



目录
Write Once Run Anywhere How do
Application ClassLoader 系统类加载器
什么Java虚拟机
官网解释
The Java Virtual Machine (JVM) is an abstract computing machine. The JVM is aprogram that looks like a machine to the programs written to execute in it. Thisway, Java programs are written to the same set of interfaces and libraries. EachJVM implementation for a specific operating system, translates the Javaprogramming instructions into instructions and commands that run on thelocal operating system. This way, Java programs achieve platformindependence.
Java虚拟机(JVM)是一种抽象计算机器。JVM是一个程序,它看起来像是一台机器,用于编写并在其中执行的程序。通过这种方式,Java程序被写入同一组接口和库中。针对特定操作系统的每个JVM实现都将Java编程指令转换为在本地操作系统上运行的指令和命令。这样,Java程序就实现了平台独立性。
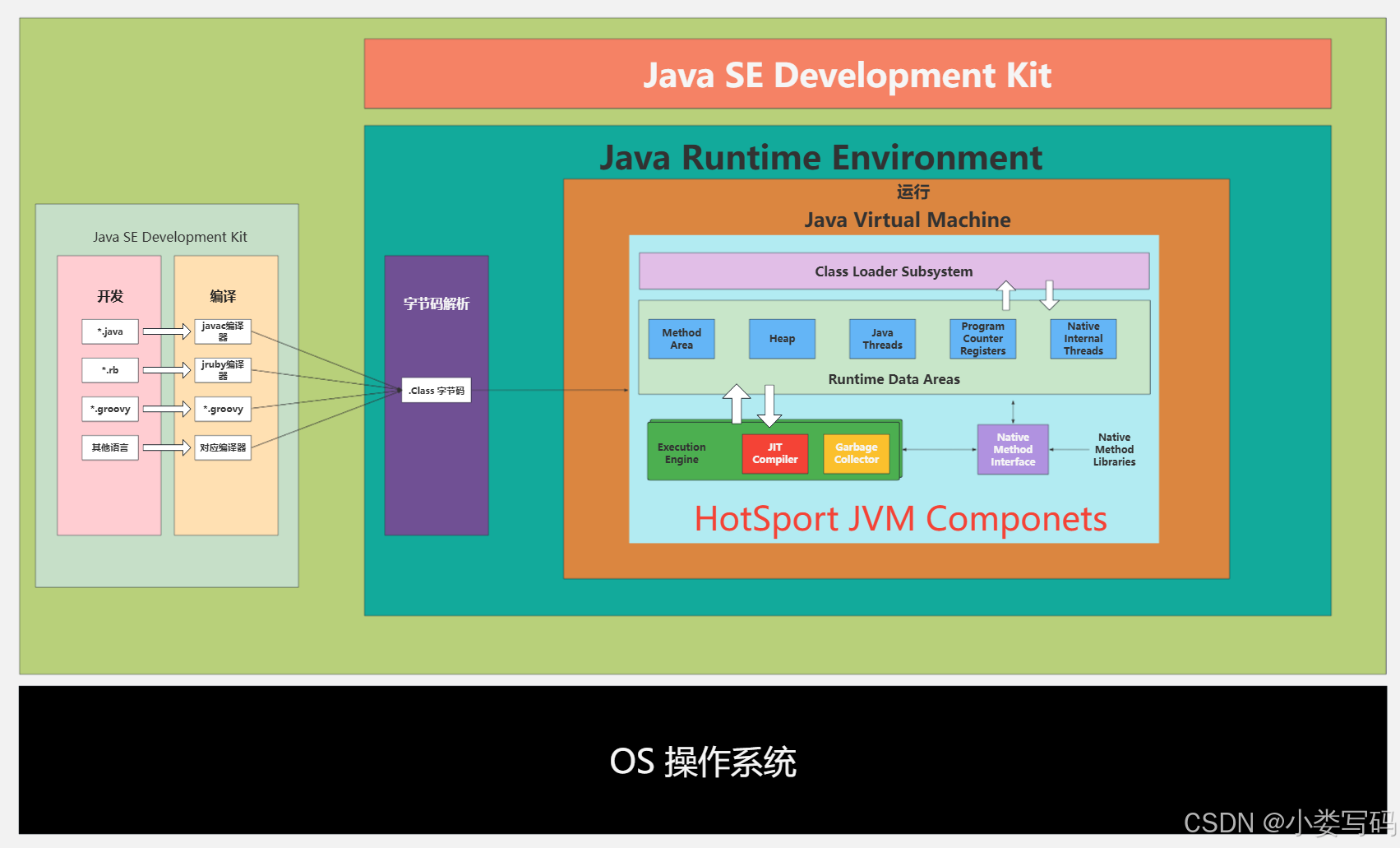
JDK JRE JVM 的区别和联系
JDK(Java SE Development Kit),Java标准开发包,它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器(javac)、java运行时环境,以及常用的Java类库等等。
JDK的安装目录:
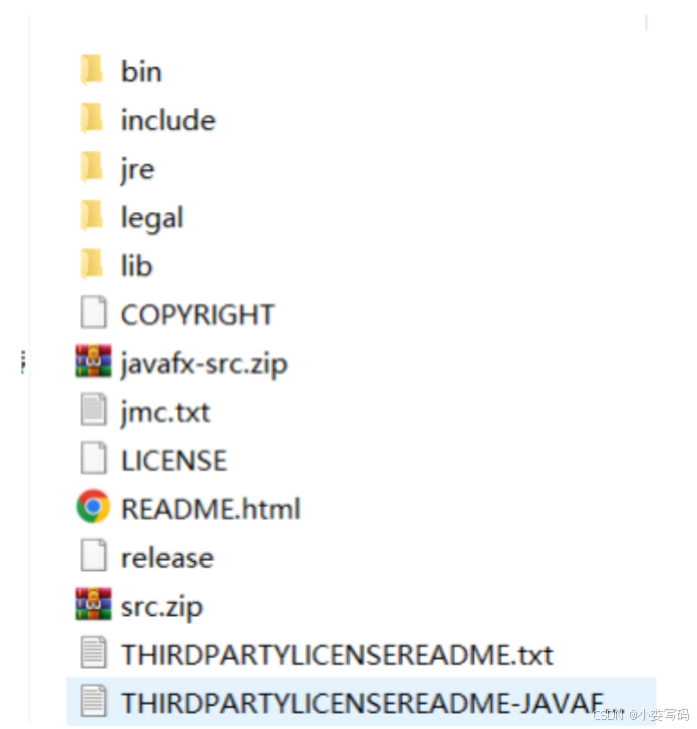
打开目录: D:\Java\jdk1.8.0_321
bin文件夹下:里面我们最常用的就是javac.exe 、web services、javadoc、等等
jre文件夹下:java运行环境
lib文件夹下:java 的基础类库,比如dt.jar(有关于swing文件)、tools.jar
include文件夹下:java和JVM交互用的头文件(c++.h文件)
