






 本文介绍Python中正则表达式的多种实用函数,如匹配、搜索、查找等,并讲解如何使用修饰符来增强匹配能力,还提供了多行匹配、分组及贪婪匹配的实例。
本文介绍Python中正则表达式的多种实用函数,如匹配、搜索、查找等,并讲解如何使用修饰符来增强匹配能力,还提供了多行匹配、分组及贪婪匹配的实例。
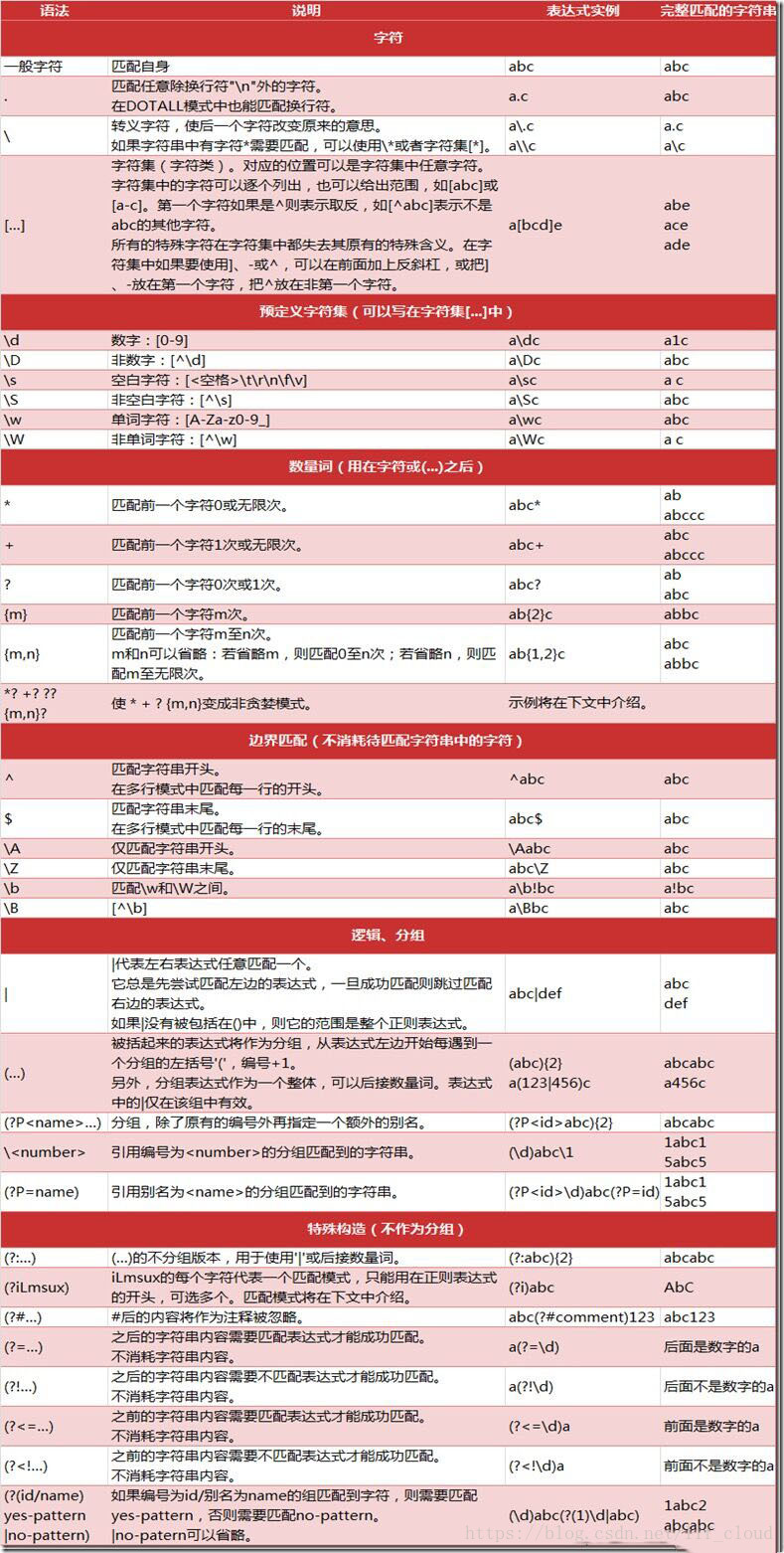
字符串查询匹配的函数:
|
函数 |
描述 |
|
re.match(reg, info) |
用于在开始位置匹配目标字符串info中符合正则表达式reg的字符,匹配成功会返回一个match对象,匹配不成功返回None |
|
re.search(reg, info) |
扫描整个字符串info,使用正则表达式reg进行匹配,匹配成功返回匹配的第一个match对象,匹配不成功返回None |
|
re.findall(reg, info) |
扫描整个字符串info,将符合正则表达式reg的字符全部提取出来存放在列表中返回 |
|
re.fullmatch(reg, info) |
扫描整个字符串,如果整个字符串都包含在正则表达式表示的范围中,返回整个字符串,否则返回None |
|
re.finditer(reg, info) |
扫描整个字符串,将匹配到的字符保存在一个可以遍历的列表中 |
代码示例:
import re
my_str = "hello world"
rg1 = r"l"
# 1. match函数
# 从开头位置匹配表达式,如果第一个字符匹配失败~结束
# 匹配一次,即使目标字符串中出现了多个正确的字符
# 成功返回一个match对象,失败返回None
print('match函数')
print(re.match(rg1, my_str)) # 首字母不为l所以返回None
print()
# 2. search函数
# 从整个目标字符串中查询符合表达式的字符
# 匹配一次
# 成功返回一个match对象,失败返回None
print('search函数')
print(re.search(rg1, my_str))
print(re.search(rg1, my_str).group())
print()
# 3. findall函数
# 从整个目标字符串中,查询符合表达式的字符;全部添加到一个列表中返回
# 返回一个结果列表
print('findall函数')
print(re.findall(rg1, my_str))
print()
# 4. finditer函数
# 和第三个函数一模一样,唯一的区别
# 返回的不是列表:迭代器
print('finditer函数')
res4 = re.finditer(rg1, my_str)
print(res4)
for x in res4:
print(x)
print(x.group())
# 运行结果:
F:\win10software\Python36\python36.exe
match函数
None
search函数
<_sre.SRE_Match object; span=(2, 3), match='l'>
l
findall函数
['l', 'l', 'l']
finditer函数
<callable_iterator object at 0x000001DFB5ECB8D0>
<_sre.SRE_Match object; span=(2, 3), match='l'>
l
<_sre.SRE_Match object; span=(3, 4), match='l'>
l
<_sre.SRE_Match object; span=(9, 10), match='l'>
l
Process finished with exit code 0
修饰符:
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | IGNORECASE 忽略大小写区别 |
| re.L | LOCAL 字符集本地化。这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符/w ,在英文环境下,它代表[a-zA-Z0-9] ,即所以英文字符和数字。如果在一个法语环境下使用,缺省设置下,不能匹配 "é" 或 "ç" 。 加上这 L 选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。 |
