




 本文探讨了如何在Elasticsearch中实现类似SQL的LIKE查询,通过前缀查询、通配符查找和输入即搜索等功能。文章强调了避免性能瓶颈的策略,如在索引时使用边界n-grams进行预处理,以提高模糊搜索效率。
本文探讨了如何在Elasticsearch中实现类似SQL的LIKE查询,通过前缀查询、通配符查找和输入即搜索等功能。文章强调了避免性能瓶颈的策略,如在索引时使用边界n-grams进行预处理,以提高模糊搜索效率。
es如何像sql那样使用like查询,即要查询包含某个词,但搜索只是这个词的一部分
先删除my_index,再初始化mapping:
{
"mappings": {
"address": {
"properties": {
"postcode": {
"type": "keyword"
}
}
}
}
}
索引一些文档:
PUT /my_index/address/1
{ "postcode": "W1V 3DG" }
PUT /my_index/address/2
{ "postcode": "W2F 8HW" }
PUT /my_index/address/3
{ "postcode": "W1F 7HW" }
PUT /my_index/address/4
{ "postcode": "WC1N 1LZ" }
PUT /my_index/address/5
{ "postcode": "SW5 0BE" }
prefix 前缀查询
查询关键词不需要是完整的:

prefix是如何查询的呢?倒排索引的词项是排序的,es先找到第一个w1开头的词项,顺序查找知道开头不是w1.
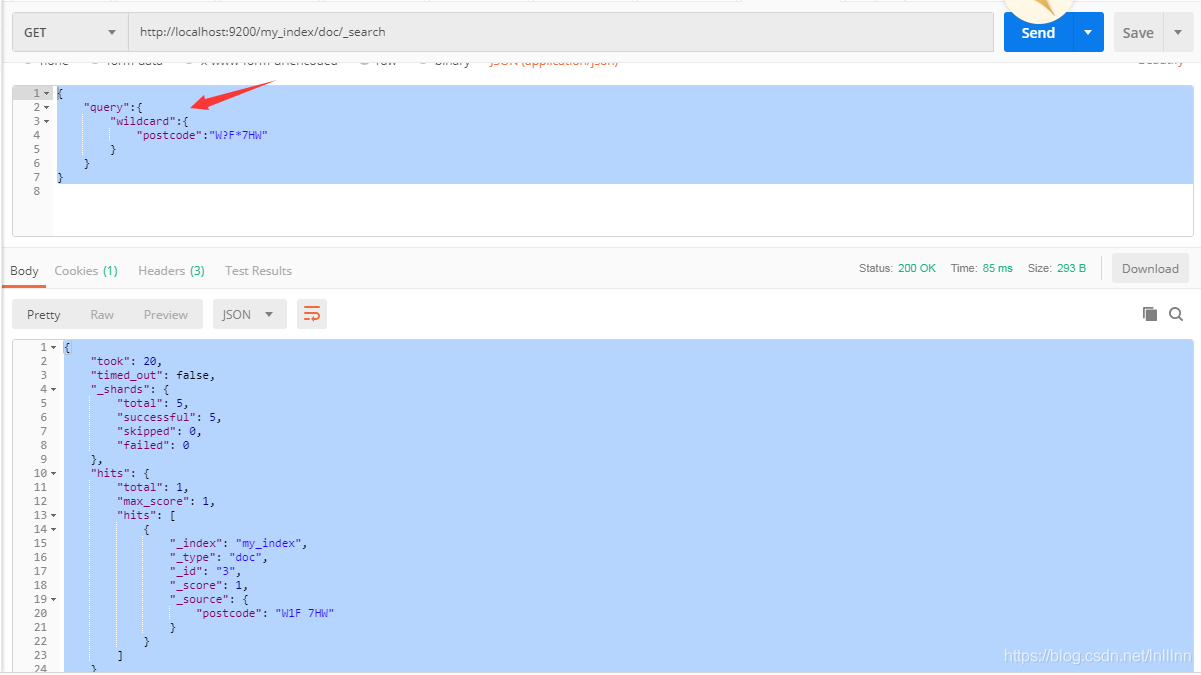
通配符查找
使用wildcard,?代表一个任意字符,*代表一个或多个字符:
也可以使用正则查询:
{
"query": {
"regexp": {
"postcode": "W[0-9].+"
}
}
}
为避免扫描所有词项,不要使用*anyword这种,和sql类似,like不要使用%anyword
另外,若查询的字段是text(非keyword),那么很有可能查询不到,比方说包含 “Quick brown fox” (快速的棕色狐狸)的 title 字段会生成词: quick 、 brown 和 fox 。
下面两个查询时查不到结果的
{ "regexp": { "title": "Qu.*" }}
{ "regexp": { "title": "quick br*" }}
输入即搜索
即搜索词还没有写完时就能得到搜索结果,如同idea等编译器的智能提示一样:
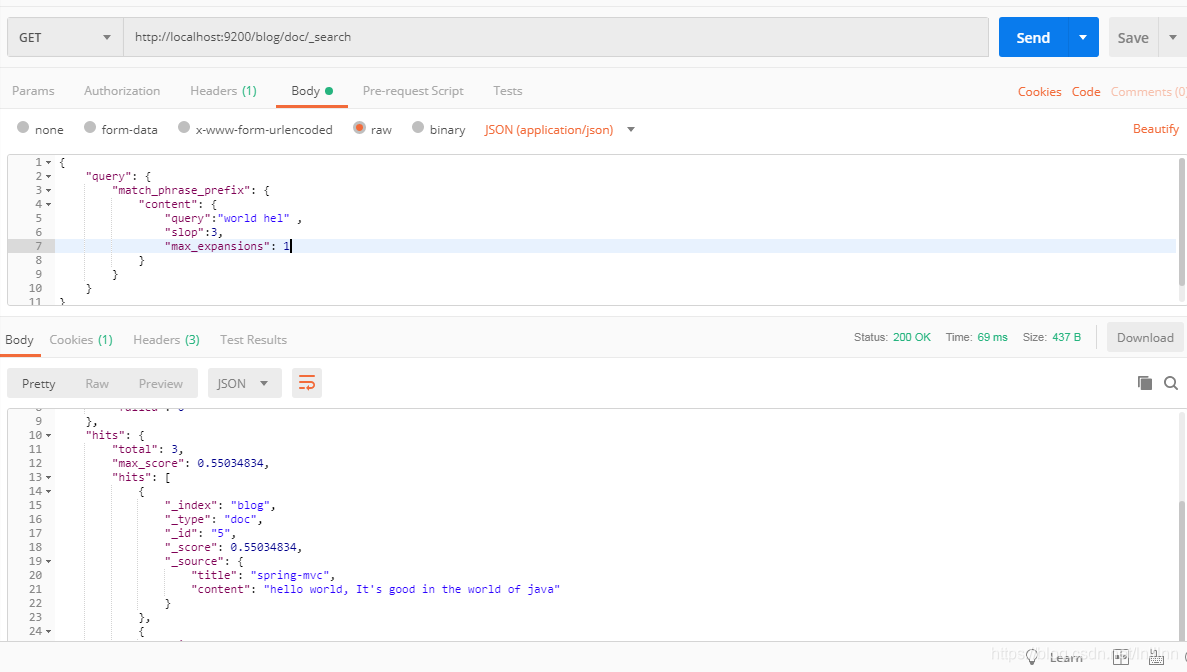 最后一个词为前缀匹配,slop忽略一定的位置关系,max_expansions限定了搜索结果数量(写1没有效果。。。)
最后一个词为前缀匹配,slop忽略一定的位置关系,max_expansions限定了搜索结果数量(写1没有效果。。。)
索引时准备好
上面的模糊搜索性能较低,可以在索引时做点手脚来提升搜索时的性能,使用边界-ngrams,即把单词固定住一边,以hello为例子,它的边界n-grams为:h he hel hell hello。这样就非常适合即使搜索了,我们先delete掉my_index索引,在put
put localhost:9200/my_index
{
"settings": {
"number_of_shards": 1,
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 5
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}
min_gram指最小窗口,max为最大,看一下分词效果:
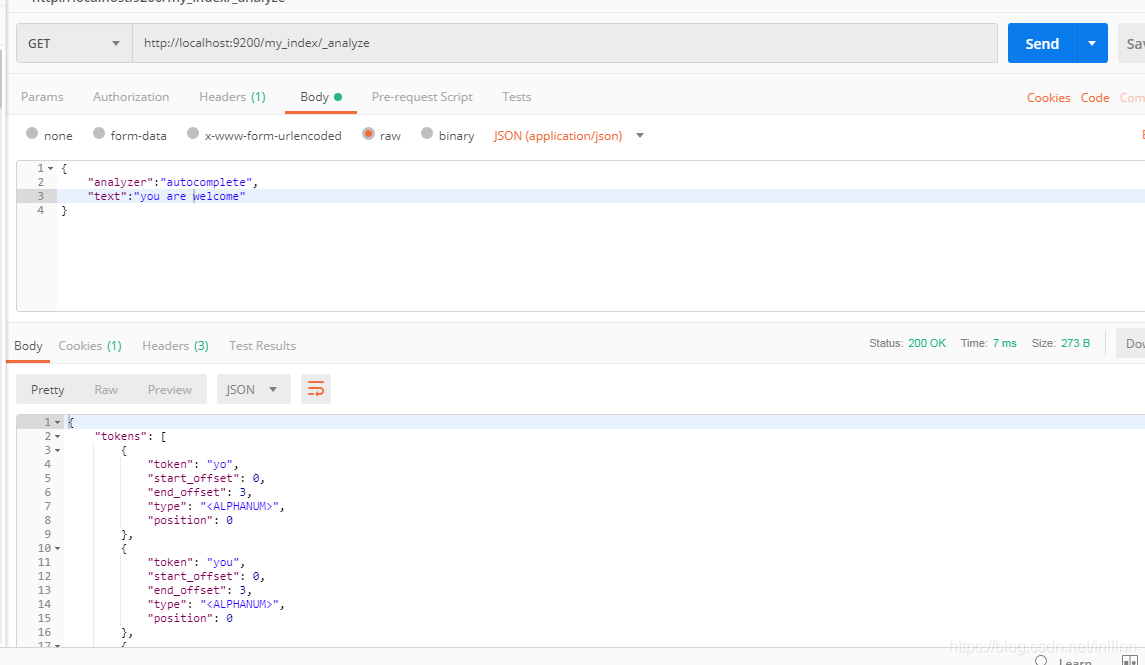
max_gram为5,welcome被分词为 we wel welc welco,看来把max_gram设置小的话是有问题的,还是把min调整为1,max调整为20吧,下一步将分析器应用到字段上:
