 使用PerfKVM分析无法连接虚机的函数调用
使用PerfKVM分析无法连接虚机的函数调用





 当无法直接连接到虚拟机进行分析时,可以借助PerfKVM在宿主机上进行监控。首先从虚机导出kallsyms和modules文件,然后在宿主机上使用PerfKVM记录并分析指定虚机进程的调用情况。通过示例展示,当虚机执行dd命令时,观察到大量shmen写操作,验证了分析的有效性。
当无法直接连接到虚拟机进行分析时,可以借助PerfKVM在宿主机上进行监控。首先从虚机导出kallsyms和modules文件,然后在宿主机上使用PerfKVM记录并分析指定虚机进程的调用情况。通过示例展示,当虚机执行dd命令时,观察到大量shmen写操作,验证了分析的有效性。
背景:
当需要分析虚机内部函数调用情况,有时候无法连接到虚机(例如ssh和vnc都连不进去),这时候常规手段就无法进行分析。此时可用perf kvm在宿主机上去分析虚机内部得调用情况。
步骤:
1. 导出虚机内部的kallsyms和modules文件到宿主机上。如果虚机已经无法连接进去,可找一台相同的虚机(内核和硬件配置都一致)并导出这两个文件。下面示例,guest对应待导出文件的虚机。
ssh guest "cat /proc/kallsyms" > /tmp/guest.kallsyms
ssh guest "cat /proc/modules" > /tmp/guest.modules
2. 在宿主机上开始监测,pid对应虚机的主进程号:
perf kvm --host --guest --guestkallsyms=/tmp/guest.kallsyms --guestmodules=/tmp/guest.modules record -p pid -a -g
采集一段时间后 ctrl + c停止采集,会在当前目录下生成perf.data.kvm文件
3. 分析采集报告:
perf kvm --guest --guestkallsyms=/tmp/guest.kallsyms --guestmodules=/tmp/guest.modules report -i perf.data.kvm
示例:
测试在虚机上进行dd命令:
dd if=/dev/zero of=/tmp/tmp.bin bs=1048576 count=10240
在宿主机上执行采集分析后得到下面结果:
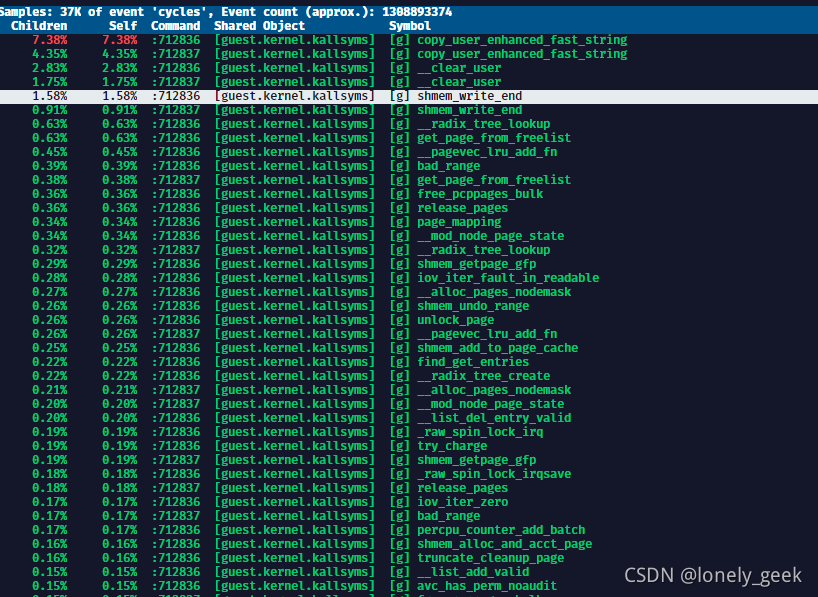
可以看出有大量的shmen写操作,符合预期

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









