



 本文介绍了在多分类问题中,如何利用softmax函数和反向传播算法计算误差并更新权重,涉及损失函数、学习率选择以及优化器对加快网络收敛的重要性。详细讲解了从输出层到隐藏层和输入层的权重更新过程,以及迭代训练的完整流程。
本文介绍了在多分类问题中,如何利用softmax函数和反向传播算法计算误差并更新权重,涉及损失函数、学习率选择以及优化器对加快网络收敛的重要性。详细讲解了从输出层到隐藏层和输入层的权重更新过程,以及迭代训练的完整流程。
误差的计算
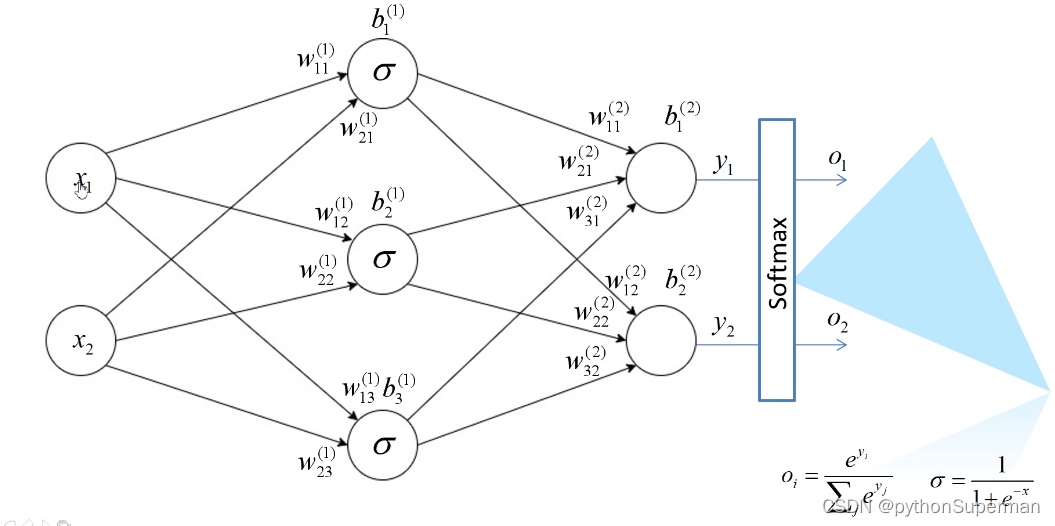