Java Runtime Environment(JRE)
JRE(Java Runtime Environment)Java运行环境,用于解析执行Java的字节码文件。普通用户而只需要安装JRE来运行Java程序。而程序开发者必须需要安装JDK来编译、调试程序。
下图是JRE的安装目录:里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需的类库,而jvm和lib合起来就称为jre。
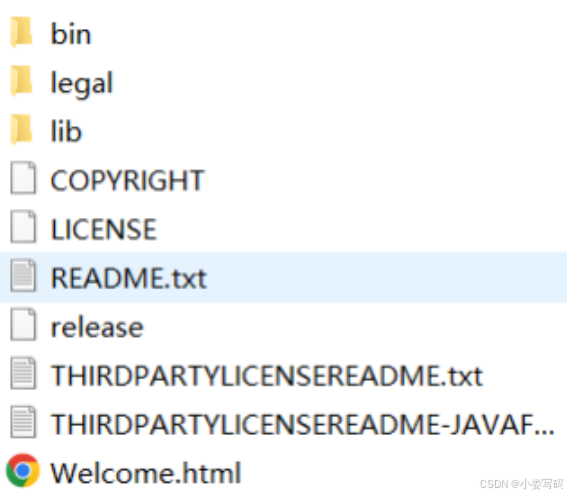
打开目录:D:\Java\jre1.8.0_321
lib文件夹下:jvm工作所需的类库
bin文件夹下:jvm (这里可以理解为java虚拟机)
Java Virtual Machine (JVM)
JVM(Java Virtual Machine),Java 虚拟机,是JRE内的一部分。它是整个Java 实现跨平台的最核心的部分,负责解析执行字节码文件的虚拟机计算机。所有平台的JVM向编译器提供相同的接口,而我们编译器只需要面向虚拟机,生成虚拟机能识别的代码(字节码),然后由虚拟机来解释执行。
JDK JRE JVM的区别与联系
客户:我只需要运行Java应用,我就需要JRE。
开发者:我需要JDK里面的工具帮我编译源代码,而且需要JRE核心类库做支持,并且运行在JVM中测试应用程序。
Write Once Run Anywhere How do
通常由javac 去编译程序源代码,转换成Java字节码,JVM通过解析字节码文件,将其翻译成对应的机器指令,逐条读入,逐条解析。
对于大部分程序只需要关注前端编译,是将我们的javac 编译器把java文件编译成字节码,然后加载到JVM的这个流程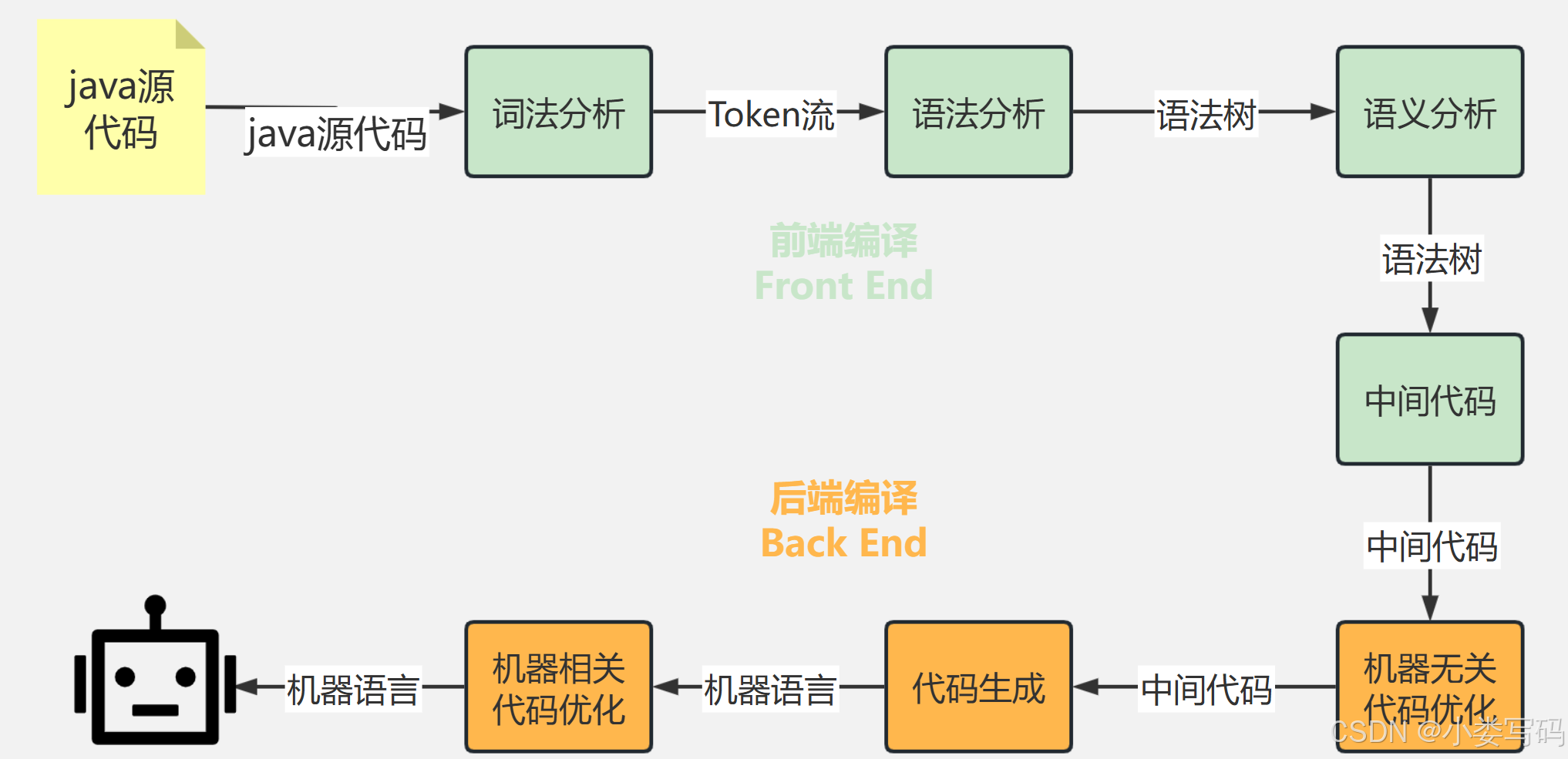
javac 编译Java文件为Class File
通过javac(编译器)把java文件变成.class字节码文件。
javac HelloWorld.java
javap -verbose HelloWorld.class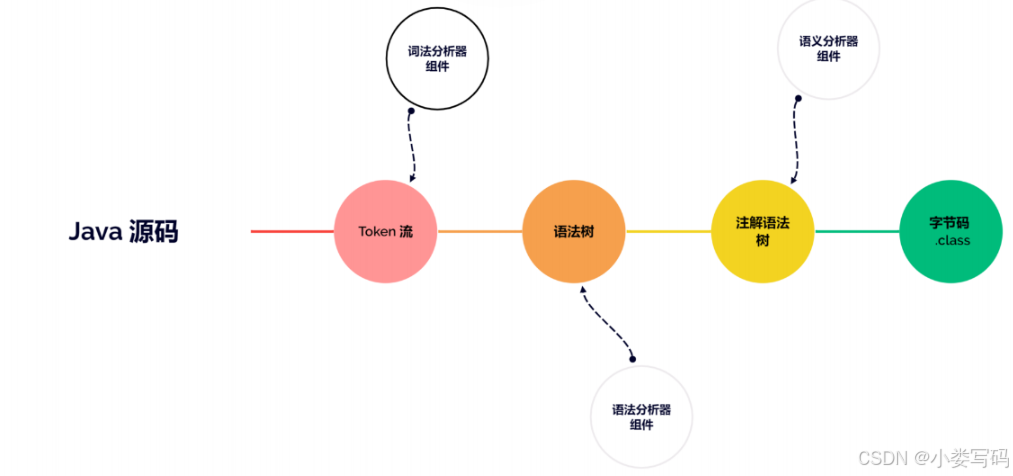
javac 源码中的
JavaCompiler.java
public void compile(List<JavaFileObject> sourceFileObjects,
List<String> classnames,Iterable<? extends Processor> processors)
{
......
