 大语言模型微调技术与网安学习资料分享
大语言模型微调技术与网安学习资料分享








一 背景
❝
大型语言模型(LLMs)通常是指具有数千亿参数的Transformer语言模型,这些模型在大规模文本数据上进行训练。LLMs展示了强大的自然语言理解能力和通过文本生成解决复杂任务的能力。2018年后预训练大语言模型的文本理解能力在一些测评上首度超越人类。进而发现一个趋势:增加参数和数据是进一步提高模型性能的有效手段。大模型掌握丰富的知识:世界知识、常识、逻辑推理,只需要少量的提示或者微调,就能激发模型完成指定的任务。
❞
在推动机器语言智能方面,语言建模(LM)是一种重要的技术方法之一。LM旨在建立单词序列的生成概率模型,以预测未来(或缺失)标记的概率。LM的研究已经得到广泛关注,并经历了四个主要的发展阶段。
-
第一个阶段是统计语言模型(SLM),它基于统计学习方法,通过建立单词预测模型来预测下一个单词。SLM在信息检索和自然语言处理等领域取得了一定的成果,但由于数据稀疏性问题,对高阶语言模型的准确估计变得困难。
-
第二个阶段是神经语言模型(NLM),它使用神经网络描述单词序列的概率。NLM引入了词的分布式表示概念,并通过学习单词或句子的有效特征来改进NLP任务的性能。NLM的出现对语言模型的表示学习产生了重要影响。
-
第三个阶段是预训练语言模型(PLM),其中包括BERT和GPT系列。这些模型通过在大规模无标签语料库上进行预训练任务,学习到通用的上下文感知的单词表示。PLM通过预训练和微调的学习范式,在多个NLP任务上取得了显著的性能提升。
-
第四个阶段大模型语言模型(LLM),通过增加模型规模或数据规模来提升性能。LLM展现出了惊人的能力,可以解决复杂的任务,并引发了对人工通用智能(AGI)可能性的重新思考。LLM的快速发展正在推动AI研究领域的创新。
二 技术方案
2.1 Fine-Tuning
「下面来自威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka的总结。」

- Feature-Based Approach
在基于特征的方法中,可以加载预训练的 LLM 并将其应用到我们的目标数据集。生成训练集的输出嵌入可以将其用作输入特征来训练分类模型。虽然这种方法对于像 BERT 这样的以嵌入为中心的模型来说特别常见,但我们也可以从生成式 GPT 风格的模型中提取嵌入。分类模型可以是逻辑回归模型、随机森林或 XGBoost。
- Finetuning I – Updating The Output Layers(「最节省资源的方式」)
目前比较流行的一种方法是微调输出层。与基于特征的方法类似,保持预训练 LLM 的参数冻结。我们只训练新添加的输出层,类似于在嵌入特征上训练逻辑回归分类器或小型多层感知器。通过训练新添加的输出层,进行提取。
- Finetuning II – Updating All Layers(「需要资源多」)
虽然原始 BERT 论文(While the original BERT paper (Devlin 等人Devlin et al.)报告称,仅微调输出层可以获得与微调所有层相当的建模性能,但由于涉及更多参数,因此成本要高得多。例如,BERT 基础模型大约有 1.1 亿个参数。然而,用于二元分类的 BERT 基础模型的最后一层仅包含 1,500 个参数。此外,BERT 基础模型的最后两层包含 60,000 个参数,仅占模型总大小的 0.6% 左右。
我们的里程将根据我们的目标任务和目标域与模型预训练数据集的相似程度而有所不同。但在实践中,微调所有层几乎总是会带来卓越的建模性能。
2.2 parameter-efficient fine-tuning技术
-
其中一种参数高效的fine-tuning技术称为蒸馏(distillation),它由Hinton等人于2015年引入。该方法涉及训练一个较小的模型来模仿一个较大的预训练模型的行为。预训练模型生成“教师”预测结果,然后用于训练较小的“学生”模型。通过这样做,学生模型可以从较大模型的知识中学习,而无需存储所有参数。
-
另一种技术称为适配器训练(adapter training),它由Houlsby等人于2019年引入。适配器是添加到预训练模型中的小型神经网络,用于特定任务的微调。这些适配器只占原始模型大小的一小部分,这使得训练更快,内存需求更低。适配器可以针对多种任务进行训练,然后插入到预训练模型中以执行新任务。
-
第三种技术称为渐进收缩(progressive shrinking),它由Kaplan等人于2020年引入。这种技术涉及在fine-tuning期间逐渐减小预训练模型的大小。从一个大模型开始,逐渐减少参数的数量,直到达到所需的性能。这种方法可以产生比从头开始训练的模型性能更好的小型模型。
2.3 Prompt
❝
当年BERT横空出世,其强大的自然语言处理能力给大家带来震撼的同时也让大家发现该模型训练成本较高,难以基于该模型架构应用在新的领域。因此,fine-tuning技术也随之流行。而进入到ChatGPT时代,有两个问题变得不同:一个是模型规模巨大,传统的fine-tuning也难以进行;另一个是尽管ChatGPT可以更好地理解人类意图,回答人类的问题,但是不同的提问也会影响模型的输出,那么如何合理的提问获得更好的结果也变得重要。
❞
-
测试1

