



“ 是时候分享一下数据仓库的精髓:维度建模。”
关于数据仓库相关的内容,我们之前分享过《数据仓库基础概述》,时间比较久远,是去年写的文章了。今天和大家分享一下数据仓库中的维度建模,这是数仓的经典内容。
一、什么是维度建模
维度建模是数据仓库领域的大师之一Ralph Kimball所倡导,他参与所著的《The DataWarehouse Toolkit-The Complete Guide to Dimensona Modeling》,中文名《数据仓库工具箱》,是数据仓库工程领域最流行的数仓建模经典著作。建议有时间的朋友可以读一读。

维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求(也就是我们通常所说的数据分析)服务。它重点解决如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
因此,说白了,所谓的维度建模就是一种组织数据仓库的形式、模型,用这种方式组织搭建的数据仓库,对快速支持数据分析有着巨大的帮助。目前也是比较主流的数仓模型了。
二、维度建模基础知识
下面介绍一下关于维度建模的一些基础知识,主要包括事实表、维度表、切片、钻取等。
(1)事实与事实表(Fact Table)
事实表是指其中保存了大量业务度量数据的表,是数仓最核心的表。
事实表中的度量值一般称为事实。通常,最有用的事实就是数字类型的事实和可加类型的事实。事实表的粒度,决定了数据仓库中数据的详细程度。
下图为例。中间的表:服装销售明细表,就是一张事实表。其中的销售金额、成本、利润,都是事实,也是我们需要分析的目标数据。
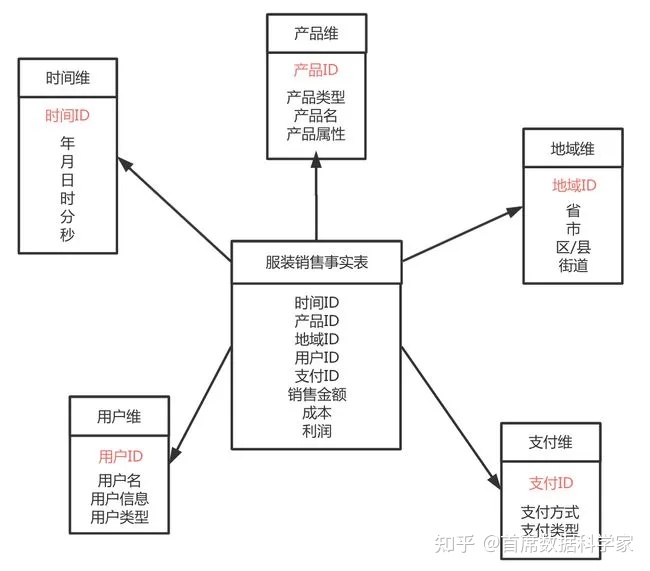
一般事实表中只存放数字或一些flag用来统计,如:销售金额、成本等。另外,通常事实表中的数据不允许修改,新的数据只是简单地添加到事实表中。
事实表特点:数据量庞大、列数少、经常变化。这个比较好理解,因为实事表是一张业务表嘛,业务肯定是不断有新的数据加进来的。
(2)维度与维度表(Dimension Table)
