元素值为空,所以取反为真,输出此行;
#而当相同信息第二、三......次赋值时,数组元素值大于等于1,取反为假,不输出此行,
#从而实现不输出重复行。
awk数组的遍历
- 若要遍历数组中的每个元素,要使用for循环
for(var in array) {for-body}
var会遍历array的每个索引 - 示例:
#遍历输出weekday数组的值
[root@Centos7 ~]#awk 'BEGIN{weekdays["mon"]="Monday";weekdays["true"]="Tuesday";for (inx in weekdays) {print weekdays[inx]}}'
Tuesday
Monday
- 实验
- 统计处于不同网络状态的tcp连接数
- 分析:首先用
netstat -tan命令显示tcp连接情况。统计连接数需要考虑问题: - 第一,如何过滤有效行,可以在awk中的pattern中设置;
- 第二,怎样存储状态名称和累加计数,可以利用awk的关联数组功能,将状态名称作为数组下标,并且数组自加1作为计数器;
- 第三,如何输出每个状态和状态的数量,可以利用for循环的遍历数组功能实现
netstat -tan |awk '/^tcp\>/{ip[$NF]++}END{for(i in ip){print i,ip[i]}}'
- 分析:首先用
- 统计所有的IP连接数,超过一定条件,加入防火墙规则拒绝
#查看tcp下面连接的IP地址
ss -nt
#把IP地址取出来
ss -nt |awk -F ' +|:' '/ESTAB/{print $6}'
#统计每个IP连接的次数
ss -nt |awk -F ' +|:' '/ESTAB/{ip[$6]++}END{for (i in ip){print i":"ip[i]}}'
#统计出连接次数大于3的IP地址
ss -nt |awk -F ' +|:' '/ESTAB/{ip[$6]++}END{for(i in ip){if(ip[i]>=3) print i}}'
#把符合规则取出来的IP放入防火墙规则
ss -nt |awk -F ' +|:' '/ESTAB/{ip[$6]++}END{for(i in ip){if(ip[i]>=3) print i}}' | while read ip;do iptables -A INPUT -s $ip REJECT ;done
- 统计access_log文件每个ip地址的记录行数,并且输出行数最多的5个ip地址
- 分析:查看文件格式,发现ip地址位于行首,并且以空格为分隔符正是第1个字段
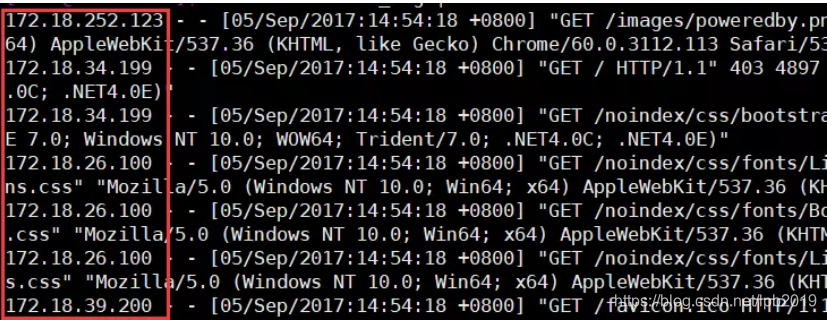
仿照实验(1)的思路,将$1作为数组下标实现统计不同ip的记录数,最后for循环遍历输出每个ip地址和记录行数。之后用sort排序工具按数字倒叙排序,用head工具输出前五行数据 - 代码实现如下:
awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' access_log |sort -nr -k2|head -5