| re.M | MULTILINE 多行匹配。在这个模式下 ’^’( 代表字符串开头 ) 和 ’$’( 代表字符串结尾 ) 将能够匹配多行的情况,成为行首和行尾标记。 |
| re.S | DOTALL ‘.’ 号将匹配所有的字符。缺省情况下 ’.’ 匹配除换行符 ’/n’ 外的所有字符,使用这一选项以后, ’.’ 就能匹配包括 ’/n’ 的任何字符了。 |
| re.U | Unicode 根据Unicode字符集解析字符,这个标志影响 /w , /W , /b , /B , /d , /D , /s 和 /S... |
| re.X | VERBOSE这个选项忽略规则表达式中的空白和注释,并允许使用 ’#’ 来引导一个注释。这样可以让你把规则写得更美观些。 |
字符串拆分替换的函数
re.split(reg, string):使用指定的正则表达式reg匹配的字符,将字符串string拆分成一个字符串列表,如:re.split(r"\s+", info),表示使用一个或者多个空白字符对字符串info进行拆分,并返回一个拆分后的字符串列表。
re.sub(reg, repl, string):使用指定的字符串repl来替换目标字符串string中匹配正则表达式reg的字。
多行匹配
正则表达式re.match()默认匹配第一行,匹配多行加re.DOTALL参数即可。
re.match('(.*)',response_text,re.DOTALL)
正则表达式re.findall()中的re.M参数表示将字符串视为多行,从而^匹配每一行的行首,$匹配每一行的行尾。
Python示例,这个程序是匹配冒号加一个空格后的数字串,中间有换行符\n所以用多行匹配re.M。
#!/usr/bin/python3
import re
line = "IF_MIB::=Counter32: 12345\nIF_MIB::=Counter32: 1234556";
result = re.findall( r'(?<=\:\s)\d+$', line, re.M)
if result:
print (result)
else:
print ("Nothing found!!")
# 运行结果
['12345', '1234556']
分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码。
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'
>>> m.groups()
('010', '12345')
>>>
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
groups()方法可以提取所有匹配到的子串。
a = "<a href='/a/1.html'></a>"
webpage_rex = re.compile('<a[^>]+href=["\'](.*?)["\']', re.IGNORECASE)
webpage_rex.findall(a)
>>> ['/a/1.html']
webpage_rex = re.compile('<a[^>]+href=["\'].*?["\']', re.IGNORECASE)
webpage_rex.findall(a)
>>> ["<a href='/a/1.html'"]
贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')
Python中re匹配过程
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
-
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
-
用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re
# 编译:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 使用:
>>> re_telephone.match('010-12345').groups()
('010', '12345')
>>> re_telephone.match('010-8086').groups()
('010', '8086')

















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