PUT /my_index/_mapping/doc
{
"doc": {
"properties": {
"name": {
"type": "text",
"analyzer": "autocomplete"
}
}
}
}
添加测试文档:
POST /my_index/doc/_bulk
{ "index": { "_id": 1 }}
{ "name": "Brown foxes" }
{ "index": { "_id": 2 }}
{ "name": "Yellow furballs" }
查询:
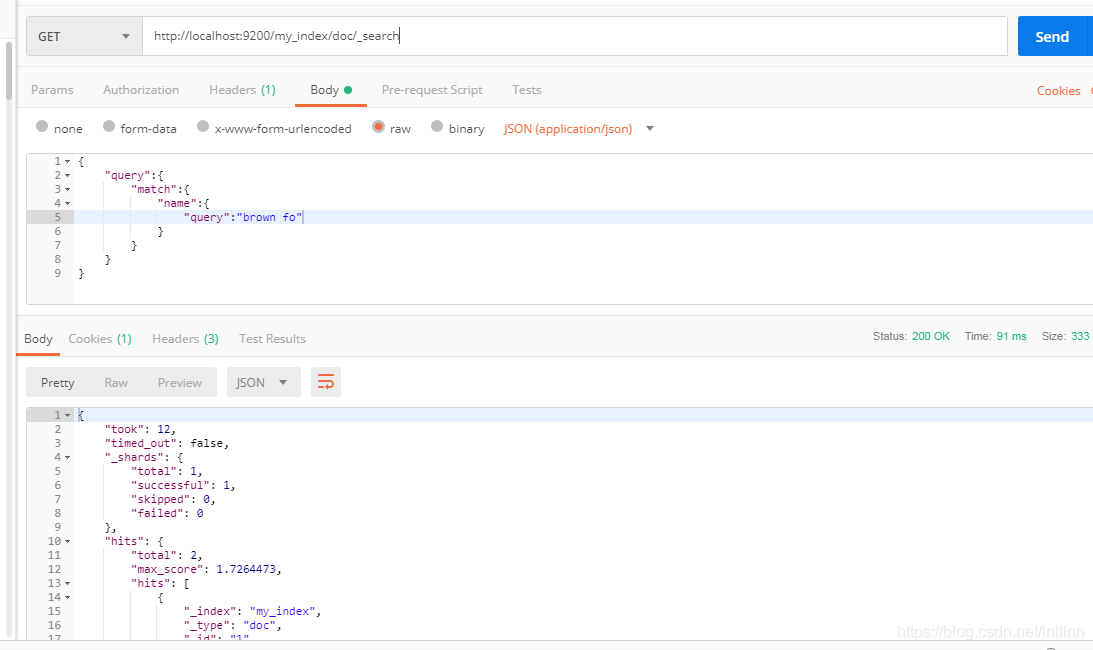
发现两个都匹配了,可以使用validate查看原因:
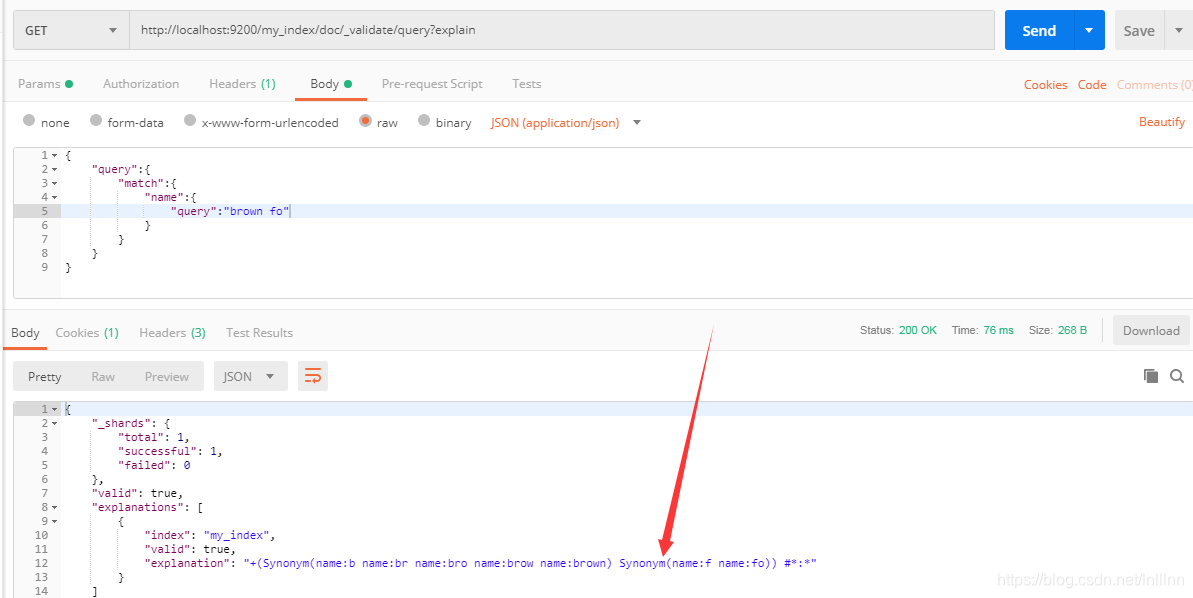
搜索词也被autocomplete分析器分析了,可以指定在搜索的时候使用标准分析器:
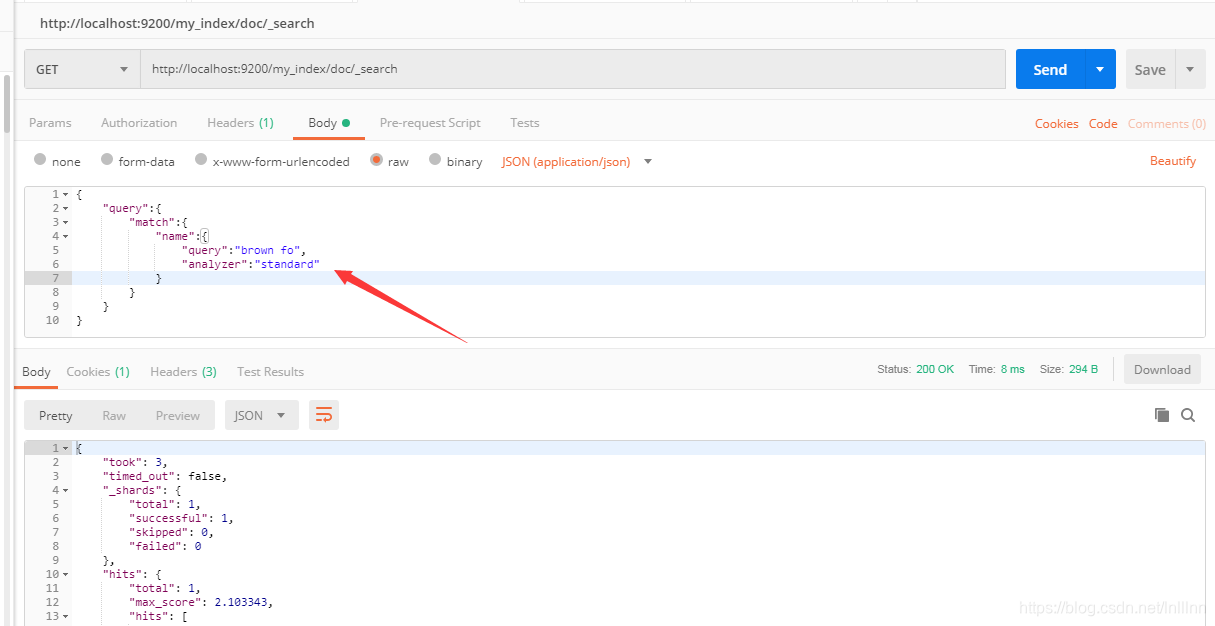
指定搜索时使用的分析器也可以在mapping中设置,设置好后在搜索时就不用指定了:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