- 分析:查看文件格式,发现ip地址位于行首,并且以空格为分隔符正是第1个字段
AWK 函数
一、数值处理:
- rand():返回0和1之间一个随机数
[root@Centos7 ~]# awk 'BEGIN{rand();for(i=1;i<=10;i++) print int(rand()*100)}'
29
84
15
58
19
81
17
48
15
36
#输出10个100以内的随机数,注意使用rand函数前先使用srand函数建立种子
二、字符串处理:
- length([s]):返回指定字符串的长度
- sub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并将第一个匹配的内容替换为s
[root@Centos7 ~]# echo "2008:08:08 08:08:08" |awk 'sub(/:/,"-",$1)'
2008-08:08 08:08:08
#将以空格为分隔符的第1个字段搜索到的第1个":"替换为"-"
- gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表示的内容
[root@Centos7 ~]# echo "2008:08:08 08:08:08" | awk 'gsub(/:/,"-",$1)'
2008-08-08 08:08:08
#将以空格为分隔符的第1个字段搜索到的每个":"替换为"-"
- split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,…
[root@Centos7 ~]# netstat -tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for (idx in count){print idx,count[idx]}}'
172.20.3.69 1
0.0.0.0 2
#将netstat -tan输出结果中的Foreign Address列ip地址(不含端口号)和其出现次数统计出来,只能使一次awk命令
- 分析:awk实现了以空格为分隔符取Foreign Address列字段$5的功能,再使用split函数再次将字段以":"为分隔符分割。split函数分割的结果存储在数组ip中,而需要之后遍历的信息在数组ip的第一个元素ip[1]中,故将ip[1]再赋值给新的数组count,此后就可以遍历新数组count统计出现次数
三、自定义函数:
- 格式:
function name ( parameter, parameter, … ) {
statements
return expression
} - 示例如下:
#编写一个函数,实现输出两个变量的较大值将函数的实现写在max.awx文件中,执行时导入文件
#文件中代码如下:
function max(var1,var2) {
var1>var2?maxnum=var1:maxnum=var2
return maxnum
}
BEGIN {printf " max num is %d\n",max(a,b)}
执行命令,awx -f max.awx -v a=5 -v b=3,结果如下

四、awk调用shell命令:system()
- 注意:空格是awk中的字符串连接符,如果system中需要使用awk中的变量可以使用空格分隔,或者说除了awk的变量外其他一律用""引用起来。
[root@Centos7 ~]# awk 'BEGIN{system("hostname") }'
Centos7.server0
#相当于在shell中执行hostname命令
[root@Centos7 ~]# awk 'BEGIN{score=100; system("echo your score is " score) }'
your score is 100
#调用shell命令echo your scre is,然后输出awk的变量score的值
AWK 脚本
- 可以将awk程序写成脚本,直接调用或执行
- 注意:当执行awk脚本时,注意需要行首添加
#! /bin/awk -f - 示例编写脚本user.awk,实现分行输出普通用户的用户名和UID(CentOS 7)
代码如下:
- 注意:当执行awk脚本时,注意需要行首添加
#! /bin/awk -f
{if($3>=1000)print $1,$3}
运行脚本前给脚本添加执行权限,执行命令./user.awk -F: /etc/passwd

- 向脚本传递参数
- 格式:
awk_script_file var1=value1 var2=value2... Inputfile - 注意:在BEGIN过程中不可用。直到首行输入完成以后,变量才可用。可以通过-v 参数,让awk在执行BEGIN之前得到变量的值。命令行中每一个指定的变量都需要一个-v参数
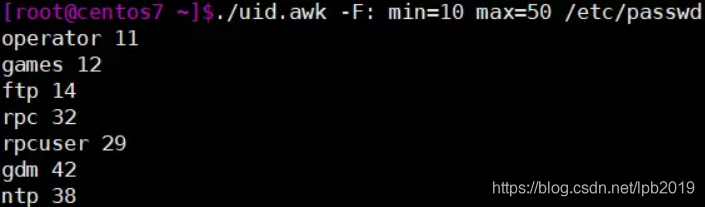
- 编写脚本uid.awk,输出指定范围UID号的用户名和其UID,代码如下:
#! /bin/awk -f
{if ($3>=min && $3<=max)print $1,$3}
chmod +x uid.awk
./uid.awk -F: min=10 max=50 /etc/passwd
结果如下图:
完


















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