try {
// 准备过程:初始化插入式注解处理器
initProcessAnnotations(processors);
// These method calls must be chained to avoid memory
leaks
delegateCompiler = // 过程 2:执行注解处理器
processAnnotations(
// 过程 1.2:输出到符号表enterTrees(
stopIfError(CompileState.PARSE,
parseFiles(sourceFileObjects))),classnames);
// 过程 3:分析及字节码生成
delegateCompiler.compile2();delegateCompiler.close();elapsed_msec = delegateCompiler.elapsed_msec;
} catch (Abort ex) {
if (devVerbose)
ex.printStackTrace(System.err);
} finally {
if (procEnvImpl != null)
procEnvImpl.close();
}
}词法分析器
读取源代码,一个字节一个字节读取出来,找到这些词法中的语句比如:访问修饰符、类和类名、条件语句、循环结构、基础的语法等等。
将源代码的字符流转变为标记(Token)集合的过程,单个字符是程序编写时的最小元素,但标记才是编译时的最小元素。关键字、变量名、字面量、运算符都可以作为标记,如下代码:
int a = b + 2;
这句代码中就包含了7个标记,分别是int、a、=、b、+、2、;、虽然关键字int由3个字符构成,但是它只是一个独立的标记,不可以再拆分。在Javac的源码中,词法分析过程由 com.sun.tools.javac.parser.Scanner类来实现。
真正完成解析的是 JavaTokenizer.java的readToken();方法
语法分析器
根据Token集合生成抽象语法树,抽象语法树(Abstract Syntax Tree,AST)是一 种用来描述程序代码语法结构的树形表示方式,抽象语法树的每一个节点都代表着程序代码中的一个 语法结构(SyntaxConstruct),例如包、类型、修饰符、运算符、接口、返回值甚至连代码注释等都 可以是一种特定的语法结构。
上述这段代码生成的抽象语法树如下( IDEA JDT AstView 插件可以查看抽象语法树):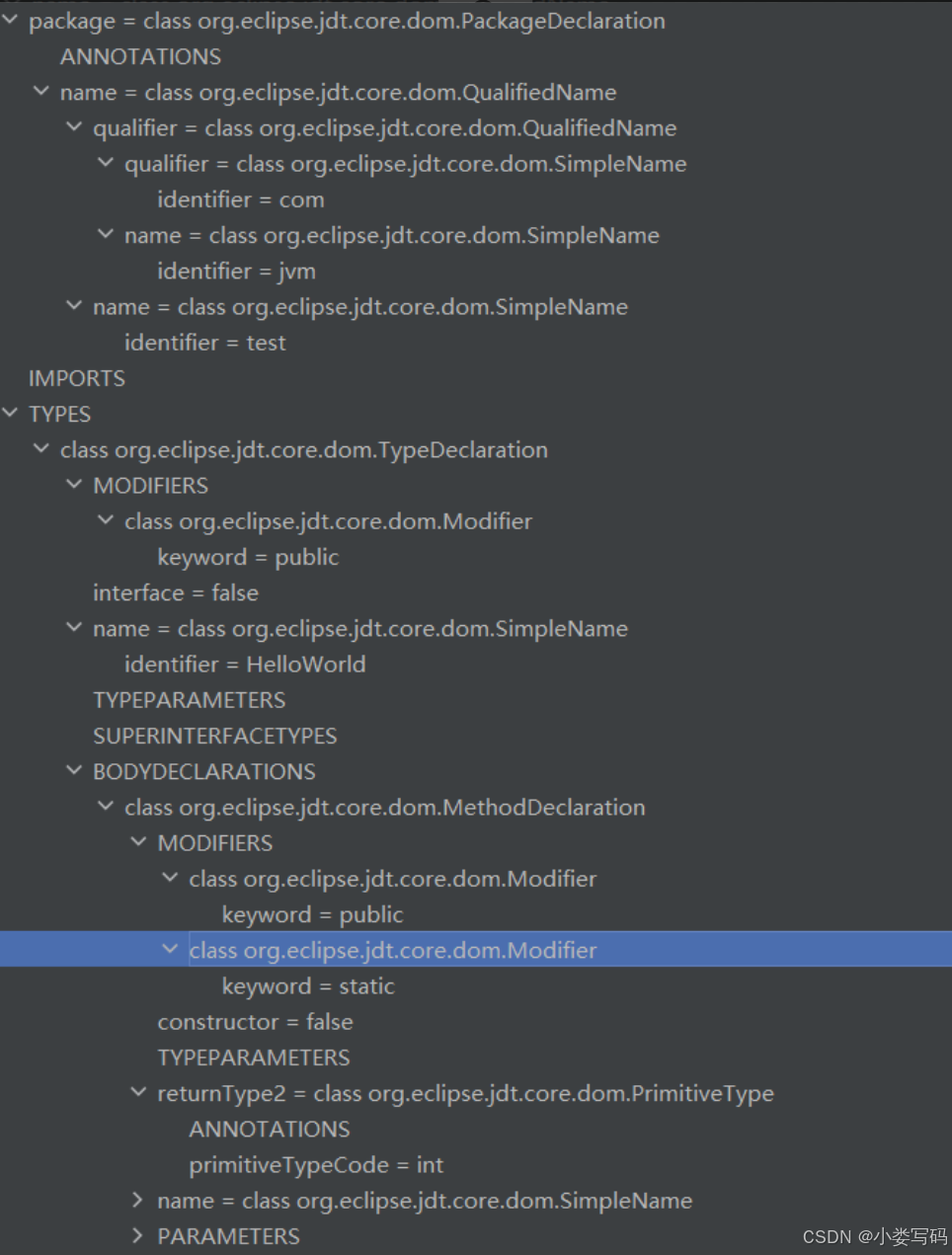
上述抽象语法树在Java中使用com.sun.tools.javac.tree.JCTree类来表示。
经过词法和语法分析生成语法树以后,编译器就不会再对源码字符流进行操作了,后续的操作都建立在抽象语法树之上。
结论:检查Token集合是否符合Java语言规范,有没有语法的错误,一切通过校验后得到一颗抽象的语法树。
例如:if 后面是否跟着boolean表达式 ,Java 关键字是否正确等等。
语义分析
经过语法分析之后,编译器获得了程序代码的抽象语法树表示,抽象语法树能
够表示一个结构正确的源程序,但无法保证源程序的语义是符合逻辑的;
结论:而语义分析的主要任务则是对结构上正确的源程序进行上下文相关性质的检查,将比较复杂的语法语义转化成简单的语法,譬如进行变量类型检查、控制流检查、数据流检查。
对我们刚刚生成那颗抽象语法解析树进行变量类型检查、控制流检查、数据流检查,解语法糖。
解语法糖
通常来说使用语法糖能够减少代码量、增加程序的可读性,从而减少程序代码出错的机会。“低糖”的语法让Java程序实现相同功能的代码量往往高于其他语言,通俗地说 就是会显得比较“啰嗦”,所以才会出现 Kotlin。
解语法糖的过程由desugar()方法触发,在
com.sun.tools.javac.comp.TransTypes类 和com.sun.tools.javac.comp.Lower类中完成。
字节码生成
字节码生成是Javac编译过程的最后一个阶段,在Javac源码里面由
com.sun.tools.javac.jvm.Gen类来 完成。字节码生成阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码指令写到磁盘中,编译器还进行了少量的代码添加和转换工作。
比如:
将static语句块、static变量收敛到方法中
将实例变量初始化、调用父类构造器收敛到方法
程序优化,比如将字符串的+操作替换成StringBuilder的append完成了语法树的遍历和调整以后,就会填充了所有信息的符号表交给
com.sun.tools.javac.jvm.ClassWriter类,最后由该类的writeClass()方法输出字节码。
结论:代码生成器的结果就是生成符合Java虚拟机规范的字节码。
Class File 解析
ClassFile 结构
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#jvms-4.1
ClassFile {
u4 magic;// 魔数,class文件的标识。值是固定的,十六进制
为:0xCAFEBABE
u2 minor_version;// [ˈmaɪnə(r)]小版本 0
u2 major_version;// [ˈmeɪdʒə(r)] 大版本 34,52对应
java 8,也就是我们jdk8生成的class版本
u2 constant_pool_count;//38 常量池计算器