维度表是用户来分析数据的窗口,比如时间、地区、用户等。
维度表中包含事实表中记录的特性,有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息。
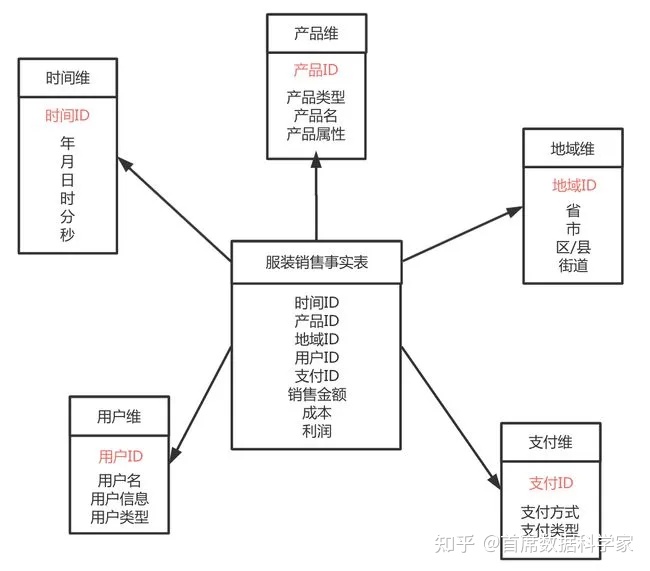
例如上图,包括了五张维度表:时间维表、产品维表、地域维表、用户维表、支付维表。每一张维度表对应现实世界中的一个对象或概念。
每一张维度表利用维度关键字(图中标红字段)通过事实表中的外键约束事实表的中某一行。
维度表等特点:很多描述性的列,行数较少,内容较固定。这个也好理解,比如地域,省市区县这些内容十几年都不会有啥变化。
(3)粒度
粒度是指数据仓库的数据单位中,保存数据的细化程度的级别。简单点来看,在实事表中一条记录所表达的业务细节,就是粒度。
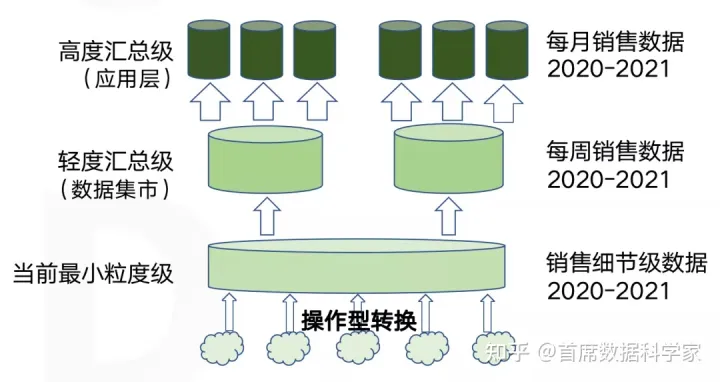
通常,为了便捷的下钻分析,我们都会使用到最小粒度。比如订单表中,最小粒度就是一条订单的记录。使用最小粒度的优点:
- 可以频繁的ETL操作
- 很多数据挖掘需要最小粒度数据
- 方便向下钻取
当然,使用最小粒度也有缺点:
- 存储和维护代价较高
- 需要进一步构建汇总事实表来支持汇总数据查询
(4)切片、切块与旋转
切片与切块主要是用来进行数据分析的。我们以下面的三维(产品、年度、地区)为例。

- 切片:从多维数组中选定一个二维子集,切出一个“平面” 。比如选中上图的2011年,这就是一个切片。
- 切块:从多维数组中选定一个三维子集,切出一个“立方体” 。比如上图中,年度选择了2011、2012,然后看所有的数据内容,这就是一个切块。
- 旋转:改变一个报告(页面)显示的维方向
(5)钻取
根据维层次,改变数据分析的粒度,就是钻取分析,主要包括上钻(也叫上卷)和下钻。其实Excel中的数据透视就是各种上卷和下钻。
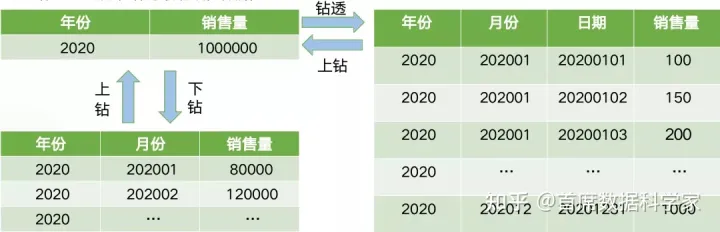
- 下钻:从汇总数据深入到细节数据进行观察或增加新维
