






引言
相信大家在编写SQL时一定有一个困扰,就是明明记得数据库中有个命令/函数,可以实现自己需要的功能,但偏偏不记得哪个命令该怎么写了,这时只能靠盲目的去百度,以此来寻找自己需要的命令。
时间是最厉害的武器,少年定会白首,鲜花亦会凋零,沧海会演变桑田,高山也会化作平原。
而我们每一位开发者,作为人类也不例外,无法抵挡时间的流逝,其记忆力会随着时间逐渐推移不断下降,而MySQL中的命令/函数那么多,咱们也并不能完全记住,所以对于前面的那种情况,在实际开发中也属常事,所以本章则会将一些常用的SQL命令/函数全部罗列出来,以后当需要用到时只需回来搜索即可。
PS:个人编写的《技术人求职指南》小册已完结,其中从技术总结开始,到制定期望、技术突击、简历优化、面试准备、面试技巧、谈薪技巧、面试复盘、选Offer方法、新人入职、进阶提升、职业规划、技术管理、涨薪跳槽、仲裁赔偿、副业兼职……,为大家打造了一套“从求职到跳槽”的一条龙服务,同时也为诸位准备了七折优惠码:3DoleNaE,近期需要找工作的小伙伴可以复制链接了解详情:https://s.juejin.cn/ds/USoa2R3/
当大家以后需要使用某条命令/函数时,可以很好的利用这篇命令大全来辅助您,方式有两种:
-
• ①按下
Ctrl+F搜索快捷键,搜索关键词用于定位相应的命令。 -
• ②本文会以功能对所有命令进行分类,通过右侧的文章目录可按功能快捷调整命令位置。
当然,如若本文对你有些许帮助,那请不要忘了点赞支持一下噢~
一、基础操作与库命令
首先来介绍一些关于MySQL基础操作的命令,以及操作数据库相关的命令,MySQL中的所有命令默认是以;分好结尾的,因此在执行时一定要记得带上分号,否则MySQL会认为你这条命令还未结束,会继续等待你的命令输入,如下:

等待输入
1.1、MySQL基础操作命令
-
•
net start mysql:Windows系统启动MySQL服务。 -
•
安装目录/mysql start:Linux系统启动MySQL服务。 -
•
shutdown:后面的start换成这个,表示关闭MySQL服务。 -
•
restart:换成restart表示重启MySQL服务。 -
•
ps -ef | grep mysql:Linux查看MySQL后台进程的命令。 -
•
kill -9 MySQL进程ID:强杀MySQL服务的命令。 -
•
mysql -h地址 -p端口 -u账号 -p:客户端连接MySQL服务(需要二次输入密码)。 -
•
show status;:查看MySQL运行状态。 -
•
SHOW VARIABLES like %xxx%;:查看指定的系统变量。 -
•
show processlist;:查看当前库中正在运行的所有客户端连接/工作线程。 -
•
show status like "Threads%";:查看当前数据库的工作线程系统。 -
•
help data types;:查看当前版本MySQL支持的所有数据类型。 -
•
help xxx:查看MySQL的帮助信息。 -
•
quit:退出当前数据库连接。
1.2、MySQL库相关的命令
-
•
show databases;:查看目前MySQL中拥有的所有库。 -
•
show engines;:查看当前数据库支持的所有存储引擎。 -
•
use 库名;:使用/进入指定的某个数据库。 -
•
show status;:查看当前数据库的状态信息。 -
•
show grants;:查看当前连接的权限信息。 -
•
show errors;:查看当前库中记录的错误信息。 -
•
show warnings:查看当前库抛出的所有警告信息。 -
•
show create database 库名;:查看创建某个库的SQL详细信息。 -
•
show create table 表名;:查看创建某张表的SQL详细信息。 -
•
show tables;:查看一个库中的所有表。 -
•
desc 表名;:查看一张表的字段结构。除开这种方式还有几种方式: -
•
describe 表名;:查看一张表的字段结构。 -
•
show columns from 表名;:查看一张表的字段结构。 -
•
explain 表名;:查看一张表的字段结构。 -
•
create database 库名;:新建一个数据库,后面还可以指定编码格式和排序规则。 -
•
drop database 库名;:删除一个数据库。 -
•
ALTER DATABASE 库名 DEFAULT CHARACTER SET 编码格式 DEFAULT COLLATE 排序规则:修改数据库的编码格式、排序规则。
1.3、MySQL表相关的命令
对于MySQL表相关的命令,首先来聊一聊创建表的SQL命令,如下:
CREATE TABLE `库名`.`表名` (
字段名称1 数据类型(精度限制) [字段选项],
字段名称2 数据类型(精度限制) [字段选项]
) [表选项];
对于表中的每个字段,都需要用,分割,但最后一个字段后面无需跟,逗号,同时创建表时,对于每个字段都有多个字段选项,对于一张表而言也有多个表选项,下面一起来看看。
-
• 字段选项(可以不写,不选使用默认值):
-
•
NULL:表示该字段可以为空。 -
•
NOT NULL:表示改字段不允许为空。 -
•
DEFAULT 默认值:插入数据时若未对该字段赋值,则使用这个默认值。 -
•
AUTO_INCREMENT:是否将该字段声明为一个自增列。 -
•
PRIMARY KEY:将当前字段声明为表的主键。 -
•
UNIQUE KEY:为当前字段设置唯一约束,表示不允许重复。 -
•
CHARACTER SET 编码格式:指定该字段的编码格式,如utf8。 -
•
COLLATE 排序规则:指定该字段的排序规则(非数值类型生效)。 -
•
COMMENT 字段描述:为当前字段添加备注信息,类似于代码中的注释。 -
• 表选项(可以不写,不选使用默认值):
-
•
ENGINE = 存储引擎名称:指定表的存储引擎,如InnoDB、MyISAM等。 -
•
CHARACTER SET = 编码格式:指定表的编码格式,未指定使用库的编码格式。 -
•
COLLATE = 排序规则:指定表的排序规则,未指定则使用库的排序规则。 -
•
ROW_FORMAT = 格式:指定存储行数据的格式,如Compact、Redundant、Dynamic....。 -
•
AUTO_INCREMENT = n:设置自增列的步长,默认为1。 -
•
DATA DIRECTORY = 目录:指定表文件的存储路径。 -
•
INDEX DIRECTORY = 目录:指定索引文件的存储路径。 -
•
PARTITION BY ...:表分区选项,后续讲《MySQL表分区》再细聊。 -
•
COMMENT 表描述:表的注释信息,可以在这里添加一张表的备注。
整体看下来会发现选项还蛮多,下面贴个例子感受一下:
-- 在 db_zhuzi 库下创建一张名为 zz_user 的用户表
CREATETABLE`db_zhuzi`.`zz_user`(
-- 用户ID字段:int类型、不允许为空、设为自增列、声明为主键
`user_id`int(8)NOTNULL AUTO_INCREMENT PRIMARY"i_p_id" COMMENT '用户ID',
-- 用户名称字段:字符串类型、运行为空、默认值为“新用户”
`user_name`varchar(255)NULLDEFAULT"新用户" COMMENT '用户名'
)
-- 存储引擎为InnoDB、编码格式为utf-8、字符排序规则为utf8_general_ci、行格式为Compact
ENGINE =InnoDB
CHARACTERSET= utf8
COLLATE= utf8_general_ci
ROW_FORMAT =Compact;
上述代码块中就贴出了一个创建表的例子,大家在创建表时可根据需求自行选择需要的字段选项、表选项。
接下来一起来看看其他关于表操作的
SQL命令,但对于增删改查的命令会放在后面讲。
-
•
show table status like 'zz_users'\G;:纵排输出一张表的状态信息。 -
•
alter table 表名 表选项;:修改一张表的结构,如alter table xxx engine=MyISAM。 -
•
rename table 表名 to 新表名;:修改一张表的表名。 -
•
alter table 表名 字段操作;:修改一张表的字段结构,操作如下: -
•
add column 字段名 数据类型:向已有的表结构添加一个字段。 -
•
add primary key(字段名):将某个字段声明为主键。 -
•
add foreing key 外键字段 表名.字段名:将一个字段设置为另一张表的外键。 -
•
add unique 索引名(字段名):为一个字段创建唯一索引。 -
•
add index 索引名(字段名):为一个字段创建普通索引。 -
•
drop column 字段名:在已有的表结构中删除一个字段。 -
•
modify column 字段名 字段选项:修改一个字段的字段选项。 -
•
change column 字段名 新字段名:修改一个字段的字段名称。 -
•
drop primary key:移除表中的主键。 -
•
drop index 索引名:删除表中的一个索引。 -
•
drop foreing key 外键:删除表中的一个外键。 -
•
drop table if exists 表名:如果一张表存在,则删除对应的表。 -
•
truncate table 表名:清空一张表的所有数据。 -
•
create table 表名 like 要复制的表名:复制一张表的结构,然后创建一张新表。 -
•