cp_info constant_pool[constant_pool_count-1];// 常量池
u2 access_flags;//访问标志位 标志了类或者接口的访问信息,比如是类还是接口还是注解、枚举,是否是abstract,如果是类,是否被声明为final 等等
u2 this_class;//类索引
u2 super_class;//父类索引
u2 interfaces_count;//接口计数器,这个也是大家讨论动态代理最多是65535个接口的时候讨论的
u2 interfaces[interfaces_count];
u2 fields_count;//字段个数
field_info fields[fields_count];//字段集合
u2 methods_count;//方法计数器
method_info methods[methods_count];//方法集合
U2 attributes_count;//附加属性计数器
attribute_info attributes[attributes_count];//附加属性集合}我们发现ClassFile有两种数据类型:
1. 无符号数
2. 表
无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个 字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,为了便于区分,所有表的命名都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上也可以视作是一张表。
magic[ˈmædʒɪk]
每个Class文件的头4个字节被称为魔数(Magic Number),它的唯一作用是确定这个文件是否为 一个能被虚拟机接受的Class文件。
魔数,区分文件类型的一种标志,一般都是文件的前几个字节来表示,比如0XCAFE BABE表示class文件,因为我们java的图标是杯cafe,因为为了蹭当时的热度,当时咖啡最盛产的地方就是爪哇岛,所以名字叫java,图标就是cafe,然后javabean就是咖啡豆。
constant_pool_count
常量池计数器
当前类里常量池里有多少个常量,会比实际多1
我们写代码时都是从0开始的,但是这里的常量池却是从1开始,因为它把第0项常量空出来了。这是为了在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”的含义,这种情况可用索引值0来表示。
constant_pool[constant_pool_count-1]
cp_info {
u1 tag; // tag是标志位,它用于区分常量类型
u1 info[]; // info 数组的内容根据tag的值而变化,每个tag后面必须跟着二
个或者多个字节}
name_index是常量池的索引值,它指向常量池中一个我们可以通过命令查看常量池信息
javap -verbose ClassB.class
Constant pool tags 指向下面这个表的里的标记
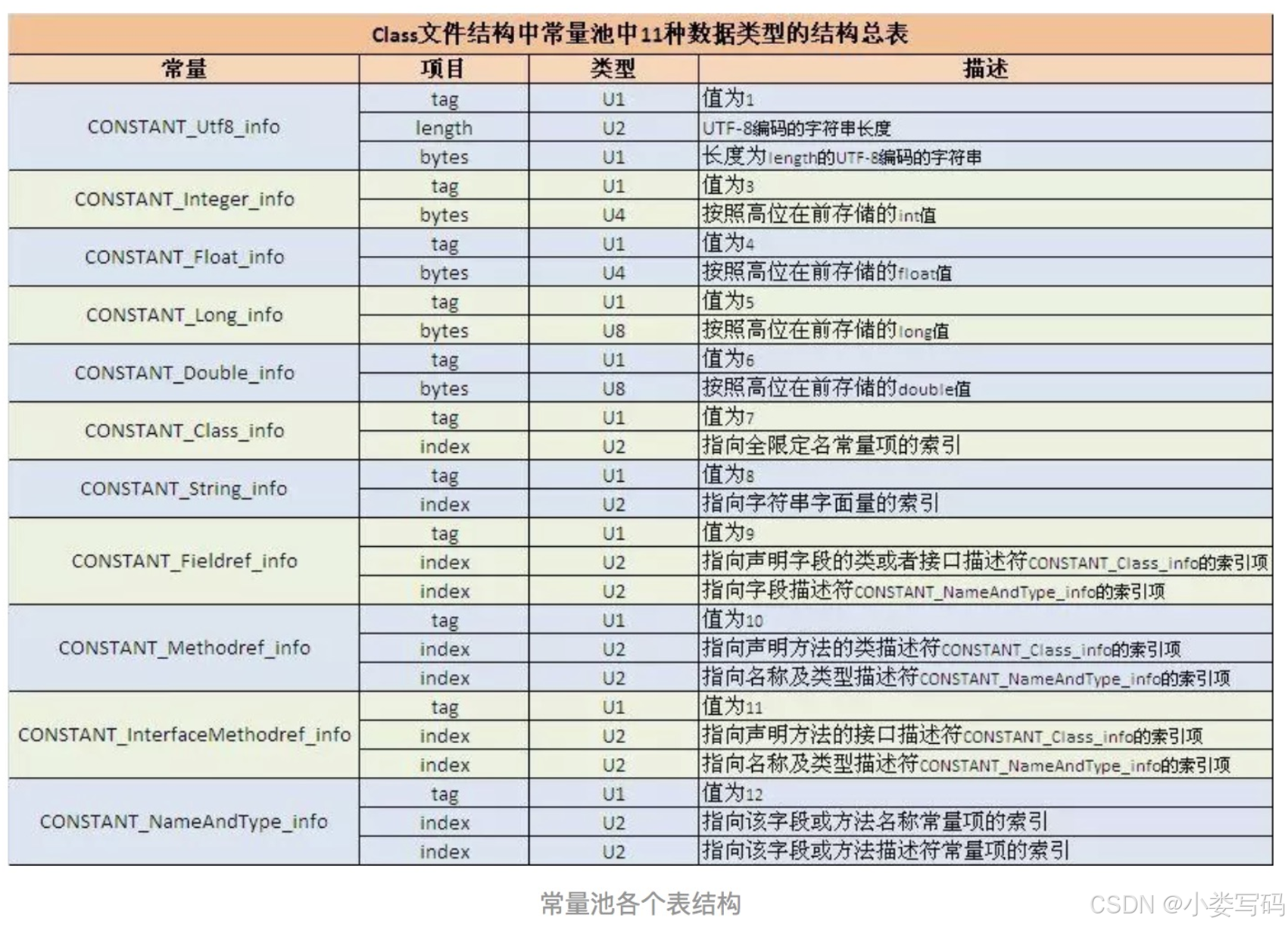
tag其实就是 标志代表这个表的类型
index 其实是指向常量的索引,会去调用这个常量
0a 00 13 00 2a
0a = CONSTANT_Methodref_info.tag
00 13 = CONSTANT_Methodref_info.index = 19 指向声明方法的类描述符
CONSTANT_Class_info.index(指向全限定名的常量项的索引)
00 2a = CONSTANT_Methodref_info.index = 42 指向名称及类型描述符
CONSTANT_NameAndType_info.index (指向该字段或方法名称常量项的索引)符号引用:类和接口的全限定名、字段的名称和描述符、方法的名称和描述符
Class 的生命周期和类加载器
我们编写的Java代码是如何运行在我们的操作系统之上呢,这个知识点大家都知道。java 文件通过javac编译成class文件,这种代码我们称之为字节码(中间码),由JVM去加载字节码这个过程。
这部分不需要去记,简单看看,前往别记
程序运行时,执行引擎中的解析器将字节码解析为二进制的机器码来执行,在程序运行的期间,执行引擎中的即时编译器会针对热点代码,将该部分的字节码编译成机器码以获得更高的执行效率。
整个程序运行时,解析器和即时编译器的相互配合,使得Java程序几乎能够达到编译型语言一样的执行速度。
像编译器就交给专业的人去做,大部分普通程序能够接触到的是JVM加载字节码这个过程。官方把这个过程成为类加载。
在进入Class File Loading之前,我们明确一下类加载流程的目的。
就是把javac 编译过的class字节码文件,通过加载,生成某种形式的class数据结构进入内存,程序可以调用这个数据结构来构造出object,这个过程是在运行时进行的,这个也是Java动态拓展性的基础。
类的整个生命周期如下图: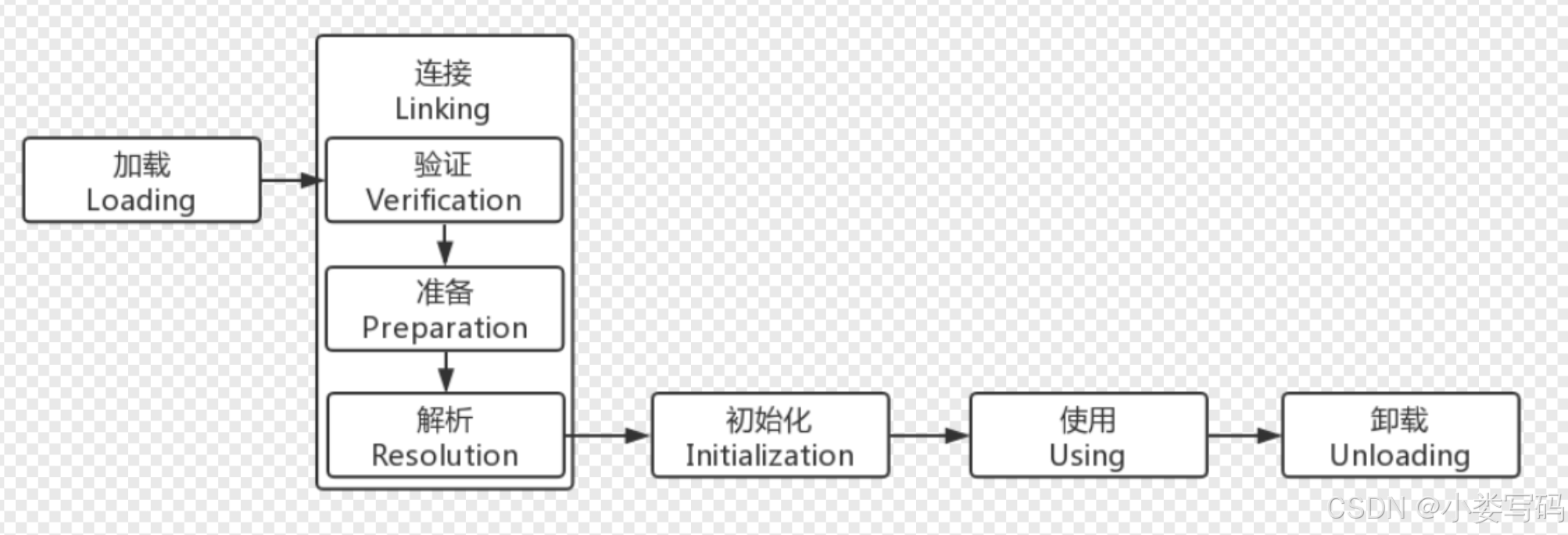
这个图片表现了一个类的生命周期,完整一点的话,我们可以在最开始加上javac编译阶段。而“类加载”只包括加载、连接、初始化三个过程。
需要区分“类加载”与“加载”,加载只是类加载的第一个环节。
解析部分是灵活的,它可以在初始化环节之后再进行,实现所谓的“后期绑定”,这点在讲到解析环节时候会详细讲。除解析过程外的其他加载过程必须按照如图顺序开始。
加载
