






 本文详细介绍了如何在Element-UI项目中通过webpack别名设置,正确导入'main/index.js',并展示了webpack.demo.js中的配置和实际路径映射。
本文详细介绍了如何在Element-UI项目中通过webpack别名设置,正确导入'main/index.js',并展示了webpack.demo.js中的配置和实际路径映射。
Element-UI里的引入Element都是這樣 import Element from 'main/index.js'
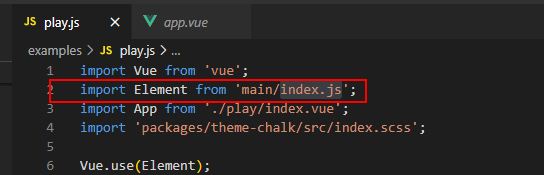
可是在文檔結構里找了一圈也沒有找到main文件
其實這個main是一個別名
在webpack的js文件里設定了對應關係
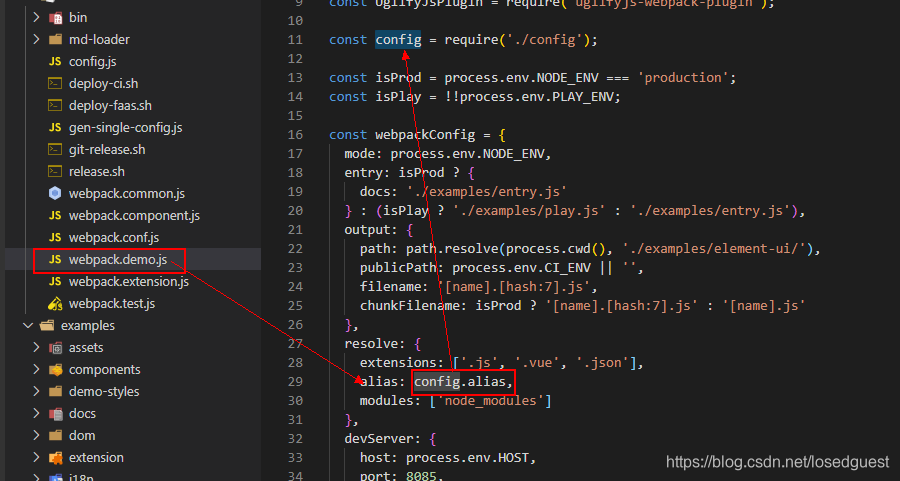
比如當前使用npm run dev:play 運行的項目
npm run dev:play 運行用的webpack.demo.js進行的打包

webpack.demo.js里配置別名設置如下 (引用的config.js里的alias)
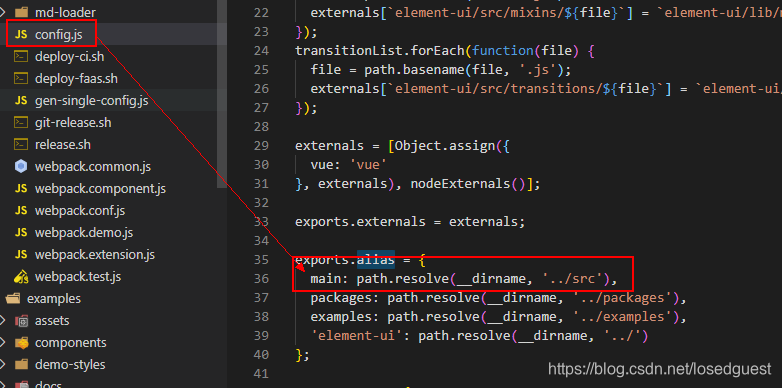
config.js里的配置如下,這裡可可以清楚知道'main/index.js' 指向的是'../src/index.js'

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