create table 表名 as select * from 要复制的表名:同时复制表结构和数据创建新表。
1.4、表的分析、检查、修复与优化操作
MySQL本身提供了一系列关于表的分析、检查与优化命令:
-
• ①分析表:分析表中键的分布,如主键、唯一键、外键等是否合理。
-
• ②检查表:检查表以及表的数据文件是否存在错误。
-
• ③修复表:当一个表的数据或结构文件损坏时,可以修复表结构(仅支持
MyISAM表)。 -
• ④优化表:消除
delete、update语句执行时造成的空间浪费。
分析表
语法如下:
analyze [local | no_write_to_binlog] table 表名1;
其中的可选参数local、no_write_to_binlog代表是否将本条SQL记录进bin-log日志,默认情况下是记录的,加上这两个参数中的其中一个后则不会记录,执行效果如下:
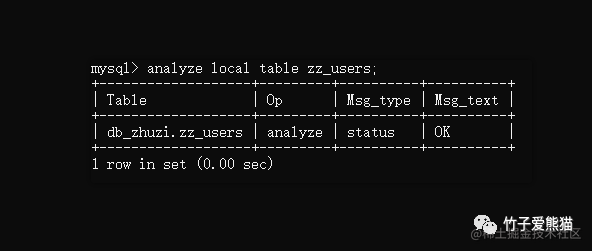
分析表
如果Msg_text显示的是OK,则代表这张表的键不存在问题,存在问题的情况我这边就不模拟了,后面举例聊。
检查表
语法如下:
check table 表名1,表名2... [检查选项];
分析、检查、优化、修复的命令都支持同时操作多张表,不同的表之间只需用,逗号隔开即可。检查命令有多个可选项,如下:
-
•
quick:不扫描行数据,不检查链接错误,仅检查表结构是否有问题。 -
•
fast:只检查表使用完成后,是否正确关闭了表文件的FD文件描述符。 -
•
changed:从上述检查过的位置开始,只检查被更改的表数据。 -
•
medium:检查行数据,收集每一行数据的键值(主键、外键…),并计算校验和,验证数据是否正确。 -
•
extended:对每行数据的所有字段值进行检查,检查完成后可确保数据100%正确。
先来看看执行结果吧,如下:

检查表
这回的结果出现了些许不同,Msg_text中出现了一个Error信息,提示咱们检查的zz_u表不存在,而对于一张存在的zz_users表,则返回OK,表示没有任何问题。
当然,这里对于其他的检查选项就不做测试了,大家可以自行实验,比如把表的结构文件或数据文件,在本地打开手动删除前面的一点点数据,然后再执行检查命令,其实你也可以观察到,提示“数据不完整”的信息(但需要先停止运行
MySQL,并且用本地表测试,不要用线上表瞎搞)。
修复表
语法如下:
repair [local | no_write_to_binlog] table 表名 [quick] [extended] [use_frm];
值得一提的是,修复表的命令不支持InnoDB引擎,仅支持MyISAM、CSV、引擎,比如基于InnoDB引擎的表执行修复命令时,提示如下:
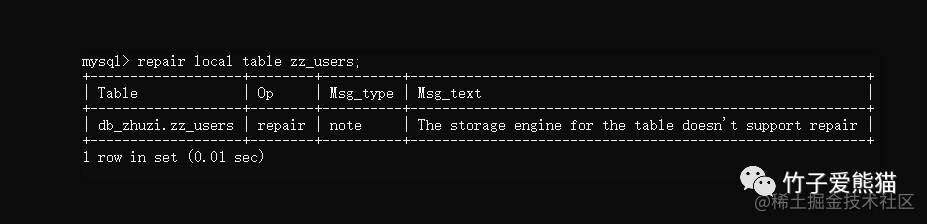
修复表
上述Msg_text信息翻译过来的意思是:选择的表其引擎并不支持修复命令。
InnoDB引擎其实也有修复机制,可以在my.ini/my.conf文件中加一行配置:[mysqld]innodb_force_recovery = 1,这样在启动时会强制恢复InnoDB的数据。
上述这个修复机制默认是不开启的,因为InnoDB不需要这个恢复机制,毕竟之前在《引擎篇》中聊过:InnoDB有完善的事务和持久化机制,客户端提交的事务都会持久化到磁盘,除非你人为损坏InnoDB的数据文件,否则基本上不会出现InnoDB数据损坏的情况。
优化表
语法如下:
optimize [local | no_write_to_binlog] table 表名;
这里值得一提的是:此优化非彼优化,并不意味着你的表存在性能问题,执行后它会自动调优,而是指清除老数据,执行效果如下:
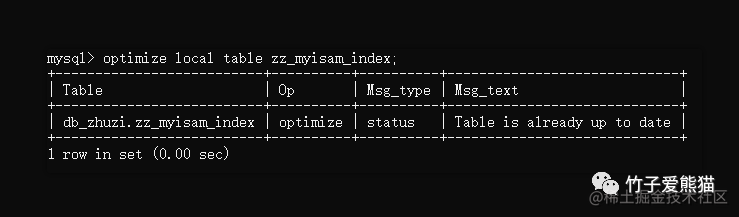
优化表
还记得之前在《MVCC机制》中聊过的隐藏字段嘛?其实删除一条数据本质上并不会立马从磁盘移除,而是会先改掉隐藏的删除标识位,执行这条优化命令后,MySQL会将一些已经delete过的数据彻底从磁盘删除,从而释放这些“废弃数据”占用的空间。
上面的执行结果显示:“目前表的数据已经是最新的了”,这是啥原因呢?因为我这张表中压根没有数据,哈哈哈,没有插入过数据,自然也不会有删除数据的动作,因此就会出现这个提示。
OK~,到这里对于分析表、检查表、修复表以及优化表就已经介绍清楚啦!其实这几个功能,在mysqlcheck工具中也有提供。
1.5、MySQL忘记密码怎么办?
到这里,对于一些MySQL基础命令、库表命令就打住了,最后再来讲一个比较实用的知识点:**MySQL忘记密码怎么办**?对于这种情况其实也十分常见,哪忘记时该如何处理呢?可以重置密码!
①先停掉MySQL的后台服务:
-
•
Windows系统请执行:net stop mysql -
•
Linux系统请执行:安装目录/mysql shutdown(kill强杀进程也可以)
②进入到MySQL安装目录下的bin文件夹内,执行mysqld --skip-grant-tables去掉连接认证。
③因为上面关掉了连接认证,接着输入mysql敲下回车,进入mysql终端命令行。
④输入use mysql;,进入MySQL自身的系统数据库,然后输入show tables;查看所有表。
⑤查询MySQL中注册的所有用户:select user,host,password from user;。
⑥使用update语句,更改root超级管理员的账号密码,如下:
update user set password=password('123') where user="root" and host="localhost";
因为
MySQL本身会用一张用户表来存储所有已创建的账号信息,连接时的效验基准也是来自于该表中的数据,因此在这里修改密码后,再用新密码登录即可!
如果不是root账号的密码忘记了,则可以直接登录root账号修改其他用户的密码,如果是root账号则按照上述流程操作。
完成之后可以用
mysql -uroot -p123连接一下,测试密码是否被重置。
二、增删改查语句
2.1、基本的增删改查语句
插入数据
增删改查俗称为CRUD,这也是MySQL运行之后执行次数最多的一类SQL语句,同时也是每位开发者写的最多的SQL语句,接下来则说说这块的语句,首先登场的是咱们的几位老伙伴,即insert、delete、update、select...这类普通SQL语句。
-
•
insert into 表名(字段名...) values(字段值...);:向指定的表中插入一条数据。 -
•
insert into 表名(字段名...) values(字段值...),(...)...;:向表中插入多条数据。 -
•
insert into 表名 set 字段名=字段值,...;:插入一条数据,但只插入某个字段的值。
如果要插入一条完整的数据,字段名可以用*代替所有字段,除开上述两种插入数据的基本方式外,还有几种批量插入的方式,如下:
-- 使用insert语句批量插入另一张表中查询的数据
insert into 表名(字段名...) select 字段名... from 表名...;
-- 使用replace语句来实现批量插入
replace into 表名(字段名1,字段名2...) values(字段值....),(字段值...),...;
上述批量插入数据的方式中,还可以通过replace关键字来实现插入,它与insert有啥区别呢?答案在于它可以实现批量更新,使用replace关键字来插入数据的表必须要有主键,MySQL会根据主键值来决定新增或修改数据,当批量插入的数据中,主键字段值在表中不存在时,则会向表中插入一条相应的数据,而当插入数据中的主键值存在时,则会使用新数据覆盖原有的老数据。
删除数据
-
•
delete from 表名;:删除一张表的所有数据。 -
•
delete from 表名 where 条件;:根据条件删除一条或多条数据。 -
•
truncate table 表名:清空一张表的所有数据。
修改数据
-
•
update 表名 set 字段名=字段值,...;:修改表中所有记录的数据。 -
•
update 表名 set 字段名=字段值,... where 条件;:根据条件修改一条或多条记录的数据。 -
•
replace 表名(字段名1,...) values(字段值...),...;:批量修改对应主键记录的数据。
查询数据
-
•
select * from 表名;:查询一张表的所有数据。 -
•
select * from 表名 where 条件;:根据条件查询表中相应的数据。 -
•
select 字段1,字段2... from 表名 where 条件;:根据条件查询表中相应数据的指定字段。 -
•
select 函数(字段) from 表名;:对查询后的结果集,进行某个函数的特殊处理。
上述三种是最基本的查询方式,接着来看一些高级查询语法,如下:
-- 为查询出来的字段取别名
select字段1as别名,...from表名where条件;
select字段1别名,...from表名;
-- 为查询出的表取别名
select*from表名as别名;
-- 以多条件查询数据
select*from表名where字段1=值1and字段2=值2and...;-- 所有条件都符合时才匹配
select*from表名where字段1=值1or字段2=值2or...;-- 符合任意条件的数据都会返回
-- =符号,可以根据情况换为>、<、>=、<=、!=、between and、is null、not is null这些
-- 对查询后的结果集使用函数处理
select函数(字段)from表名where条件;
-- 对查询条件使用函数处理
select*from表名where函数(条件);
-- 模糊查询