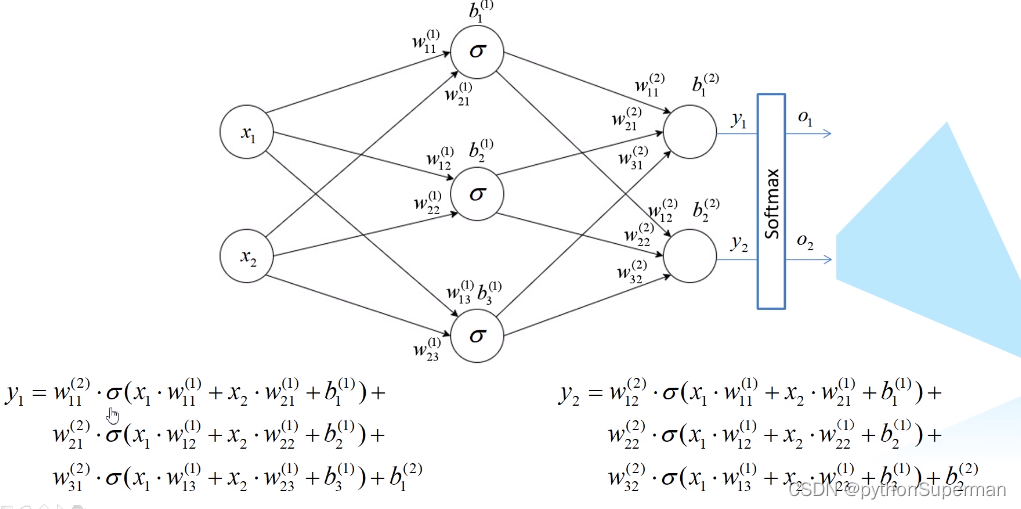
softmax
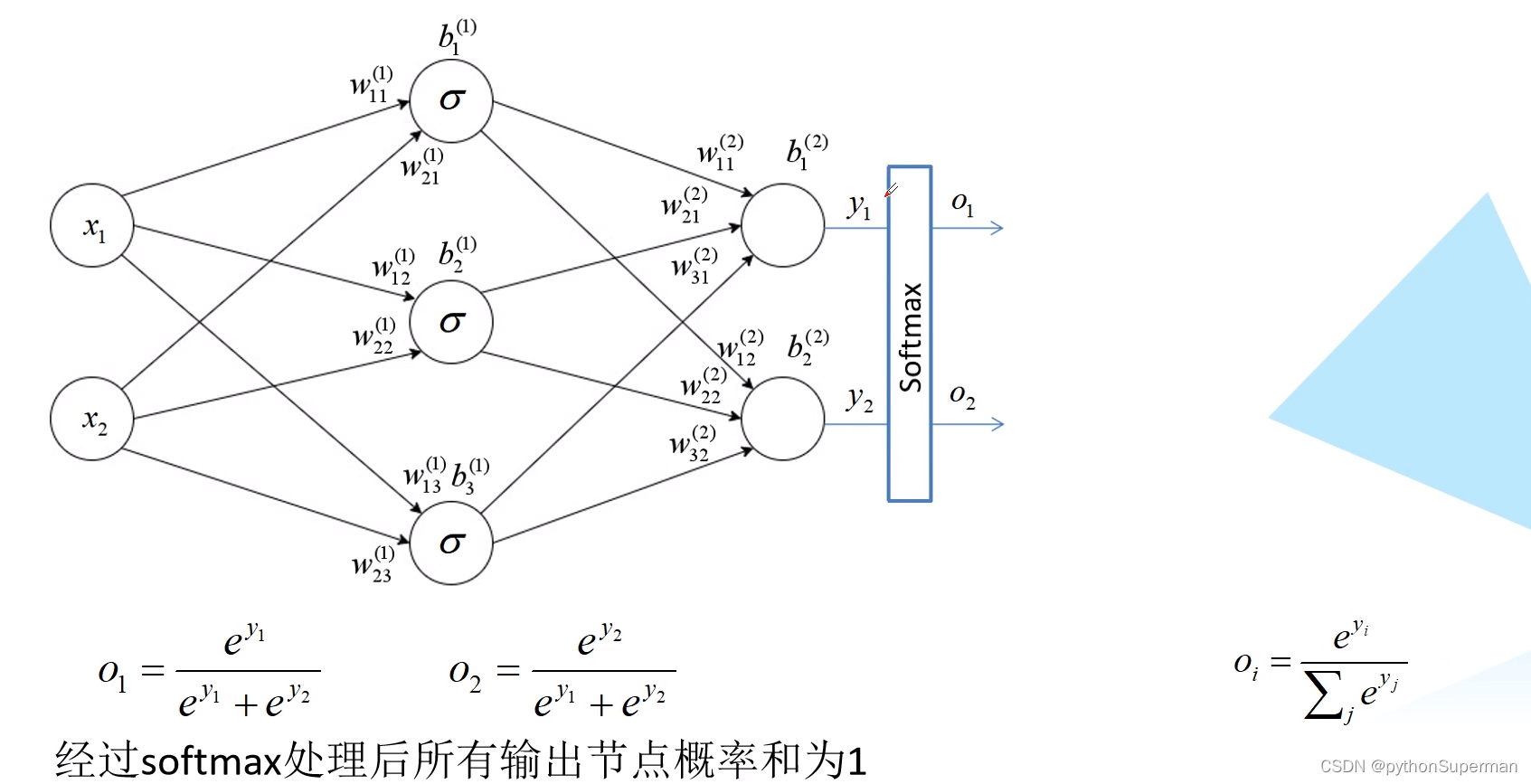
经过softmax处理后所有输出节点概率和为1
损失(激活函数)

多分类问题:输出只可能归于某一个类别,不可能同时归于多个类别。
误差的反向传播
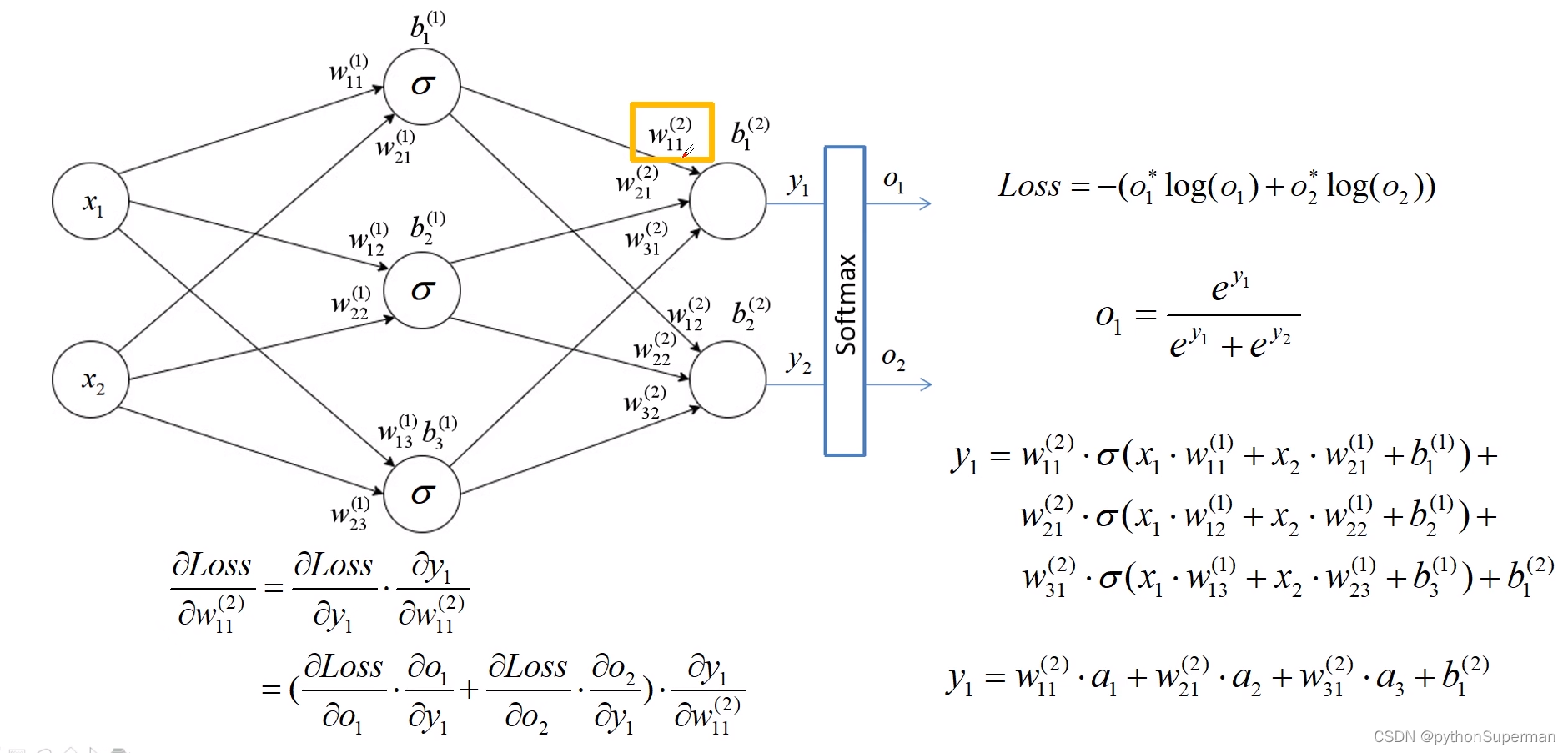
求w的误差梯度
权值的更新
首先是更新输出层和隐藏层之间的权重。更新权重,我们首先需要知道损失梯度,损失梯度实际上是损失根据所需要的更新的权重求偏导,而要求解这个偏导,我们要通过链式法则来求解。