



在RAG项目中,我们不可能每次都要去执行切片向量化操作 这样会浪费大量时间以及资源,向量持久话把已经embdding出来的向量数据保存起来
引入numpy 利用内部的save方法 可以把向量保存在文件中 通过load读取向量模型
#将向量存入数据库
result = pipeline_se(input=inputs2)['text_embedding']
print("从向量数据库存储的向量",result)
np.save("./embedding.npy", result)
#读取存储的向量
loadEmbedding = np.load("./embedding.npy")
把向量数据库初始化到本地文件这样数据库中的数据也可以做到持久化
#连接数据库 创建向量库
client = chromadb.PersistentClient(path="./chroma_db")
vertordbcreate = client.get_or_create_collection(name="VectorDbDemo")
#获取数据库
vertorDb = client.get_collection("VectorDbDemo")
以下是整体的可运行代码
import os
import chromadb
from modelscope.models import Model
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import numpy as np
from openai import OpenAI
from dotenv import load_dotenv
import jieba
from rank_bm25 import BM25Okapi
# 加载 .env 文件
load_dotenv()
#创建方法根据权重返回混合查询结果
model_id = "iic/nlp_gte_sentence-embedding_chinese-large"
pipeline_se = pipeline(Tasks.sentence_embedding,
model=model_id,
sequence_length=512
)
inputs2 = {
"source_sentence": [
"不可以,早晨喝牛奶不科学",
"吃了海鲜后是不能再喝牛奶的,因为牛奶中含得有维生素C,如果海鲜喝牛奶一起服用会对人体造成一定的伤害",
"吃海鲜是不能同时喝牛奶吃水果,这个至少间隔6小时以上才可以。",
"吃海鲜是不可以吃柠檬的因为其中的维生素C会和海鲜中的矿物质形成砷"
]
}
#初始化BMDB库
jiebaDbList = [list(jieba.cut(i)) for i in inputs2['source_sentence']]
bmDB = BM25Okapi(jiebaDbList)
#将向量存入数据库
result = pipeline_se(input=inputs2)['text_embedding']
print("从向量数据库存储的向量",result)
np.save("./embedding.npy", result)
#读取存储的向量
loadEmbedding = np.load("./embedding.npy")
print("从向量数据库读取的向量",loadEmbedding)
#连接数据库 创建向量库
client = chromadb.PersistentClient(path="./chroma_db")
vertordbcreate = client.get_or_create_collection(name="VectorDbDemo")
#将向量存入数据库
vertordbcreate.add(
embeddings=loadEmbedding,
documents=inputs2['source_sentence'],
ids=[
f"id_{i}" for i in range(len(inputs2['source_sentence']))
]
)
#查询向量连接数据库
vertorDb = client.get_collection("VectorDbDemo")
#问题的向量化
userMeasge = "吃海鲜后可以再喝牛奶吗?"
#jieba分词
userMeasgeJieba = jieba.cut(userMeasge)
vectorQuery = pipeline_se({"source_sentence": [userMeasge]})
print("问题向量化",vectorQuery)
query_result = vertorDb.query(
query_embeddings=pipeline_se({"source_sentence": [userMeasge]})['text_embedding'][0],
n_results=2
)
#BM25检索
bm25Scores = bmDB.get_scores(list(jieba.cut(userMeasge)))
print("BM25检索结果",bm25Scores)
top_n_results = sorted(range(len(bm25Scores)), key=lambda i: bm25Scores[i], reverse=True)[:2]
for idx in top_n_results:
print(f"Document {idx}: {inputs2['source_sentence'][idx]} (Score: {bm25Scores[idx]})")
#打印查询结果
print("向量检索结果",query_result)
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
# {'role': 'system', 'content': ''},
{'role': 'user', 'content': f"{userMeasge} 根据下面的资料回答:{query_result}"}
]
)
print(completion.choices[0].message.content)
代码中模拟了项目中持久化向量 和持久化数据库操作 最后通过RAG向大模型提问
可以看到其中也使用了BM25检索
本身是想测试混合检索效果的
但是写着写着发现混合检索的局限性