select*from表名where字段like"%字符";-- 查询字段值以指定字符结尾的所有记录
select*from表名where字段like"字符%";-- 查询字段值以指定字符开头的所有记录
select*from表名where字段like"%字符%";-- 查询字段值包含指定字符的所有记录
-- 按照多值查询对应行记录
select*from表名where字段in(值1,值2,...);
-- 按照多值查询相反的行记录
select*from表名where字段notin(值1,值2,...);
-- 基于多个字段做多值查询
select*from表名where(字段1,字段2...)in((值1,值2,...),(...),...);
-- 只需要查询结果中的前N条数据
select*from表名 limit N;
-- 返回查询结果中 N~M 区间的数据
select*from表名 limit N,M;
-- 联合多条SQL语句查询(union all表示不去重,union表示对查询结果去重)
select*from表名where条件
unionall
select*from表名where 条件;
当然,对于MySQL中支持的函数稍后再展开聊,下面再聊聊一些其他的高级查询语法,如分组、过滤、子查询、关联查询等。
分组过滤、数据排序
写SQL语句时,有些需求往往无法通过最基本的查询语句来实现,因此就需要用到一些高级的查询语法,例如分组、过滤、排序等操作,接着先聊聊这个,语法如下:
-- 基于一个字段进行排序查询
select*from表名orderby字段名asc;-- 按字段值正序返回结果集
select*from表名orderby字段名desc;-- 按字段值倒序返回结果集
select*from表名orderby字段1asc,字段2desc;-- 按照多字段进行排序查询
-- 基于字段进行分组
select*from表名groupby字段1,字段2....;
-- 基于分组查询后的结果做条件过滤
select*from表名groupby字段1having 条件;
实际上group by、having这些语句,更多的要配合一些聚合函数使用,如min()、max()、count()、sum()、avg()....,这样才能更符合业务需求,但对于聚合函数后面再介绍,先简单说说where、having的区别:
这两个关键字都是用来做条件过滤的,但
where优先级会比group by高,因此当分组后需要再做条件过滤时,就无法使用where来做筛选,而having就是用来对分组后的结果做条件过滤的。查询语句中的各类关键字执行优先级为:from → where → select → group by → having → order by。
子查询
子查询也可以理解成是查询嵌套,是指一种由多条SQL语句组成的查询语句,语法如下:
-- 基于一条SQL语句的查询结果进一步做查询
select*from(select*from表名where条件)as别名where条件;
-- 将一条SQL语句的查询结果作为条件继续查询(只适用于子查询返回单值的情况)
select*from表名where字段名=(select字段名from表名where条件);
-- 将一条SQL语句的查询结果作为条件继续查询(适用于子查询返回多值的情况)
select*from表名where字段名exists(select字段名from表名where条件);
-- 上述的exists可以换为not exists,表示查询不包含相应条件的数据
-- 将一条SQL语句的多个查询结果,作为条件与多个字段进行范围查询
select*from表名where(字段1,字段2...)in(select字段1,字段2...from 表名);
在上述子查询语法中,exists的作用和in大致相同,只不过not in时会触发全表扫描,而not exists依旧可以走索引查询,因此通常情况下尽量使用not exists代替not in来查询数据。
关联查询
关联查询也被称之为连表查询,也就是指利用主外键连接多张表去查询数据,这几乎也是日常开发中写的最多的一类查询语句,MySQL中支持多种关联类型,如:
-
• 交叉连接
-
• 内连接
-
• 外连接:
-
• 左连接
-
• 右连接
-
• 全连接
语法如下:
-- 交叉连接:默认把前一张表的每一行数据与后一张表的所有数据做关联查询
select*from表1,表2...;-- 这种方式默认采用交叉连接的方式
select*from表1crossjoin表2;-- 显式声明采用交叉连接的方式
-- 内连接:只返回两张表条件都匹配的数据
-- 隐式的内连接写法
select*from表1,表2...where表1.字段=表2.字段...;
-- 等值内连接
select*from表1别名1innerjoin表2别名2on别名1.字段=别名2.字段;
-- 不等式内连接
select*from表1别名1innerjoin表2别名2on别名1.字段<别名2.字段;
-- 左外连接:左表为主,右表为次,无论左表在右表是否匹配,都返回左表数据,缺失的右表数据显示NULL
select*from表1leftjoin表2on表1.字段=表2.字段;
-- 右外连接:和左连接相反,右表为主,左表为次,永远返回右表的所有数据
select*from表1rightjoin表2on表1.字段=表2.字段;
-- 全外连接:两张表没有主次之分,每次查询都会返回两张表的所有数据,不匹配的显示NULL
-- MySQL中不支持全连接语法,只能通过union all语句,将左、右连接查询拼接起来实现
select*from表1leftjoin表2on表1.字段=表2.字段
unionall
select*from表1rightjoin表2on表1.字段=表2.字段;
-- 继续拼接查询两张以上的表
select*from表1leftjoin表2on表1.字段=表2.字段leftjoin表3on表2.字段=表3.字段;
-- 通过隐式连接的方式,查询两张以上的表
select*from表1,表2,表3...where表1.字段=表2.字段and表1.字段=表3.字段...;
-- 通过子查询的方式,查询两张以上的表
select*from
(表1as别名1leftjoin表2as别名2on别名1.字段=别名2.字段)
leftjoin
表3as别名3on别名1.字段=别名3.字段;
对于连表查询的语法相信大家都并不陌生,因此不做过多产生,重点讲一下多表联查时的笛卡尔积问题,所谓的笛卡尔积问题就是指两张表的所有数据都做关联查询,一般连表查询都需要指定连接的条件,但如果不指定时,MySQL默认会将左表每一条数据挨个和右表所有数据关联一次,然后查询一次数据。比如左表有3条数据,右表有4条数据,笛卡尔积情况出现时,一共就会查询出3 x 4 = 12条数据。
笛卡尔积现象出现时,会随着表数据增长越来越大,因此在连表查询时一定要消除笛卡尔积问题,咋消除呢?其实就是指定加上关联条件即可。
至此,对于一些增删改查的基本语句就已介绍清楚啦~,但实际业务开发过程中,往往会结合数据库所提供的函数一起操作,因此接下来再聊聊MySQL支持的函数。
三、MySQL数据库函数
MySQL中提供了丰富的函数支持,包括数学函数、字符串函数、日期和时间函数、条件判断函数、系统信息函数、加密函数、格式化函数等,通过这些函数,一方面可以简化业务的代码量,另一方面还能更好的实现各类特殊业务需求,下来一起来聊聊MySQL支持的函数。
3.1、数学函数
数学函数是MySQL中最常用的一类函数,主要用来处理所有数值类型的字段值,一起来看看。
-
•
abs(X):返回X的绝对值,如传进-1,则返回1。 -
•
ln(X):返回X的自然相对数。 -
•
log(X,Y):返回以X的以Y为底的对数。 -
•
log10(X):返回以X基数为10的对数。 -
•
bin(X):返回X的二进制值。 -
•
oct(X):返回X的八进制值。 -
•
hex(X):返回X的十六进制值。 -
•
mod(X,Y):返回X除以Y的余数。 -
•
ceil(X) | ceiling(X):返回不小于X的最小整数,如传入1.23,则返回2。 -
•
round(X):返回X四舍五入的整数。 -
•
floor(X):返回X向下取整后的值,如传入2.34,会返回2。 -
•
greatest(X1,X2....,Xn):返回集合中的最大整数值。 -
•
least(X1,X2....,Xn):返回集合中的最小整数值。 -
•
rand(N):返回一个0~N``0~1之间的随机小数(不传参默认返回0~1之间的随机小数)。 -
•
sign(X):传入正数,返回1;传入负数,返回-1;传入0,返回0。 -
•
pow(X,Y) | power(X,Y):返回X的Y次方值。 -
•
pi():返回四舍五入后的圆周率,3.141593。 -
•
sin(X):返回X的正弦值。 -
•
asin(X):返回X的反正弦值。 -
•
cos(X):返回X的余弦值。 -
•
acos(X):返回X的反余弦值。 -
•
tan(X):返回X的正切值。 -
•
atan(X):返回X的反正切值。 -
•
cot(X):返回X的余切值。 -
•
radians(x):返回x由角度转化为弧度的值。 -
•
degrees(x):返回x由弧度转化为角度的值。 -
•
sqrt(X):返回X的平方根。 -
•
exp(e,X):返回e的x乘方的值。 -
•
truncate(X,N):返回小数X保留N位精准度的小数。 -
•
format(x,y):将x格式化位以逗号隔开的数字列表,y是结果的小数位数。 -
•
inet_aton(ip):将IP地址以数字的形式展现。 -
•
inet_ntoa(number):显示数字代表的IP地址。 -
•
......