加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段, 在加载阶段,Java虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。 (类的
文件信息交给JVM)
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
(类文件所对应的对象Class ---->JVM)
总结:加载是读取一个Class File二进制字符流,将其所代表的的静态存储结构转化
为方法区的运行时数据结构,并在内存(堆)中生成一个便于用户调用的java.lang.Class类型的对象的一个过程。
在互联网环境,我们最重要的是保证我们系统的安全性,虽然JVM内存中已经存在这个对象,但是这个时候对象需要经过一点小小的考验,如果通过考验,那么才能顺序加载。
加载阶段与连接阶段的部分动作(如一部分字节码文件格式验证动作)是交叉进行的,加载阶段尚未完成,连接阶段可能已经开始了,但是这些夹在加载阶段之中进行的动作,仍然属于连接阶段的一部分,这两个阶段的开始时间仍然保持着固定的先后顺序。
链接
验证
验证是连接阶段的第一步,这一阶段的目的是为了确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证文件格式、元数据、字节码等等
文件格式验证:此阶段保证输入的字节流能正确地解析并存储于方法区之内,格式上符合描述一个 Java类型信息的要求。
(1)是否以魔数 0xCAFEBABE开头
(2)主、次版本号是否在当前虚拟机处理范围之内 。
(3)常量池的常量中是否有不被支持的常量类型(检査常量tag 标志)。
(4)指向常量的各种索引值中是否有指向不存在的常量或不符合装型的常量 。
(5)CONSTANT_Utf8_info型的常量中是否有不符合 UTF8编码的数据(6)Class 文件中各个部分及文件本身是否有被删除的或附加的其他信息等等
元数据验证
保证不存在不符合 Java 语言规范的元数据信息。
(1)这个类是否有父类(除了 java.lang.0bject之外,所有的类都应当有父类)
(2)这个类的父类是否继承了不允许被继承的类(被finaI修饰的类)
(3)如果这个类不是抽象类, 是否实現了其父类或接口之中要求实现的所有方法
(4)类中的字段、 方法是否与父类产生了矛盾(例如覆盖了父类的final字段, 或者出
現不符合规则的方法重载, 例如方法参数都一致, 但返回类型却不同等)
不需要去记,为什么还需要校验元数据,有可能你在互联网里接受的类不是通过javac 编译出来的,是黑客自己写的,所以还需要校验一次。保证类是能符合面向对象,封装继承多态的思想的。
第二阶段的主要目的是对类的元数据信息进行语义校验,保证不存在与《Java语
言规范》定义相悖的元数据信息
符号引用的验证
在解析阶段中发生,保证可以将符号引用转化为直接引用。解析阶段我们之前也提到过,它可以在初始化阶段之前或者之后进行,所以验证其实包含了很多步骤,分散在不同的阶段内。这点是在图中画得不太准确的,网上很多博客也没有提到,我们可以在官网里找到对应的说明。此外验证的内容也是会不断发展的,除了这里提到的文件格式验证,元数据验证,字节码验证,符号引用验证四个环节,从低版本的虚拟机到现在,验证的步骤其实已经不断加入了各种机制,那在元数据字节码验证通过后呢。
准备
为我们类中定义的变量赋予零值(初始值)。
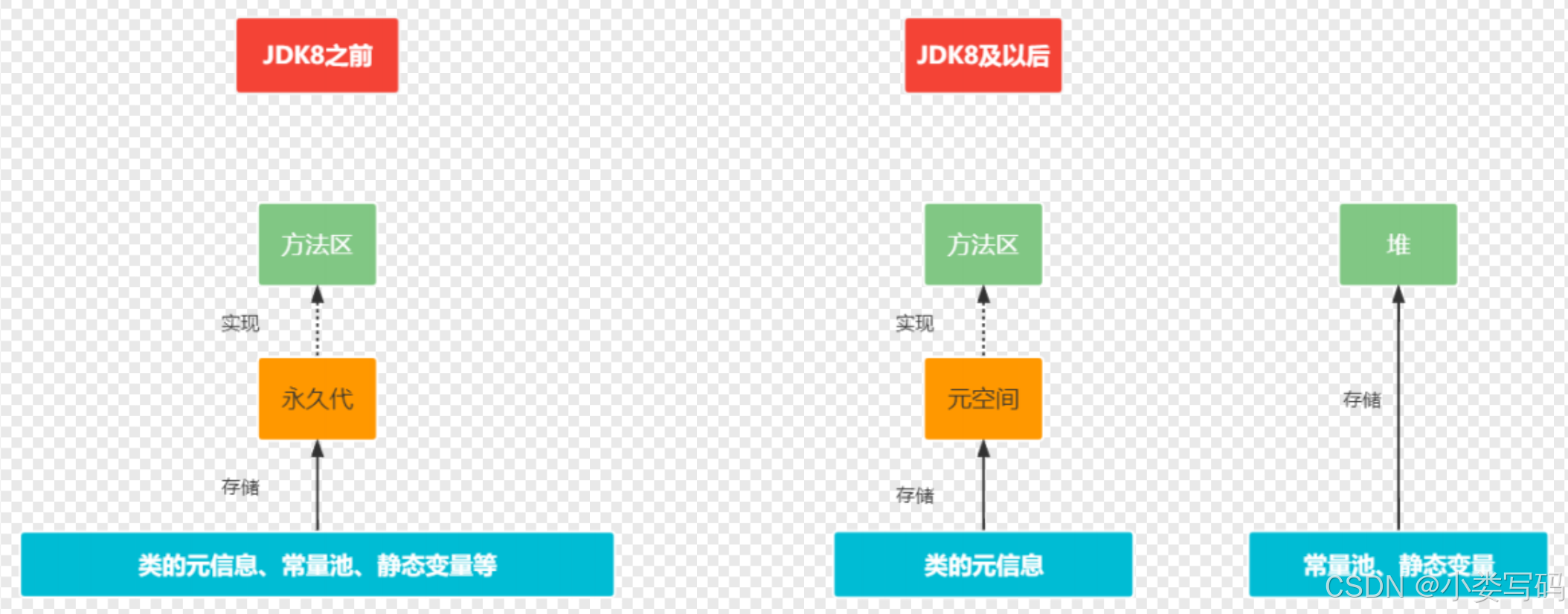
准备阶段是正式为类中定义的变量(即静态[ˈstætɪk]变量,被static修饰的变量)分配内存并设置类变量初始值的阶段,从概念上讲,这些变量所使用的内存都应当在方法区中进行分配,但必须注意到方法区本身是一个逻辑上的区域,在JDK 7及之前,HotSpot使用永久代来实现方法区时,实现是完全符合这 种逻辑概念的;而在JDK 8及之后,类变量则会随着Class对象一起存放在Java堆中,这时候“类变量在方法区”就完全是一种对逻辑概念的表述。
虚拟机内存规范中定义了方法区这种抽象概念,HotSpot虚拟机在JDK8之前使用了永久代这种具体的方法来实现方法区,JDK8及以后,弃用“永久代”这种实现方式,采用元空间这种直接内存来存储类的原信息等等,所以说,我们常常看到有人说JDK8及其以后采用“元空间”来替代”方法区“,这种说法是完全错误的,因为方法区是抽象概念,永久代和方法区是实现方式。
我们怎么去理解呢,JDK8之前,类的元信息、常量池、静态变量等都存放在永久代具体实现中,JDK8之后常量池、静态变量被移除“方法区” 转移了堆中,原信息依旧保存在方法区内,但是具体的存储方式改成了元空间。
理解难点:抽象概念与具体实现之间的区别。
解析
符号引用验证通过之后:将常量池中的符号引用转为直接引用
解析的动作主要是针对类或者接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行转换为直接引用,符号引用可以理解为上门讲那些常量的名字,直接引用就是内存中的真实地址,我们可以通过这个地址调用具体的方法等等。
当解析步骤完成之后,意味着整个连接部分已经完成,也就说加载外部Java文件已经成功引入到我们虚拟机当中。
当一个Java类被编译成Class之后呢,假如这个类成为A,并且A中引用了B,那么在编译阶段呢A是不知道B有没有被编译的,而且此时B一定也没有被加载,所以A肯定也不知道B中的实际地址,这个时候A怎么找到B呢,此时在A的class文件中,将使用一个字符串S来代表B的地址,S就被称为符号引用了。在运行时如果A 发生了类加载,到解析阶段会发现B还未被加载,那么将会触发B的类加载,将B加载到虚拟机中,此时A中的B的符号引用将会被替换成B的实际地址这被称为直接引用,这样A也就能真正的调用B了。