想法:混合检索在 BM25 检索结束后 和向量检索结束后进行
step1: 把所有原始的切片文本进行 id(数组下标) : value(切片内容) 取出来以字典的形式存储起来
step2:在向量检索的时候,预先把向量数据库add方法内的ids设置成数组下标 这样就可以在RAG检索的时候得到所查询到的数据的下标,方便以后定位数据
step3:我们可以直接通过BM25得到检索后的下标以及分数 已知向量检索的id(下标) 以及距离可以使 1-距离 作为向量检索的分数 乘混合检索分配的比重得到最后的分数
step4;把下标 以及 最后混合计算的分数存起来 最后进行排名得到排名数据
缺陷: 在BM25中查询5条数据,在RAG中也查询5条,这两个5条数据不可能每次都完全相同;这种方式可能会出现 在BM25内部能查询到数据 但是在 向量数据库中查询不到 反之亦然 如果另一方查询不到 把其的分值归零的化 那混合查询的排名的精确性就得不到保证
如果我们不定义要查询前几条,而是都查询出来呢
都查询出来可以保证BM25 和RAG 查询的数据是相同的,可以保证查询的精确性,但是其缺点也很明显,在用户每次提问时都去进行全部数据的一个检索排列数据的处理量会特别大
所以对于混合检索我暂时没想到特别好的处理方向 以后学习到会向下补充;
2025-05-30
在讲混合索引之前进行一下知识点记录:下面防止自己忘记补充一个小知识点;用ragas进行RAG评估
#底下是评估代码,需要连接外网
# evaluate_dataset =Dataset.from_dict(evaluate_data)
# from ragas import evaluate
# os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY")
# evaluate_result = evaluate(evaluate_dataset,metrics=[
# faithfulness,
# answer_relevancy,
# context_recall,
# context_precision
# ],
# llm=langchainModel)
# panda = evaluate_result.to_pandas()
# panda.to_excel("RAGUpper.xlsx", index=False)
关于混合检索 langchain是这样封装的
from langchain.retrievers import EnsembleRetriever, ContextualCompressionRetriever
ensemble_retriever = EnsembleRetriever(retrievers=[retriever,BM25_retriever],weights=[0.5,0.5])
这个和我们上面的猜想都不相同,
假设上方代码:
retriever向量检索器设置的是检索5条
BM25_retriever检索器设置的也是5条
比如 retriever检索到的是 A,B,C,D,E
BM25_retriever检索器检索到的是 C,D,E,F,G
那么得到的最终结果就是A,B,C,D,E,F,G
如果他们都不尽相同那么最终就会是10条数据 如果都相同那么就会是5条数据 最终的到的数据量在5-10之间(包含)
那么 如果我们只想要前5条呢
像这样
ensemble_retriever.invoke({"query":questions[0],"k":2})
设置检索之后的两条,那么他是怎么得出这两条的呢
他的计算流程跟我们的上面标记为红色的想法是一样的
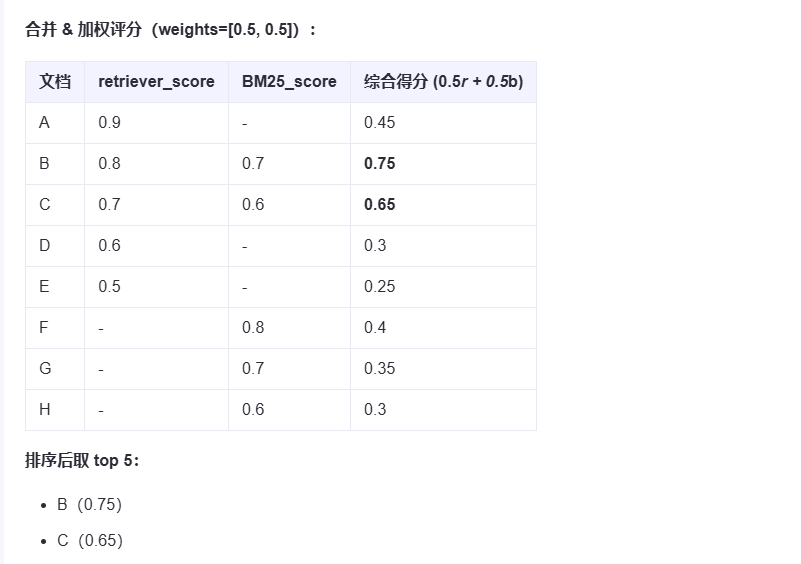
最终得出的为得分最高的 B,C
即使这样,还是会有一定的冗余;其实也还好不过公司token肯定越少越好
langchain给我们了一个压缩的方式 ContextualCompressionRetriever
代码如下
#创建混合检索问答机器
pipeline_compressor = DocumentCompressorPipeline(
transformers=[
LLMChainExtractor.from_llm(langchainModel)
]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor,
base_retriever=ensemble_retriever
)
pipeline_compressor是建立混合压缩方式的 内部可以放多个压缩方式
最后得出混合压缩的结果数据更少
这次的实验代码,感兴趣可以看一下
import os
from datasets import Dataset
from dotenv import load_dotenv
from langchain.retrievers.document_compressors import DocumentCompressorPipeline, LLMChainExtractor
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.agents import AgentType, initialize_agent
from langchain.tools import Tool
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.memory import ConversationBufferMemory
from langchain_core.output_parsers import StrOutputParser
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision
# 加载环境变量
load_dotenv()
# 初始化大模型
langchainModel = ChatOpenAI(
model="qwen-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 加载并切分文档
pdfLoader = PyPDFLoader(r"../LangChain/异地测试安排 20230424.pdf")
documents = pdfLoader.load()