3.2、字符串函数
-
•
ascii(C):返回字符C的ASCII码。 -
•
length(S):返回字符串的占位空间,传入“竹子爱熊猫”,返回15,一个汉字占位3字节。 -
•
bit_length(S):返回字符串的比特长度。 -
•
concat(S1,S2,...):合并传入的多个字符串。 -
•
concat_wa(sep,S1,S2...):合并传入的多个字符串,每个字符串之间用sep间隔。 -
•
position(str,s) | locate(str,s):返回s在str中第一次出现的位置,没有则返回0。 -
•
find_in_set(S,list):返回字符串S在list列表中的位置。 -
•
insert(S1,start,end,S2):使用S2字符串替换掉S1字符串中start~end的内容。 -
•
lcase(S) | lower(S):将传入的字符串中所有大写字母转换为小写。 -
•
ucase(S) | upper(S):将传入的字符串中所有小写字母转换为大写。 -
•
left(S,index):从左侧开始截取字符串S的index个字符。 -
•
right(S,index):从右侧开始截取字符串S的index个字符。 -
•
trim(S):删除字符S左右两侧的空格。 -
•
rtrim(S):删除字符S右侧的空格。 -
•
replace(S,old,new):使用new新字符替换掉S字符串中的old字符。 -
•
repeat(str,count):将str字符串重复count次后返回。 -
•
substring(S,index,N):截取S字符串,从index位置开始,返回长度为N的字符串。 -
•
reverse(S):将传入的字符串反转,即传入Java,返回avaJ。 -
•
quote(str):用反斜杠转移str中的英文单引号。 -
•
strcmp(S1,S2):比较两个字符是否相同。 -
•
lpad(str,len,s):对str字符串左边填充len个s字符。 -
•
rpad(str,len,s):对str字符串右边填充len个s字符。 -
•
......
3.3、日期和时间函数
-
•
curdate() | current_date():返回当前系统的日期,如2022-10-21。 -
•
curtime() | current_time():返回当前系统的时间,如17:30:52。 -
•
now() | sysdate():返回当前系统的日期时间,如2022-10-21 17:30:59。 -
•
unix_timestamp():获取一个数值类型的unix时间戳,如1666348711。 -
•
from_unixtime():将unix_timestamp()获取的数值时间戳,格式化成日期格式。 -
•
month(date):获取date中的月份。 -
•
year(date):获取date中的年份。 -
•
hour(date):获取date中的小时。 -
•
minute(date):获取date中的分钟。 -
•
second(date):获取date中的秒数。 -
•
monthname(date):返回date中月份的英文名称。 -
•
dayname(date):获取日期date是星期几,如Friday。 -
•
dayofweek(date):获取date位于一周的索引位置,周日是1、周一是2…周六是7。 -
•
week(date):获取date是本年的第多少周。 -
•
quarter(date):获取date位于一年中的哪个季度(1~4)。 -
•
dayofyear(date):获取date是本年的第多少天。 -
•
dayofmonth(date):获取date是本月的第多少天。 -
•
time_to_sec(time):将传入的时间time转换为秒数,比如"01:00:00" = 3600s。 -
•
date_add(date,interval 时间 单位) | adddate(...):将date与给定的时间按单位相加。 -
•
date_sub(date,interval 时间 单位) | subdate(...):将date与给定的时间按单位相减。 -
•
addtime(date,time):将date加上指定的时间,如addtime(now(),"01:01:01")。 -
•
subtime(date,time):将date减去指定的时间。 -
•
datediff(date1,date2):计算两个日期之间的间隔天数。 -
•
last_day(date):获取date日期这个月的最后一天。 -
•
date_format(date,format):将一个日期格式化成指定格式,format可选项如下: -
•
%a:工作日的英文缩写(Sun~Sat)。 -
•
%b:月份的英文缩写(Jan~Dec)。 -
•
%c:月份的数字格式(1~12)。 -
•
%M:月份的英文全称(January~December)。 -
•
%D:带有英文后缀的数字月份(1th、2st、3nd....)。 -
•
%d:一个月内的天数,双数形式(01、02、03....31)。 -
•
%e:一个月内的天数,单数形式(1、2、3、4....31)。 -
•
%f:微妙(000000~999999)。 -
•
%H:一天内的小时,24小时的周期(00、01、02...23)。 -
•
%h | %I:一天内的小时,12小时的周期(01、02、03...12)。 -
•
%i:一小时内的分钟(00~59)。 -
•
%j:一年中的天数(001~366)。 -
•
%k:以24小时制显示时间(00~23)。 -
•
%l:以12小时制显示时间(01~12)。 -
•
%m:月份的数字形式,双数形式(01~12)。 -
•
%p:一天内的时间段(上午AM、下午PM)。 -
•
%r:12小时制的时间(12:01:09 AM)。 -
•
%S | %s:秒数,双数形式(00~59)。 -
•
%T:24小时制的时间(23:18:22)。 -
•
%U:一年内的周(00~53)。 -
•
time_format(time,format):将一个时间格式化成指定格式。 -
•
str_to_date(str,format):将日期字符串,格式化成指定格式。 -
•
timestampdiff(unit,start,end):计算两个日期之间间隔的具体时间,unit是单位: -
•
year:年。 -
•
quarter:季度。 -
•
month:月。 -
•
week:周。 -
•
day:天。 -
•
hour:小时。 -
•
minute:分钟。 -
•
second:秒数。 -
•
microsecond:微妙。 -
•
weekday(date):返回date位于一周内的索引(0是周一…6是周日)。
3.4、聚合函数
聚合函数一般是会结合select、group by having筛选数据使用。
-
•
max(字段名):查询指定字段值中的最大值。 -
•
min(字段名):查询指定字段值中的最小值。 -
•
count(字段名):统计查询结果中的行数。 -
•
sum(字段名):求和指定字段的所有值。 -
•
avg(字段名):对指定字段的所有值,求出平均值。 -
•
group_concat(字段名):返回指定字段所有值组合成的结果,如下: -
•
distinct(字段名):对于查询结果中的指定的字段去重。
这里稍微介绍一个日常业务中碰到次数较多的需求:
select *from zz_users;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
|1|熊猫|女|6666|2022-08-1415:22:01|
|2|竹子|男|1234|2022-09-1416:17:44|
|3|子竹|男|4321|2022-09-1607:42:21|
|4|黑熊|男|8888|2022-09-1723:48:29|
|8|猫熊|女|8888|2022-09-2717:22:29|
|9|棕熊|男|0369|2022-10-1723:48:29|
+---------+-----------+----------+----------+---------------------+
-- 基于性别字段分组,然后显示各组中的所有ID
select
convert(
group_concat(user_id orderby user_id asc separator ",")
using utf8)as"分组统计"
from`zz_users`groupby user_sex;
+-------------+
|分组统计|
+-------------+
|1,8|
|2,3,4,9|
+-------------+
上述利用了group_concat()、group by实现了按照一个字段分组后,显示对应分组的所有ID。
3.5、控制流程函数
-
•
if(expr,r1,r2):expr是表达式,如果成立返回r1,否则返回r2。 -
•
ifnull(v,r):如果v不为null则返回v,否则返回r。 -
•
nullif(v1,v2):如果v1 == v2,则返回null,如果不相等则返回V1。
-- if的用例
selectif(user_id >3,"√","×")from zz_users;
-- ifnull的用例
select ifnull(user_id,"×")from zz_users;
-- case语法1:
case<表达式>
when<值1>then<操作>
when<值2>then<操作>
...
else<操作>
end;
-- 用例:判断当前时间是星期几
selectcase weekday(now())
when0then'星期一'
when1then'星期二'
when2then'星期三'
when3then'星期四'
when4then'星期五'
when5then'星期六'
else'星期天'
endas"今天是星期几?";
-- case语法2:
case
when<条件1>then<命令>
when<条件2>then<命令>
...