了解过多态的同学应该知道java通过后期绑定的方式来实现多态,那么后期绑定的这个概念是如何实现的呢?其实就是这里的动态解析,接着上面所说,如果A调用B是一个具体的实现类,那么就称为静态解析,因为解析的目标类很明确,而假如上层Java代码使用了多态,这里的A是一个抽象类或者是接口,他有两个具体的实现类C和D ,此时A的具体实现并不明确,当然也就不知道使用哪个具体类的直接引用来进行替换了,直到运行过程中发生了调用,此时虚拟机调用栈中将会得到具体的类型信息,这时候再进行解析,就能用明确的直接引用替代符号引用了。这是也是解析阶段有时候发生在初始化阶段之后,这就是动态解析,用它来实现了后期绑定和多态,底层对应了用的是invokevirtual或invokeinterface这条字节码指令, 如果没有听
懂,可以先理解一下多态,后期绑定这些概念。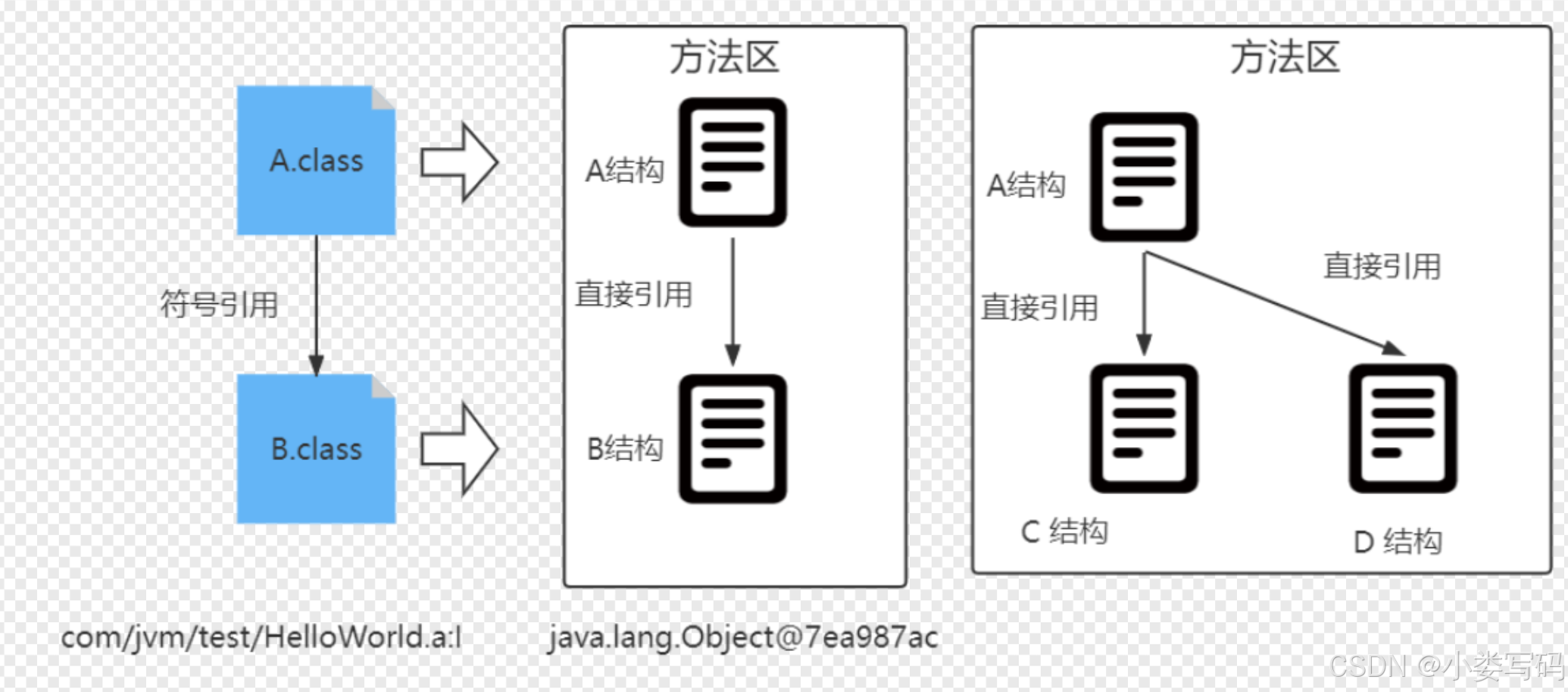
总结
解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 7 类符号引用进行。
符号引用可以理解成上面讲的那14种常量的名字等等。直接引用就是内存中的真实地址。
当解析步骤完成意味着整个连接部分的完成,这也就是说加载外部的java类已经成功的引入到我们的java虚拟机中了。
初始化
Initialize
为静态变量赋真正的值。
初始化阶段比较易于理解,就是会判断代码中的是否存在主动的资源初始化操作,如果有就执行。
这里所说的主动的资源初始化动作,不是指构造函数,而是class层面的,比如说成员变量的赋值动作,静态变量的赋值动作,以及静态代码块的逻辑,而只有显式的调用new指令,才会调用构造函数,进行对象的实例化,这是对象层面的,二者不要混淆。
只有你显式调用new 指令,才会调用构造函数,进行对象实例化,对象层面。
有5种类必须初始化的情况:
1.new、putstatic、getstatic、invokestatic字节吗指令的时候,如果类尚未初始化,则需要触发初始化。
2.对类进行反射调用的,如果类没有初始化,则需要初始化。
3.虚拟机启动时候,用于指定一个包含main()的主类,虚拟机会先初始化这个类。
4.动态语言支持时, java.lang.invoke.MethodHandle 实例最后结果为REF_getStatic。
使用
new Object()
卸载
Class 回收要满足以下三个条件:
1. No instance 该类所有的实例都已经被GC;
2. No ClassLoader 加载该类的ClassLoader实例已经被GC;
3. No Reference 该类的java.lang.Class对象没有被引用。(XXX.class, 静态变量/方
法)
class 的生命周期总结:
只有加载步骤中的读取二进制流与初始化部分,能被上层开发者,也就大部分的Java程序员控制,而剩下的步骤,都是由JVM去掌控,其中的细节是由JVM开发人员处理,对于上层开发者者是一个黑盒。我们程序员实现了,热部署自定义加载的等等的功能。
类加载
“通过一个类的全限定名来获取描述该类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需的类。实现这个动作的代码被称为“类加载器”(Class Loader)。
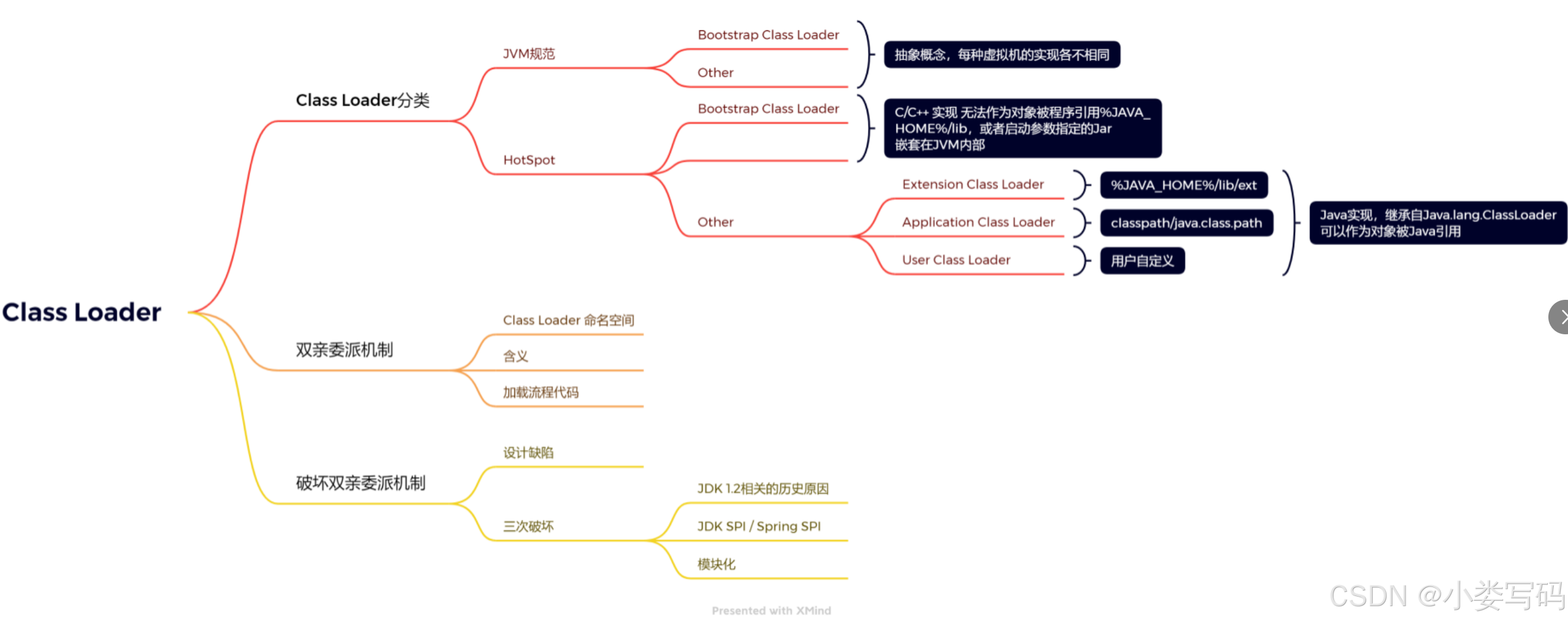
Class Loader 分类是属于 Jvm的规范是一种抽象的概念,各JVM的实现是不用的。JVM类加载器中分为两种一种是Bootstrap Class Loader 和其他Class Loader。
Bootstrap ClassLoader 启动类加载器
Bootstrap ClassLoader
加载$JAVA_HOME中 jre/lib/rt.jar里所有的class或Xbootclasspath选项指定的jar包!
这些类是 Java 运行的基础类,BootstrapClassLoader比较特殊,它不继承ClassLoader,而是由 JVM 内部实现;
C++实现,并非java代码实现,所以在JVM虚拟机规范中的支持两种类型的类加载器,分别为引导类加载器(Bootstrap ClassLoader)和自定义类加载器(User-Defin ed ClassLoader),什么拓展类,应用程序类、自动类都可以称为自定义类加载器
其他Other 类加载器
Extension ClassLoader 扩展类加载器
加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/ext/*.jar或-Djava.ext.dirs(启动指令属性)指定目录下的jar包,比如
C:\Program Files\Java\jdk1.8.0_152\jre\lib下的所有jar包的类具体实现为sum.misc.Launcher中的内部类ExtClassLoader
Application ClassLoader 系统类加载器
加载classpath中指定的jar包及 -Djava.class.path所指定目录下的类和jar包具体实现为sum.misc.Launcher中的内部类AppClassLoader;
我们平时写的代码都是用Application ClassLoader进行加载的。