- 上钻(上卷):从某一维上将低层次的细节数据概括到高层次的汇总数据或减少维数
- 钻透:直接下钻到最明细的数据。
三、维度建模的三种模型
上面介绍了关于维度建模的一些基础知识,下面聊一聊维度建模的几种具体模型:星型模型、雪花模型、星座模型。
(1)星型模型
所谓星型模型,具体表现是:事实被维度所包围,且维度没有被新的表连接。如下图。
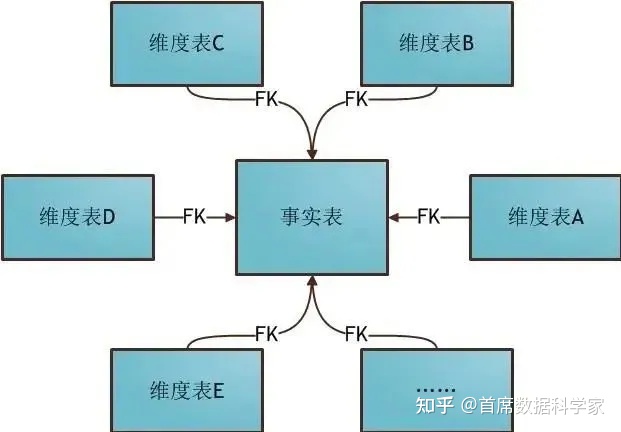
每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。
可以看出,星型模型是比较单纯的模型,像星星一样触角没有延伸了。
(2)雪花模型
所谓的雪花模型,是有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上,就像雪花一样。如下图:
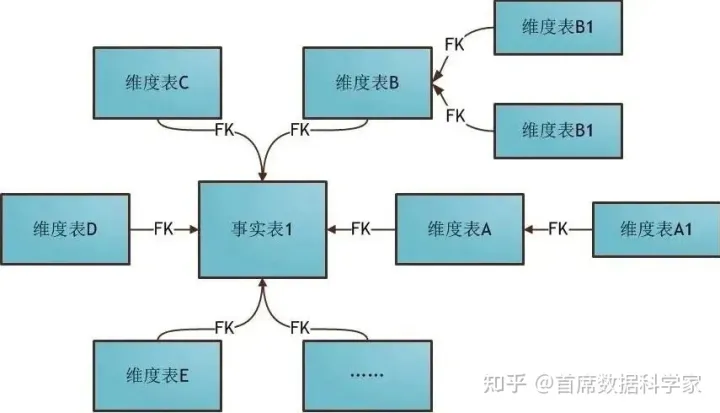
雪花模型去除了数据冗余,更贴近与业务。尽可能降低数据存储量以及联合较小的维表来改善查询性能。
为啥这么说呢?主要是和星型模型对比而言的。看下面的示例图。如果是星型模型,则需要在【product】表中的【category】把所有的信息都列出来,而雪花模型可以在【product】维度表中继续增加关联即可。
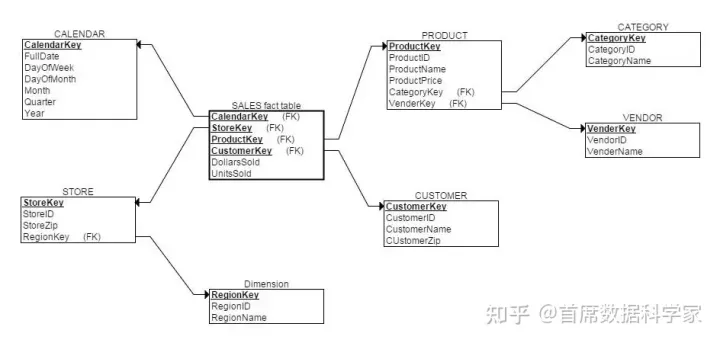
但是可以想象到,雪花模型分析数据时,操作比较复杂。毕竟需要关联的内容越来越多。但数据的存储量下来了,因为冗余信息进行了提炼嘛。
(3)星座模型
无论是星型模型还是雪花模型,都是单事实表的情况。但通常来讲,实践当中大部分情况都是多事实表的。这时就是需要星座模型了。
所谓星座模型,是多个事实表共享维度表, 因而可以视为星型模型的集合,故亦称星座模型(星系模型)。如下图:
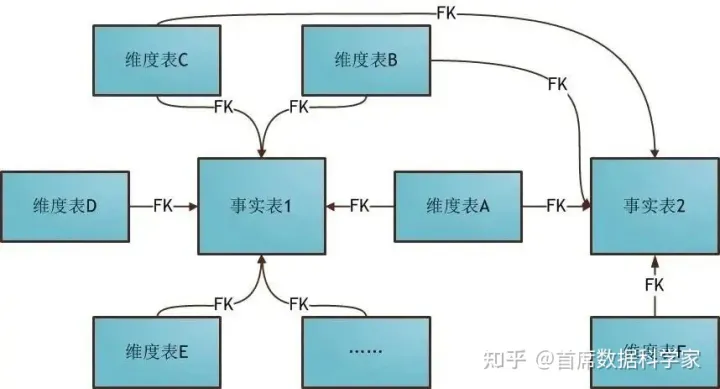
星座模型是数据仓库最常使用的模型。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