else commands
end;
-- 用例:判断今天是星期几
selectcase
when weekday(now())=0then'星期一'
when weekday(now())=1then'星期二'
when weekday(now())=2then'星期三'
when weekday(now())=3then'星期四'
when weekday(now())=4then'星期五'
when weekday(now())=5then'星期六'
else'星期天'
endas"今天是星期几?";
简单聊一下CASE语法,第一种语法就类似于Java中的switch,而第二种语法就类似于多重if,通过CASE语法能够让SQL更加灵活,完成类似于存储过程的工作。
3.6、加密函数
-
•
password(str):将str字符串以数据库密码的形式加密,一般用在设置DB用户密码上。 -
•
md5(str):对str字符串以MD5不可逆算法模式加密。 -
•
encode(str,key):通过key密钥对str字符串进行加密(对称加密算法)。 -
•
decode(str,key):通过key密钥对str字符串进行解密。 -
•
aes_encrypt(str,key):通过key密钥对str字符串,以AES算法进行加密。 -
•
aes_decrypt(str,key):通过key密钥对str字符串,以AES算法进行解密。 -
•
sha(str):计算str字符串的散列算法校验值。 -
•
encrypt(str,salt):使用salt盐值对str字符串进行加密。 -
•
decrypt(str,salt):使用salt盐值对str字符串进行解密。
3.7、系统函数
-
•
version():查询当前数据库的版本。 -
•
connection_id():返回当前数据库连接的ID。 -
•
database() | schema():返回当前连接位于哪个数据库,即use进入的库。 -
•
user():查询当前的登录的所有用户信息。 -
•
system_user():返回当前登录的所有系统用户信息。 -
•
session_user():查询所有连接的用户信息。 -
•
current_user():查询当前连接的用户信息。 -
•
charset(str):返回当前数据库的编码格式。 -
•
collation(str):返回当前数据库的字符排序规则。 -
•
benchmark(count,expr):将expr表达式重复运行count次。 -
•
found_rows():返回最后一个select查询语句检索的数据总行数。 -
•
cast(v as 类型):将v转换为指定的数据类型。
3.8、…
除开上述这些函数之外,其实在
MySQL还有很多很多的函数,但目前几乎已经将所有常用的函数全部列出来了,因此对于其他偏冷门一些的函数就不再介绍。当然,就算你需要的某个功能在MySQL中没有提供函数支持,你也可以通过create function的方式自定义存储函数,其逻辑与上篇讲到的《MySQL存储过程》大致相同。
四、MySQL支持的数据类型
这里所谓的数据类型,也就是只在创建表时可以选择的列字段类型,在MySQL中其实可以通过:
- •
help data types;:查看当前版本支持的所有数据类型。如下(MySQL5.1版本):

数据类型
总体可分为数值类型、字符/串类型、时间/日期类型、其他类型四种,下面一起来聊聊吧。
4.1、数值类型
-
•
tinyint:小整数类型,占位1Bytes,取值范围-128~127。 -
•
smallint:中整数类型,占位2Bytes,取值范围-32768~32767。 -
•
mediumint:中大整数类型,占位3Bytes,取值范围-8388608~8388607。 -
•
int | integer:常用整数类型,占位4Bytes,取值范围-2147483548~2147483647。 -
•
bigint:超大整数类型,占位8Bytes,取值范围-9223372036854775808~9223372036854775807。 -
•
float:单精度浮点数类型,占位4Bytes,取值范围-3.4E+38 ~ 3.4E+38。 -
•
double:双精度浮点数类型,占位8Bytes,取值范围-1.7E-308~1.7E+308。 -
•
decimal(m,d):小数类型,占位和取值范围都依赖m、d值决定,m是小数点后面的精度,d是小数点前面的标度。 -
•
bit(m):存储位值,可存储m个比特位,取值范围是1~64。
4.2、字符串类型
-
•
char:定长字符串类型,存储空间0~255Bytes。 -
•
varchar:变长字符串类型,存储空间0~65535Bytes。 -
•
tinyblob:二进制短字符串类型,存储空间0~255Bytes。 -
•
tinytext:短文本字符串类型,存储空间0~255Bytes。 -
•
blob:二进制长字符串类型,存储空间0~65535Bytes。 -
•
text:长文本字符串类型,存储空间0~65535Bytes。 -
•
mediumblob:二进制大字符串类型,存储空间0~16777215Bytes。 -
•
mediumtext:大文本字符串类型,存储空间0~16777215Bytes。 -
•
longblob:二进制超大字符串类型,存储空间0~4294967295Bytes。 -
•
longtext:超大文本字符串类型,存储空间0~4294967295Bytes。 -
•
binary(m):定长字符串类型,存储空间为M个字符。 -
•
varbinary(m):定长字符串类型,存储空间为M个字符+1个字节。
一般在为列指定数据类型时,都会varchar(255)这样写,其实中间的这个数字限制的并不是字节长度,而是字符数量,比如varchar(255),表示该列最大能存储255个字符。
4.3、时间/日期类型
-
•
date:日期类型,占位3Bytes,格式为YYYY-MM-DD。 -
•
time:时间类型,占位3Bytes,格式为hh:mm:ss。 -
•
year:年份类型,占位1Bytes,格式为YYYY。 -
•
datetime:日期时间类型,占位8Bytes,格式为YYYY-MM-DD hh:mm:ss。 -
•
timestamp:时间戳类型,占位4Bytes,格式为YYYYMMDDhhmmss,最大可精确到微妙。
4.4、其他类型
-
•
json:MySQL5.7版本引入的,在此之前只能用字符串类型来存储json数据,需要通过函数辅助使用: -
•
json_array(...):存储一个json数组的数据。 -
•
json_array_insert(字段,'$[下标]',"值"):在指定的json数组下标位置上插入数据。 -
•
json_object(...):存储一个json对象。 -
•
json_extract(字段,'$.键'):查询键为某个值的所有数据。 -
•
json_search(....):通过值查询键。 -
•
json_keys(字段):获取某个字段的所有json键。 -
•
json_set(字段,'$.键',"值"):更新某个键的json数据。 -
•
json_replace(...):替换某个json中的数据。 -
•
json_remove(字段,'$.键'):删除某个json数据。 -
•
.....:还有一些其他json类型的函数,这里不再说明,一般json类型用的较少。 -
•
enum(选项1,选项2...选项n):新增数据时只能从已有的选项中选择一个并插入。 -
•
set(选项1,选项2...选项n):新增数据时可以从已有的选项中选择多个并插入。 -
•
eometry、point、linestring、polygon:空间类型(接触不多)。
稍微解释一下enum、set类型,这两种类型就类似于平时的单选框和多选框,必须从已有的选项中选择,两者的区别在于:enum枚举类型只能选择一个选项,而set集合类型可以选择多个选项(其实用的比较少,多数情况下都是直接在客户端中处理)。
OK~,简单了解
MySQL支持的数据类型后,接着再来看看其他一些常用的SQL命令。
五、索引相关的命令
-- 创建一个普通索引(方式①)
create index 索引名ON表名(列名(索引键长度)[ASC|DESC]);
-- 创建一个普通索引(方式②)
altertable表名add index 索引名(列名(索引键长度)[ASC|DESC]);
-- 创建一个普通索引(方式③)
CREATETABLE tableName(
columnName1 INT(8)NOTNULL,
columnName2 ....,
.....,
index [索引名称](列名(长度))
);
-- 后续其他类型的索引都可以通过这三种方式创建
-- 创建一个唯一索引
createunique索引名ON表名(列名(索引键长度)[ASC|DESC]);
-- 创建一个主键索引
altertable表名addprimary key 索引名(列名);
-- 创建一个全文索引
create fulltext index 索引名ON表名(列名);
-- 创建一个前缀索引
create index 索引名ON表名(列名(索引键长度));
-- 创建一个空间索引
altertable表名add spatial key 索引名(列名);
-- 创建一个联合索引
create index 索引名ON表名(列名1(索引键长度),列名2,...列名n);
上面将MySQL中创建各类索引的多种方式都列出来了,接着再聊聊索引查看、使用与管理的命令。
-- 查看一张表上的所有索引
show index from表名;
-- 删除一张表上的某个索引
drop index 索引名on表名;
-- 强制指定一条SQL走某个索引查找数据
select*from表名 force index(索引名)where.....;
-- 使用全文索引(自然搜索模式)
select*from表名wherematch(索引列) against('关键字');
-- 使用全文索引(布尔搜索模式)
select*from表名wherematch(索引列) against('布尔表达式'inboolean mode);
-- 使用全文索引(拓展搜索模式)
select*from表名wherematch(索引列) against('关键字'with query expansion);
-- 分析一条SQL是否命中了索引
explain select*from表名where 条件....;
六、事务与锁相关的命令
-
•
start transaction; | begin; | begin work;:开启一个事务。 -
•
commit;:提交一个事务。 -
•
rollback;:回滚一个事务。 -
•
savepoint 事务点名称;:添加一个事务点。 -
•
rollback to 事务点名称;:回滚到指定名称的事务点。 -
•
release savepoint 事务点名称;:删除一个事务点。 -
•
select @@tx_isolation;:查询事务隔离级别(方式一)。 -
•
show variables like '%tx_isolation%';:查询事务隔离级别(方式二)。 -
•
set transaction isolation level 级别:设置当前连接的事务隔离级别。 -
•
set @@tx_isolation = "隔离级别";:设置当前会话的事务隔离级别。 -
•
set global transaction isolation level 级别;:设置全局的事务隔离级别,选项如下: -
•
read uncommitted:读未提交级别。 -
•
read committed:读已提交级别。 -
•
repeatable-read:可重复读级别。 -
•
serializable:序列化级别。 -
•
show variables like 'autocommit';:查看自动提交事务机制是否开启。 -
•
set @@autocommit = 0|1|ON|OFF;:开启或关闭事务的自动提交。 -
•
select ... lock in share mode;:手动获取共享锁执行SQL语句。 -
•
select ... for share;:MySQL8.0之后优化版的共享锁写法。 -
•
select ... for update;:手动获取排他锁执行。 -
•
lock tables 表名 read;:获取表级别的共享锁。 -
•
lock tables 表名 write;:获取表级别的排他锁。 -
•
show open tables where in_use > 0;:查看目前数据库中正在使用的表锁。 -
•
flush tables with read lock;:获取全局锁。 -
•
unlock tables;:释放已获取的表锁/全局锁。 -
•
update 表名 set version=version+1 ... where... and version=version;:乐观锁模式执行。
七、存储过程、存储函数与触发器
-- 创建一个存储过程
DELIMITER $
CREATE
PROCEDURE存储过程名称(返回类型参数名1参数类型1,....)
[......]
BEGIN
-- 具体组成存储过程的SQL语句....
END $
DELIMITER ;
-- 创建一个存储函数
DELIMITER $
CREATE
FUNCTION存储函数名称(参数名1参数类型1,....)
RETURNS数据类型
[NOT]DETERMINISTIC statements
BEGIN
-- 具体组成存储函数的SQL语句....