Custom ClassLoader 系统类加载器
前面3个是java自带的,提供好了的,那么我们也可以自定义!我们可以获取任何来源的字节码进行加载。
通过java.lang.ClassLoader的子类自定义加载class,属于应用程序根据自身需要自定义的,ClassLoader,如tomcat、 jboss都会根据j2ee规范自行实现ClassLoader
类加载的命名空间
1.不同的类加载器,除了读取二进制流的动作和范围不一样,后续的加载逻辑是否也不一样?
2.遇到限定名一样的类,这么多类加载器会不会产生混乱?JVM规范:每个类都由属于自己的命名空间。
类的加载机制
默认的情况下,一个限定名的类只会被一个类加载器加载解析并使用,这样在程序中,它就是唯一的,不会产生歧义。
为了解决这个需求,我们开发者引用了双亲委派模型。
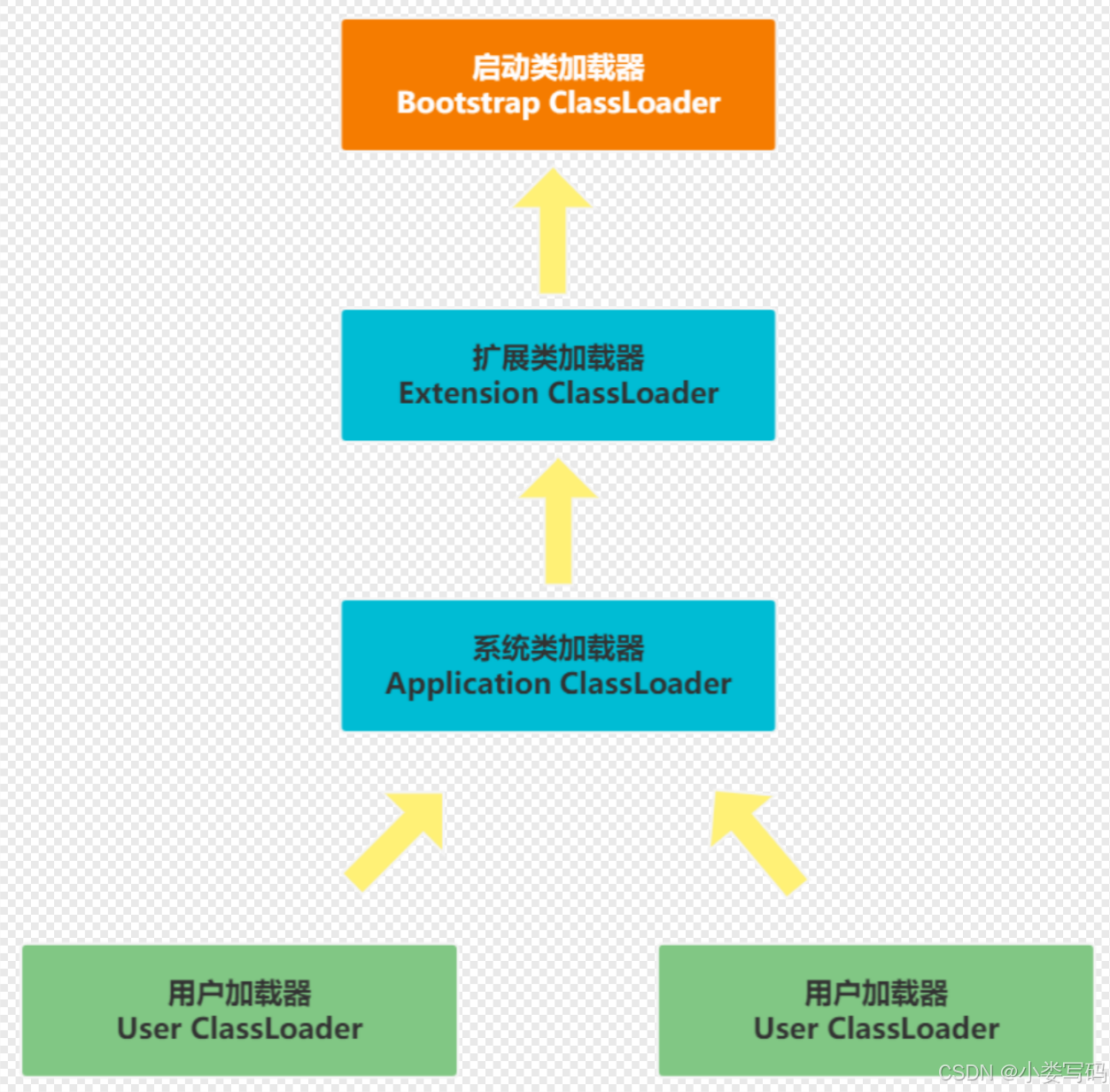
1. 全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
2. 缓存机制。缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
3. 双亲委派:所谓的双亲委派,则是先让父亲加载器试图加载该Class,只有在父亲加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
打破双亲委派机制
在大部分情况下,双亲委派机制是能够生效并且是能按预期执行的。
第一次被破坏
在一些情况下,双亲委派机制是可以主动破坏的,细心的同学可以发现,我自己通过匿名内部类直接重写了java.lang.classloader的load class方法,而我们的双亲委派机制是存在于这个方法内的。那么我们这次重写就是对原有的双亲委派机制的逻辑破坏,所以也出现同一个限定名出现了两个不同classloader进行load的情况。
public class CustomClassLoaderDemo {
public static void main(String[] args) throws Exception {
ClassLoader myLoader = new ClassLoader() {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
try {
// 修正了方法名、变量名、字符串和语法错误
String fileName = name.substring(name.lastIndexOf(".") + 1) + ".class";
InputStream is = getClass().getResourceAsStream("/" + fileName); // 通常需要加上"/"来指定根路径
if (is == null) {
return super.loadClass(name);
}
byte[] b = new byte[is.available()];
is.read(b);
return defineClass(name, b, 0, b.length); // 修正了off的拼写为0
} catch (IOException e) { // 修正了异常类的拼写
throw new ClassNotFoundException(name);
}
}
};
// 修正了方法调用和参数格式
Object obj = myLoader.loadClass("com.jvm.clazzloader.NameSpaceClassLoader").newInstance();
System.out.println(obj.getClass());
System.out.println(obj instanceof com.jvm.clazzloader.NameSpaceClassLoader);
}
}
// 注意:上述代码假设com.jvm.clazzloader.NameSpaceClassLoader类在类路径下是可用的,
// 并且该类有一个无参数的构造方法。如果该类不存在或无法加载,将抛出ClassNotFoundException。
// 此外,newInstance()方法在Java 9及以上版本中已被弃用,建议使用Class.getDeclaredConstructor().newInstance()代替。除非是有特殊的业务场景,一般来说不要主动去破坏双亲委派模型。
那有的人可能会有疑问啦,既然jvm推荐并希望开发者遵循双亲尾派模型,那么为什么不把load class方法像defineClass设定成final来修饰?
那这样的话我这边就没有办法重写,也就代表着上层开发者需要尽可能的遵循双亲委派的逻辑了。
这是JVM无法解决的问题
java.lang.ClassLoader 的load class方法呢在java很早的版本就有了,而双亲委派模型是在jdk1.2引入的特性。
java是向下兼容的,也就是说引入双擎委派机制时呢,世界上已经存在了很多像我上面一样的代码,那么jvm只能向下兼容的,只能提出折中的解决方式。
这个解决的措施就是在Jdk1.2后,引入了findclass方法,推荐用户去重写该方法,而不是直接重写 Load class方法,这样呢就依然能够符合双亲委派模型。
这就是史上第一次的双亲委派模型被破坏了,像很多事情(*装)只有零次和N次,双亲委派模型第二次被破坏,是由于这个模型自身的缺陷导致,双亲委派能很好的解决了各个类加载器协作时基础类型的一致性问题,但是如果有基础类型要调用用户的代码,这又该怎么办呢?
第二次被破坏