-
测试2

三 参考资料
-
Bert: Pre-training of deep bidirectional transformers for language understanding
-
Scaling down to scale up: A guide to parameter-efficient fine-tuning
-
Parameter-efficient transfer learning for NLP
-
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
-
LoRA: Low-Rank Adaptation of Large Language Models
-
Prompting LeaderBoard http://explainaboard.nlpedia.ai/leaderboard/prompting/
-
Homepage NLPedia http://pretrain.nlpedia.ai/
-
Timeline of Prompt Learning http://pretrain.nlpedia.ai/timeline.html
-
Follow-up : PromptPapers https://github.com/thunlp/PromptPapers
-
Open-Source Framework : OpenPrompt https://github.com/thunlp/OpenPrompt
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
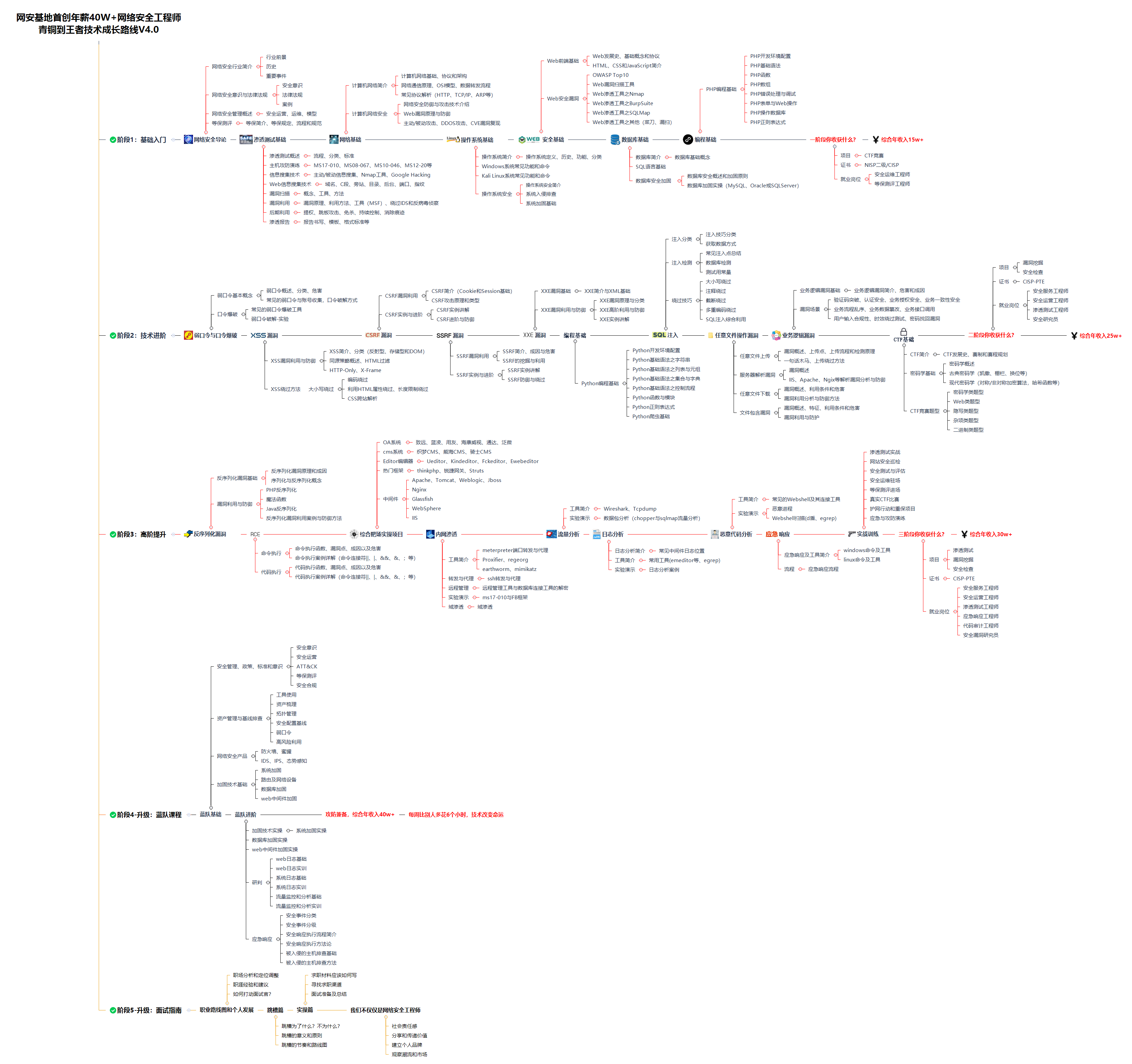
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