END $
DELIMITER ;
-- 创建一个触发器
CREATETRIGGER触发器名称
{BEFORE | AFTER}{INSERT|UPDATE|DELETE}ON表名
FOREACHROW
-- 触发器的逻辑(代码块);
-- ------------- 用户变量与局部变量 ---------------
-- 定义、修改用户变量
set@变量名称=变量值;
-- 查询用户变量
select@变量名称;
-- 定义局部变量
DECLARE变量名称数据类型default默认值;
-- 为局部变量赋值(方式1)
SET变量名=变量值;
-- 为局部变量赋值(方式2)
SET变量名:=变量值;
-- 为局部变量赋值(方式3)
select查询结果字段into变量名from表名;
-- ------------- 流程控制 ---------------
-- if、elseif、else条件分支语法
IF 条件判断THEN
-- 分支操作.....
ELSEIF 条件判断 THWN
-- 分支操作.....
ELSE
-- 分支操作.....
END IF
-- case分支判断语句
-- 第一种语法
CASE变量
WHEN值1THEN
-- 分支操作1....
WHEN值2THEN
-- 分支操作2....
.....
ELSE
-- 分支操作n....
ENDCASE;
-- 第二种语法
CASE
WHEN条件判断1THEN
-- 分支操作1....
WHEN条件判断2THEN
-- 分支操作2....
.....
ELSE
-- 分支操作n....
ENDCASE;
-- 循环:LOOP、WHILE、REPEAT
-- loop循环
循环名称:LOOP
-- 循环体....
END LOOP 循环名称;
-- while循环
【循环名称】:WHILE 循环条件 DO
-- 循环体....
END WHILE 【循环名称】;
-- repeat循环
【循环名称】:REPEAT
-- 循环体....
UNTIL 结束循环的条件判断
END REPEAT 【循环名称】;
-- 循环跳转
LEAVE 【循环名称】;-- 结束某个循环体
ITERATE 【循环名称】;-- 跳出某个循环体,继续下次循环
-- ------------- 存储过程的游标 ---------------
-- ①声明(创建)游标
DECLARE游标名称CURSORFORselect...;
-- ②打开游标
OPEN游标名称;
-- ③使用游标
FETCH游标名称INTO变量名称;
-- ④关闭游标
CLOSE 游标名称;
在上面列出了MySQL中存储过程、存储函数与触发器的相关语法,接着再来聊聊管理的命令:
-
•
SHOW PROCEDURE STATUS;:查看当前数据库中的所有存储过程。 -
•
SHOW PROCEDURE STATUS WHERE db = '库名' AND NAME = '过程名';:查看指定库中的某个存储过程。 -
•
SHOW CREATE PROCEDURE 存储过程名;:查看某个存储过程的源码。 -
•
ALTER PROCEDURE 存储过程名称 ....:修改某个存储过程的特性。 -
•
DROP PROCEDURE 存储过程名;:删除某个存储过程。 -
•
SHOW FUNCTION STATUS;:查看当前数据库中的所有存储函数。 -
•
SHOW CREATE FUNCTION 存储过程名;:查看某个存储函数的源码。 -
•
ALTER FUNCTION 存储过程名称 ....:修改某个存储函数的特性。 -
•
DROP FUNCTION 存储过程名;:删除某个存储函数。 -
•
SHOW TRIGGERS;:查看当前数据库中定义的所有触发器。 -
•
SHOW CREATE TRIGGER 触发器名称;:查看当前库中指定名称的触发器。 -
•
SELECT * FROM information_schema.TRIGGERS;:查看MySQL所有已定义的触发器。 -
•
DROP TRIGGER IF EXISTS 触发器名称;:删除某个指定的触发器。
当然,如若你对这块感兴趣,详细的教程可参考上篇:《MySQL存储过程与触发器》。
八、MySQL用户与权限管理
-
•
create user 用户名@'IP' identified by 密码;:创建一个新用户。 -
•
drop user 用户名@'IP';:删除某个用户。 -
•
set password = password(新密码);:为当前用户设置新密码。 -
•
set password for 用户名 = password(新密码);:为指定用户设置新密码(需要权限)。 -
•
alter user 用户名@'IP' identified by 新密码;:使用root账号修改密码。 -
•
mysqladmin -u用户名 -p旧密码 password 新密码;:使用mysqladmin工具更改用户密码。 -
•
rename user 原用户名 to 新用户名;:对某个用户重命名。 -
•
show grants;:查看当前用户拥有的权限。 -
•
show grants for 用户名;:查看指定用户拥有的权限。 -
•
grant 权限1,权限2... on 库名.表名 to 用户名;:为指定用户授予权限。 -
•
*.*:全局权限,表示该用户可对所有库、所有表进行增删改查操作。 -
•
库名.*:单库权限,表示该用户可对指定库下的所有表进行增删改查操作。 -
•
库名.表名:单表权限,表示该用户可对指定表进行增删改查操作。 -
•
insert:插入表数据的权限。 -
•
delete:删除表数据的权限。 -
•
update:修改表数据的权限。 -
•
select:查询表数据的权限。 -
•
alter:修改表结构的alter权限。 -
•
alter routine:修改子程序(存储过程、函数、触发器)的alter权限。 -
•
create:创建表的create权限。 -
•
create routine:创建存储过程、存储函数、触发器的权限。 -
•
create temporary tables:创建临时表的权限。 -
•
create user:创建/删除/重命名/授权用户的权限。 -
•
create view:创建视图的权限。 -
•
drop:删除表的权限。 -
•
execute:执行存储过程的权限。 -
•
file:导出、导入表数据的权限。 -
•
index:创建和删除索引的权限。 -
•
lock tables:获取表锁的权限。 -
•
process:查询工作线程的权限。 -
•
references:这个在MySQL中没有。 -
•
reload:请空表的权限。 -
•
replication clinet:获取主节点、从节点地址的权限。 -
•
replication slave:复制主节点数据的权限。 -
•
show databases:查看所有数据库的权限。 -
•
show view:查看所有视图的权限。 -
•
shutdown:关闭数据库服务的权限。 -
•
super:修改主节点信息的权限。 -
•
all privileges:所有权限。 -
• 权限可选项:
-
•
usage:不授予这些权限。其他权限全部授予。 -
•
grant option:授予这些权限,其他权限全部不授予。 -
• 权限范围可选项:
-
•
revoke 权限1,权限2... on 库名.表名 from 用户名;:撤销指定用户的指定权限。 -
•
revoke all privileges from 用户名 with grant option;:撤销一个用户的所有权限。 -
•
flush privileges;:刷新权限。 -
•
select user,password,host from mysql.user;:查询当前库中的所有用户信息。 -
•
MySQL8.0版本后推出的密码管理机制: -
•
set persist default_password_lifetime=90;:设置所有用户的密码在90天后失效。 -
•
create user 用户@IP password expire interval 90 day;:创建用户时设置失效时间。 -
•
alter user 用户名@IP password expire interval 90 day;:设置指定用户密码失效。 -
•
alter user 用户名@IP password expire never;:设置指定用户的密码永不失效。 -
•
alter user 用户名@IP password expire default;:使用默认的密码失效策略。上述给出了一系列的用户管理和权限管理的命令,最后稍微提一下创建用户时的注意事项:```sql
– 创建一个名为 zhuzi 的用户 create user ‘zhuzi’@‘196.xxx.xxx.xxx’ identified by “123456”;
在创建用户时需要在用户名称后面跟一个`IP`地址,这个`IP`的作用是用来限制登录用户的机器,如果指定为具体`IP`,则表示只能由该`IP`的机器登录该用户,如果写`%`表示任意设备都能使用该用户名登录连接。
>同时也最后提一嘴,`MySQL`对于所有的用户信息,都会放在自带的`mysql`库的`user`表中存储,因此也可以对表执行`insert、delete、update、select`操作,来实现管理用户的功能。
## 九、MySQL视图与临时表
-`create view 视图名 as select ...;`:对查询出的结果集建立一个指定名称的视图。
-`select * from 视图名;`:基于某个已经创建的视图查询数据。
-`show create view 视图名;`:查看某个已存在的视图其详细信息。
-`desc 视图名;`:查看某个视图的字段结构。
-`alter view 视图名(字段1,...) as select 字段1...;`:修改某个视图的字段为查询字段。
-`drop view 视图名;`:删除某个视图。
-`create temporary table 表名(....);`:创建一张临时表(方式1)。
-`create temporary view 表名 as select ...;`:创建一张临时表(方式2)。
-`truncate table 临时表名;`:清空某张临时表的数据。
`MySQL`的临时表本质上是一种特殊的视图,被称为不可更新的视图,也就是临时表只支持查询数据,不支持增删改操作,因此也可以通过创建视图的方式创建临时表,在创建语句中加入`temporary`关键字即可,不指定默认为`undedined`,意思是自动选择视图结构,一般为`merge`结构,表示创建一个支持增删改查的视图。
## 十、数据的导出、导入与备份、还原
数据库的备份其实本质上就是指通过导出数据的形式,或者拷贝表文件的方式来制作数据的副本,数据恢复/还原即是指在数据库故障、异常、错误的情况下,通过导入原本的数据副本,将数据恢复到正常状态,下面来介绍`MySQL`中提供的相关命令。
```sql
-- --------使用 mysqldump 工具做数据的逻辑备份(导出的是sql语句)-----------