testSplit = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=30)
split_documents = testSplit.split_documents(documents)
# 初始化嵌入模型并创建向量数据库
embeddings = DashScopeEmbeddings(
model="text-embedding-v3",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
retriever = Chroma.from_documents(split_documents, embeddings).as_retriever(search_kwargs={"k": 2})
#FAISS持久话到本地的代码
# vectordb.save_local(index_folder_path, index_name)
#
# # 加载索引
# vectordb = FAISS.load_local(index_folder_path, embeddings, index_name, allow_dangerous_deserialization=True)
from langchain_community.retrievers import BM25Retriever
BM25_retriever = BM25Retriever.from_documents(split_documents)
BM25_retriever.k = 2
#引入LangChain的问答链接
from langchain.chains import RetrievalQA
RetrievalQAReturn = RetrievalQA.from_chain_type(
llm=langchainModel,
chain_type="stuff",#stuff模式"stuff" 是其中一种最简单的模式:将所有检索到的文档内容“塞进”提示词中,作为上下文提供给 LLM。
retriever=retriever,
return_source_documents=True #返回文档
)
questions = [
"创业惠康的测试时间是多少",
"测试时间为2023-5-8的有哪些公司"
, "请帮我生成测试计划"
]
ground_truths = [
"2023-5-8",
"创业惠康,银海HIS.天津津微首佳软件技术有限公司,天津市宝坻区人民医院,北大医疗信息技术有限公司,吉林省中联天润科技有限公司,第一城科技"
, "文件内没有测试计划"
]
awnsers = []
contexts = []
# for question in questions:
# RetrievalQAReturnInfo = RetrievalQAReturn.invoke(question)
# print(RetrievalQAReturnInfo)
# contexts.append([(context.page_content) for context in RetrievalQAReturnInfo["source_documents"]])
# awnsers.append(RetrievalQAReturnInfo["result"])
evaluate_data = {
"question": questions,
"answer": awnsers,
"contexts": contexts,
"ground_truth": ground_truths
}
print(type(evaluate_data))
#创建混合检索机器
from langchain.retrievers import EnsembleRetriever, ContextualCompressionRetriever
ensemble_retriever = EnsembleRetriever(retrievers=[retriever,BM25_retriever],weights=[0.5,0.5])
#创建混合检索问答机器
pipeline_compressor = DocumentCompressorPipeline(
transformers=[
LLMChainExtractor.from_llm(langchainModel)
]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor,
base_retriever=ensemble_retriever
)
RetrievalQAEnsemble = RetrievalQA.from_chain_type(
llm=langchainModel,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True
)
RetrievalQAEnsembleReturn = RetrievalQAEnsemble.invoke({"query":questions[0],"k":2})
print(RetrievalQAEnsembleReturn)
print(len(RetrievalQAEnsembleReturn["source_documents"]))
#底下是评估代码,需要连接外网
# evaluate_dataset =Dataset.from_dict(evaluate_data)
# from ragas import evaluate
# os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY")
# evaluate_result = evaluate(evaluate_dataset,metrics=[
# faithfulness,
# answer_relevancy,
# context_recall,
# context_precision
# ],
# llm=langchainModel)
# panda = evaluate_result.to_pandas()
# panda.to_excel("RAGUpper.xlsx", index=False)

















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