比如说JDK想要提供操作数据库的功能,那么数据库有很多种,并且随着时间的推移将会出现各种品类的数据库,想要JDK需要针对不同的数据库和具体代码都一一实现,这不现实,jdk也不知道各种品类数据里具体的实现方式,那么比较合理的方式就是JDK提供一组规范和接口,各个不同数据库厂商按照这个接口去实现自己的类库。
好,那么问题就出现了。JDK代码包中的加载肯定是使用了上层的类加载器的情
况,二具体实现是由第三方厂商来实现的,加载第三方厂商的类加载器肯定不是bootstrap classloader,但是当你去调用jdk中的接口时呢,接口的所在类必然会引起第三方类库的加载,这就不符合自下而上的委派加载顺序了。出现了了上层加载器调用下层类加载器的情况,就产生了双亲委派模型的破坏。
public static void main(String[] args) {
String url = "jdbc:mysql://192.168.2.2:3306/USER_INNODB?serverTimezone=UTC"; // 修正了URL中的拼写错误
try {
// 注释提到了com.mysql.cj.jdbc.Driver和Bootstrap ClassLoader,但实际代码中未直接使用这些
Connection conn = DriverManager.getConnection(url, "root", "123456"); // 修正了参数格式和字符串拼接错误
System.out.println(DriverManager.class.getClassLoader()); // 打印DriverManager类的类加载器
Enumeration<Driver> drivers = DriverManager.getDrivers(); // 获取已注册的JDBC驱动列表
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
System.out.println(driver.toString()); // 打印驱动信息
System.out.println(driver.getClass().getClassLoader()); // 打印驱动类的类加载器
}
// 注意:原代码中的System.out.println(conn)存在语法错误,应使用英文括号
System.out.println(conn); // 如果需要,打印数据库连接对象(通常不直接打印,这里仅为了展示)
// 注意:在实际应用中,应该处理数据库连接对象conn的关闭逻辑,
// 通常在try-catch-finally块中或使用try-with-resources语句来自动关闭资源。
// 但由于图中代码未展示这部分内容,因此这里也未添加。
} catch (SQLException e) {
// 添加了异常处理来捕获并处理SQL异常
e.printStackTrace();
}
}我们来看一个具体的例子,在这个DriverManager这个类的类加载器为null,我之前说类加载器为null就是Bootstrap Classloader,因为它不可以被Java程序调用(C,C++)编写,而Driver Manager内部加载了两个driver,他们的类加载器都是
Application ClassLoader,这说明不是Bootstrap 进行加载的,而是委托了Application ClassLoader去加载来自第三方的类,这个其实就是Java的SPI。
SPI 怎么做呢?
为了解决这个困境,Java的设计团队只好引入了一个不太优雅的设计:线程上下
文类加载器 (Thread Context ClassLoader)。这个类加载器可以通过
java.lang.Thread类的setContext-ClassLoader()方 法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
有了线程上下文类加载器,程序就可以做一些不符合双亲委派模型的事情了。JNDI服务使用这个线程上下文类,加载器去加载所需的SPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,已经违背了双亲委派模型的一般性原则,但也是无可奈何的事情。
Java中涉及SPI的加载基本上都采用这种方式来完成,例如JNDI、 JDBC、JCE、JAXB和JBI等。不过,当SPI的服务提供者多于一个的时候,代码就只能根据具体提供者的类型来硬编码判断,为了消除这种极不优雅的实现方式,在JDK 6时,JDK提供了java.util.ServiceLoader类,以META-INF/services中的配置信息,辅以责任链模式,这才算是给SPI的加 载提供了一种相对合理的解决方案。
Spring Boot 当中的SPI机制也是在JDK的机制之上去完成的,实现的思路是一样的,只不过会比JDK的实现更加优雅。
家会觉得双亲委派模型是一种非常失败的设计,这一点在我看来并不是这样的,我觉得大部分的场景下,它有效的对上层程序员提供了一个接口和方法,让程序要实现了动态代理或者热部署,让程序要不需要主动干涉程序中类加载情况,已经实现了它最大的价值,保护了JVM,在发现了缺陷时呢也能够设计出较为优雅的补救措施,所以整体上我认为双亲委派模型是非常不错,如果大家谁有比较好的设计思路,可以发出来一起研究一下。

















 1799
1799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