-- 导出MySQL中全部的库数据(使用--all-databases 或者 -A 参数)
mysqldump -uroot -p密码 --all-databases > 备份文件名.sql
-- 导出MySQL中一部分的库数据(使用--databases 或者 -B 参数)
mysqldump -uroot -p密码 --databases > 备份文件名.sql
-- 导出MySQL单库中的一部分表数据
mysqldump –u 用户名 –h主机名 –p密码 库名[表名1,表名2...]> 备份文件名.sql
-- 导出MySQL单表的部分数据(使用 --where 参数)
mysqldump -u用户名 -p 库名 表名 --where="条件" > 备份文件名.sql
-- 排除某些表,导出库中其他的所有数据(使用 --ignore-table 参数)
mysqldump -u用户名 -p 库名 --ignore-table=表名1,表名2... > 备份文件名.sql
-- 只导出表的结构(使用 --no-data 或者 -d 选项)
mysqldump -u用户名 -p 库名 --no-data > 备份文件名.sql
-- 只导出表的数据(使用 --no-create-info 或者 -t 选项)
mysqldump -u用户名 -p 库名 --no-create-info > 备份文件名.sql
-- 导出包含存储过程、函数的库数据(使用--routines 或者 -R选项)
mysqldump -u用户名 -p -R --databases 库名 > 备份文件名.sql
-- 导出包含事件(触发器)的库数据(使用 --events 或者 -E选项)
mysqldump -u用户名 -p -E --databases 库名 > 备份文件名.sql
-- --------使用 mysql 工具来恢复备份的数据(导入xx.sql文件执行)-----------
-- 恢复库级别的数据(包含了建库语句的情况下使用)
mysql -u用户名 -p < xxx.sql
-- 恢复库中表级别的数据
mysql -u用户名 -p 库名 < xxx.sql
-- ----------以物理形式备份数据(导出的是表数据) ------------
-- 查看数据库导出数据的路径(如果没有则需在`my.ini/my.conf`中配置)
show variables like '%secure_file_priv%';
-- 导出一张表的数据为txt文件(使用 select ... into outfile 语句)
select * from 表名 into outfile "备份文件名.txt";
-- 导出一张表的数据为txt文件(使用 mysql 工具)
mysql -u用户名 -p --execute="select ...;" 库名 > "数据存放目录/xxx.txt"
-- 导出一张表的结构和数据为sql、txt文件(使用 mysqldump -T 的方式)
mysqldump -u用户名 -p -T "数据存放目录" 库名 文件名
-- 导出一张表的数据为txt文件,以竖排形式存储(使用 mysql –veritcal 的方式)
mysql -u用户名 -p -veritcal --execute="select ...;" 库名 > "数据存放目录/xxx.txt"
-- 导出一张表的数据为xml文件(使用 mysql -xml 的方式)
mysql -u用户名 -p -xml --execute="select ...;" 库名 > "数据存放目录/xxx.xml"
-- -----------通过物理数据文件恢复数据----------------
-- 使用load data infile 的方式导入.txt 物理数据
load data infile "数据目录/xxx.txt" into table 库名.表名;
-- 使用 mysqlimport 工具导入xxx.txt物理数据
mysqlimport -u用户名 -p 库名 '数据存放目录/xxx.txt'
--fields-terminatedby=','
--fields-optionally-enclosed-by='\"'
-- 使用 mysqldump 工具迁移数据
mysqldump –h 地址1 –u用户名 –p密码 –-all-databases | mysql –h地址2 –u用户名 –p密码
上述列出了一系列数据导出导入、备份恢复、迁移等命令,这些都是MySQL自身就支持的方式,但这些自带的命令或工具,在一些情况下往往没有那么灵活、方便,因此在实际情况下,可以适当结合第三方工具来完成,比如:
-
• 较大的数据需要做物理备份时,可以通过
xtrabackup备份工具来完成。 -
•
MySQL5.5版本之前的MyISAM表,可以通过MySQLhotcopy工具做逻辑备份(速度最快)。 -
• 不同版本的
MySQL可以使用XtraBackup备份工具来做数据迁移。 -
•
MySQL、Oracle之间可以通过MySQL Migration Toolkit工具来做数据迁移。 -
•
MySQL、SQL Server之间可以通过MyODBC工具来做数据迁移。
当然,无论是
MySQL自身提供的工具也好,亦或是第三方提供的工具也罢,因为本身就写死了逻辑,因此在有些场景下依旧存在局限性,因此有时咱们也需要写自动化脚本,以此来完成一些特殊的需求。
十一、表分区相关的命令
-- 创建范围分区
createtable`表名`(
`xxx` xxx notnull,
....
)
partitionbyrange(xxx)(
partition分区名1values less than (范围) data directory ="/xxx/xxx/xxx",
partition分区名2values less than (范围) data directory ="/xxx/xxx/xxx",
......
);
-- 创建枚举分区
createtable`表名`(
`xxx` xxx notnull,
....
)
partitionby list(xxx)(
partition分区名1valuesin(枚举值1,枚举值2...),
partition分区名2valuesin(枚举值),
......
);
-- 创建常规哈希分区
createtable`表名`(
`xxx` xxx notnull,
....
)
partitionby hash(xxx)
partitions 分区数量;
-- 创建线性哈希分区
createtable`表名`(
`xxx` xxx notnull,
....
)
partitionby linear hash(xxx)
partitions 分区数量;
-- 创建Key键分区
createtable`表名`(
`xxx` xxx notnull,
....
)
partitionby key(xxx)
partitions 分区数量;
-- 创建Sub子分区
createtable`表名`(
`xxx` xxx notnull,
....
)
partitionbyrange(父分区键)
subpartition by hash(子分区键)(
partition分区名1values less than (范围1)(
subpartition 子分区名1,
subpartition 子分区名2,
......
),
partition分区名2values less than (范围2)(
subpartition 子分区名1,
subpartition 子分区名2,
......
),
......
);
-- 查询一张表各个分区的数据量
select
partition_name as"分区名称",table_rows as"数据行数"
from
information_schema.partitions
where
table_name ='表名';
-- 查询一张表父子分区的数据量
select
partition_name as"父分区名称",
subpartition_name as"子分区名称",
table_rows as"子分区行数"
from
information_schema.partitions
where
table_name ='表名';
-- 查询MySQL中所有表分区的信息
select*from information_schema.partitions;
-- 查询一张表某个分区中的所有数据
select*from表名partition(分区名);
-- 对于一张已存在的表添加分区
altertable表名 reorganize partition分区名into(
partition分区名1values less than (范围) data directory ="/xxx/xxx/xxx",
partition分区名2values less than (范围) data directory ="/xxx/xxx/xxx",
......
);
-- 将多个分区合并成一个分区
altertable表明 reorganize partition分区名1,分区名2...into(
partition新分区名values less than (范围)
);
-- 清空一个分区中的所有数据
altertable表名truncatepartition分区名;
-- 删除一个表的指定分区
altertable表名droppartition分区名;
-- 重建一张表的分区
altertable表名 rebuild partition分区名;
-- 分析一个表分区
altertable表名 analyze partition分区名;
-- 优化一个表分区
altertable表名 optimize partition分区名;
-- 检查一个表分区
altertable表名checkpartition分区名;
-- 修复一个表分区
altertable表名 repair partition分区名;
-- 减少hash、key分区方式的 n 个分区
altertable表名 coalesce partition n;
-- 将一张表的分区切换到另一张表
altertable表名1 exchange partition分区名withtable表名2;
-- 移除一张表的所有分区
altertable表名 remove partitioning;
十二、MySQL、InnoDB、MyISAM的参数
``参数,也被称之为MySQL的系统变量,这些变量是影响MySQL运行的关键,对每个参数做出不同调整,都有可能直接影响到线上数据库的性能,具体的完整系统参数可参考《MySQL官网文档-系统变量》,官方提供的系统参数数量大致如下:
MySQL系统变量
通过xpath的方式提取数据,大概能够得知MySQL系统变量大概一千个上下,因此这里就不做过多的详细介绍,简单介绍一些较为常用的即可,其他具体的可参考前面给出的官网链接。
但是要注意,虽说
MySQL中有一千多个对外暴露的系统参数,但并不是所有的参数都可以让用户调整,MySQL的系统参数分为了三类:
一类是由MySQL自己维护的参数,这类参数用户无法调整。
第二类是以配置文件的形式加载的参数,这类参数必须在MySQL停机的情况下才能更改。
第三类是运行时的系统参数,这类是可以由用户去做动态调整的。
咱们需要关心的重点就是第三类参数,那如何观察这类参数呢?方式如下:
-
•
show global variables;:查看全局所有用户级别可以看到的系统变量。 -
•
show session variables; | show variables;:查看当前会话的所有系统变量。 -
•
show variables like '%关键字%';:使用模糊查询搜索某个系统变量。
MySQL5.1与MySQL8.0版本的执行结果如下:
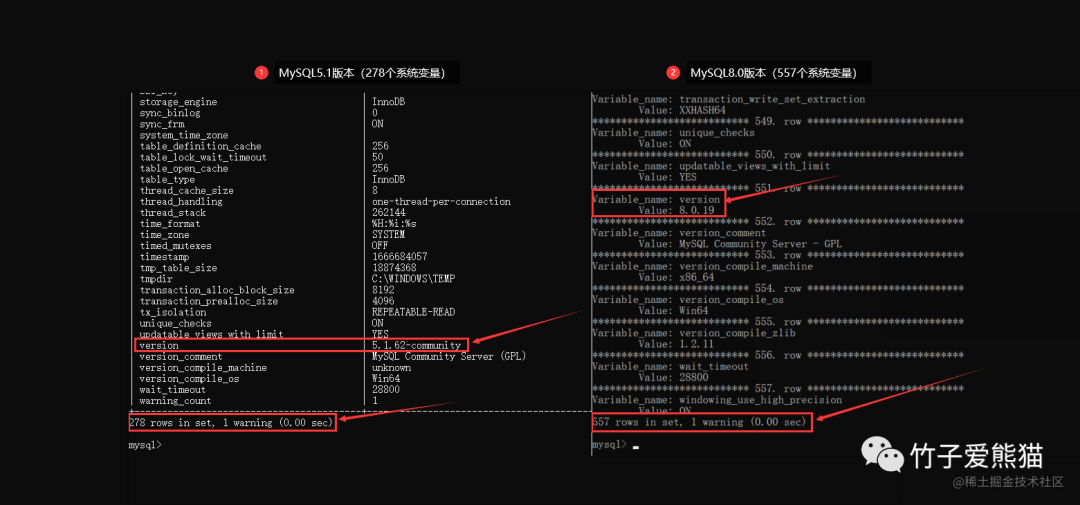
可调整的系统变量
可以很明显的从结果中得知:MySQL5.1版本中存在278个系统变量,MySQL8.0版本中存在557个系统变量,这仅仅只是社区版,而在商业版的MySQL中,其系统参数会更多,下面调出一些重点来聊一聊。
-
•
max_connections:MySQL的最大连接数,超出后新到来的连接会阻塞或被拒绝。 -
•
version:当前数据库的版本。 -
•
ft_min_word_len:使用MyISAM引擎的表中,全文索引最小搜索长度。 -
•
ft_max_word_len:使用MyISAM引擎的表中,全文索引最大搜索长度。 -
•
ft_query_expansion_limit:MyISAM中使用with query expansion搜索的最大匹配数。 -
•
innodb_ft_min_token_size:InnoDB引擎的表中,全文索引最小搜索长度。 -
•
innodb_ft_max_token_size:InnoDB引擎的表中,全文索引最大搜索长度。 -
•
optimizer_switch:MySQL隐藏参数的开关。 -
•
skip_scan:是否开启索引跳跃扫描机制。 -
•
innodb_page_size:InnoDB引擎数据页的大小。 -
•
tx_isolation:事务的隔离级别。 -
•
autocommit:事务自动提交机制。 -
•
innodb_autoinc_lock_mode:插入意向锁的工作模式。 -
•
innodb_lock_wait_timeout:InnoDB锁冲突时,阻塞的超时时间。 -
•
innodb_deadlock_detect:是否开启InnoDB死锁检测机制。 -
•
innodb_max_undo_log_size:本地磁盘文件中,Undo-log的最大值,默认1GB。 -
•
innodb_rollback_segments:指定回滚段的数量,默认为1个。 -
•
innodb_undo_directory:指定Undo-log的存放目录,默认放在.ibdata文件中。 -
•
innodb_undo_logs:指定回滚段的数量,默认为128个,也就是之前的innodb_rollback_segments。 -
•
innodb_undo_tablespaces:指定Undo-log分成几个文件来存储,必须开启innodb_undo_directory参数。 -
•
back_log:回滚日志的最大回撤长度(一条数据的最长版本链长度)。 -
•
innodb_undo_log_truncate:是否开启Undo-log的压缩功能,即日志文件超过一半时自动压缩,默认关闭。 -
•
innodb_flush_log_at_trx_commit:设置redo_log_buffer的刷盘策略,默认每次提交事务都刷盘。 -
•
innodb_log_group_home_dir:指定redo-log日志文件的保存路径,默认为./。 -
•
innodb_log_buffer_size:指定redo_log_buffer缓冲区的大小,默认为16MB。 -
•
innodb_log_files_in_group:指定redo日志的磁盘文件个数,默认为2个。 -
•
innodb_log_file_size:指定redo日志的每个磁盘文件的大小限制,默认为48MB。 -
•
innodb_log_write_ahead_size:设置checkpoint刷盘机制每次落盘动作的大小。 -
•
innodb_log_compressed_pages:是否对Redo日志开启页压缩机制,默认ON。 -
•
innodb_log_checksums:Redo日志完整性效验机制,默认开启。 -
•
log_bin:是否开启bin-log日志,默认ON开启,表示会记录变更DB的操作。 -
•
log_bin_basename:设置bin-log日志的存储目录和文件名前缀,默认为./bin.0000x。 -
•
log_bin_index:设置bin-log索引文件的存储位置,因为本地有多个日志文件,需要用索引来确定目前该操作的日志文件。 -
•
binlog_format:指定bin-log日志记录的存储方式,可选Statment、Row、Mixed。 -
•
max_binlog_size:设置bin-log本地单个文件的最大限制,最多只能调整到1GB。 -
•
binlog_cache_size:设置为每条线程的工作内存,分配多大的bin-log缓冲区。 -
•
sync_binlog:控制bin-log日志的刷盘频率。 -
•
binlog_do_db:设置后,只会收集指定库的bin-log日志,默认所有库都会记录。 -
•
log-error:error-log错误日志的保存路径和名字。 -
•
slow_query_log:设置是否开启慢查询日志,默认OFF关闭。 -
•
slow_query_log_file:指定慢查询日志的存储目录及文件名。 -
•
general_log:是否开启查询日志,默认OFF关闭。 -
•
general_log_file:指定查询日志的存储路径和文件名。 -
•
innodb_buffer_pool_size:InnoDB缓冲区的大小。 -
•
innodb_adaptive_hash_index:是否开启InnoDB的自适应哈希索引机制。 -
•
innodb_compression_level:调整压缩的级别,可控范围在1~9,越高压缩效果越好,但压缩速度也越慢。 -
•
innodb_compression_failure_threshold_pct:当压缩失败的数据页超出该比例时,会加入数据填充来减小失败率,为0表示禁止填充。 -
•
innodb_compression_pad_pct_max:一个数据页中最大允许填充多少比例的空白数据。 -
•
innodb_log_compressed_pages:控制是否对redo-log日志的数据也开启压缩机制。 -
•
innodb_cmp_per_index_enabled:是否对索引文件开启压缩机制。 -
•
character_set_client:客户端的字符编码格式。 -
•
character_set_connection:数据库连接的字符编码格式。 -
•
character_set_database:数据库的字符编码格式。 -
•
character_set_results:返回的结果集的编码格式。 -
•
character_set_server:MySQL-Server的字符编码格式。 -
•
character_set_system:系统的字符编码格式。 -
•
collation_database:数据库的字符排序规则。 -
•
......:剩下的就不再列出来了,大家可根据查询出的变量名,去官网文档查询释义即可。
十三、MySQL常见的错误码
程序Bug、错误、异常…,这些词汇天生与每位程序员挂钩,当一个程序出现问题时,用户第一时间想到的是这个平台的程序员不行,而身为开发者逃不开一点是:又得背锅和加班解决问题!
而MySQL作为整个系统的后方大本营,自然也无法避免会出现错误与异常,在MySQL内部其实定义了一系列错误码,当运行过程中发生错误,或执行语句时出现异常时,一般情况下都会向客户端返回错误码以及错误信息。
但往往很多时候有些错误咱们没见过,所以面对问题时难免有些束手无策,也正因为如此,本节将罗列
MySQL中常见的错误码,当你碰到问题时可以直接通过错误码在此搜索,以此来定位问题出现的原因,以此进一步推导出问题的解决方案。
MySQL的错误信息由ErrorCode、SQLState、ErrorInfo三部分组成,即错误码、SQL状态、错误信息三部分组成,如下:
ERROR 1045 (28000): Access denied for user 'zhuzi'@'localhost' (using password: YES)
其中1045属于错误状态码,28000属于SQL状态,后面跟着的则是具体的错误信息,不过MySQL内部大致定义了两三千个错误码,其错误码的定义位于include/mysqld_error.h、include/mysqld_ername.h文件中,而SQLState的定义则位于include/sql_state.h文件中,所有的错误信息列表则位于share/errmsg.txt文件中,因此大家感兴趣的可自行编译MySQL源码查看。
OK,由于本章篇幅过长,就不再罗列细致的错误码详情了,毕竟当出现错误时,百度、谷歌才是最好的选择,毕竟从上面不仅仅能找到错误码的含义,同时还能找到错误码的解决方案,但为了文章的完整性,再贴一位大佬的→《错误码大全》←的整理:

通篇下来共计16.07W字,里面对于MySQL中90%+的错误码都罗列出来了,但我大致看了一些,有些错误码的描述并不恰当,应该是直接根据share/errmsg.txt文件中的错误信息直接翻译过来的,大家有兴趣可以看看~
十四、MySQL命令大全总结
到这里为止,对于MySQL中大部分常用的命令基本上都已经罗列出来啦!以后如若忘记某个函数名称、某条语句的语法等等,都可以直接在本章中快捷搜索,但本篇仅仅只写出了基本的语法,实际数据库开发中往往还需要结合业务,来编写更为复杂的SQL语句~。本章的主要目的是当成《MySQL命令手册》,本质上没有太多可以学习的知识点,但它却非常实用,能够协助咱们的日常开发。
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图

攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我们和网安大厂360共同研发的的网安视频教程,之前都是内部资源,专业方面绝对可以秒杀国内99%的机构和个人教学!全网独一份,你不可能在网上找到这么专业的教程。
内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。总共200多节视频,200多G的资源,不用担心学不全。

因篇幅有限,仅展示部分资料,需要见下图即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
侵权,请联系删除。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