成功求解损失梯度后,要通过梯度下降的方法来更新我们的权重。这里的损失梯度前面的系数,我们称之为学习率,直观意义去理解实际上就是步长。
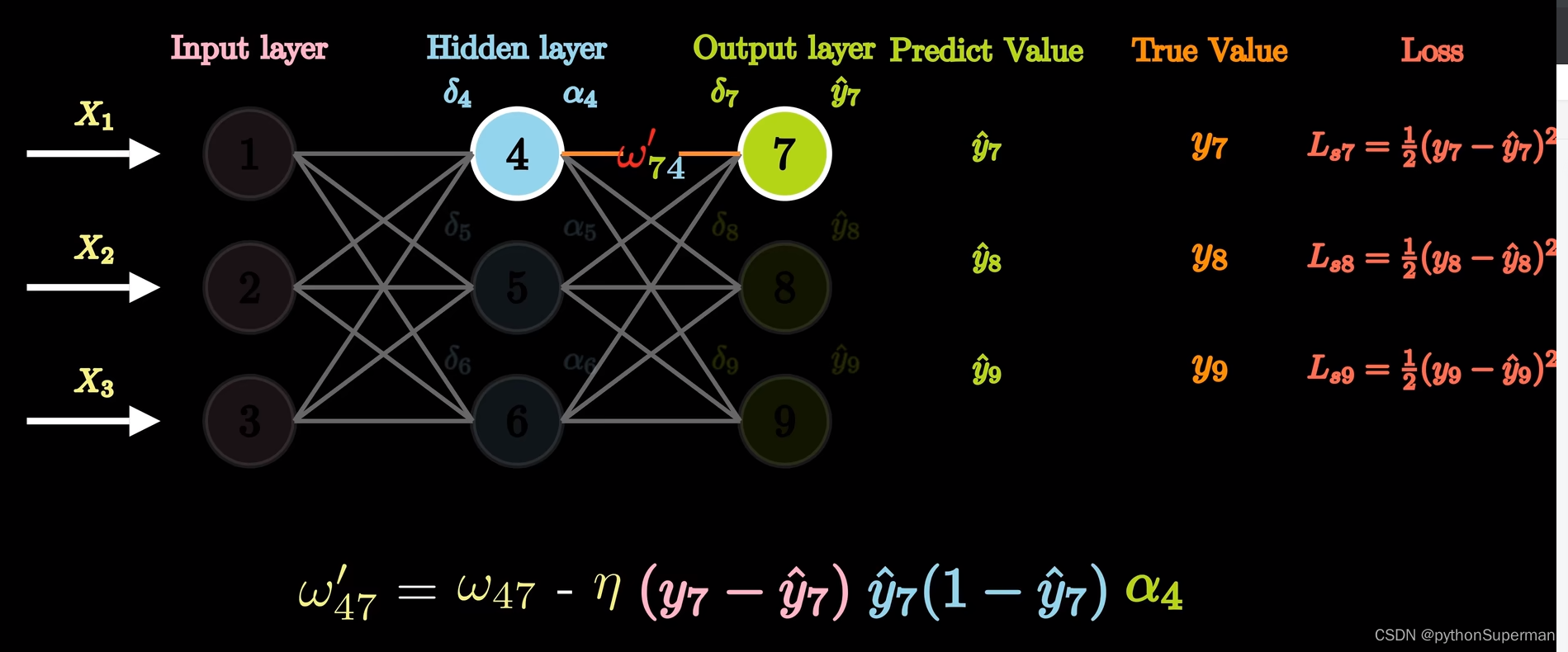
这个参数是我们人为调整的,但是学习率不宜过大,也不易过小。过大可能会导致损失无法收敛,过小可能会导致损失收敛的速度过慢,或者会陷入局部最优解的问题中。因此学习率我们不能随意取值,需要通过后续不断地迭代,来获取最优学习率。
接着我们需要进一步更新我们的隐藏层和输入层之间的权重,对于这里的损失梯度,我们同样是通过链式法则得到损失梯度的表达式,过程基本与前面保持一致。但是这里有两个注意点,第一,这里通过链式法则最后得到的损失梯度的结果会用到我们前面更新过的权重,所以说反向传播的顺序是不可逆的。第二,对与隐藏层和输入层之间权重的更新是多个损失项更新的叠加。通过上述的推到过程,我们可以求得我们所需的损失梯度,得到损失梯度后,通过梯度下降,我们可以得到隐藏层和输入层之间更新后的权重。
至此,我们已经完成了通过误差的反向传播实现了一次完整的权重的更新。后面的过程就是在正向传播更新输出,然后再反向更新权重,循环迭代,直到损失收敛或者是达到设定的迭代次数,一次神经网络的训练完成。
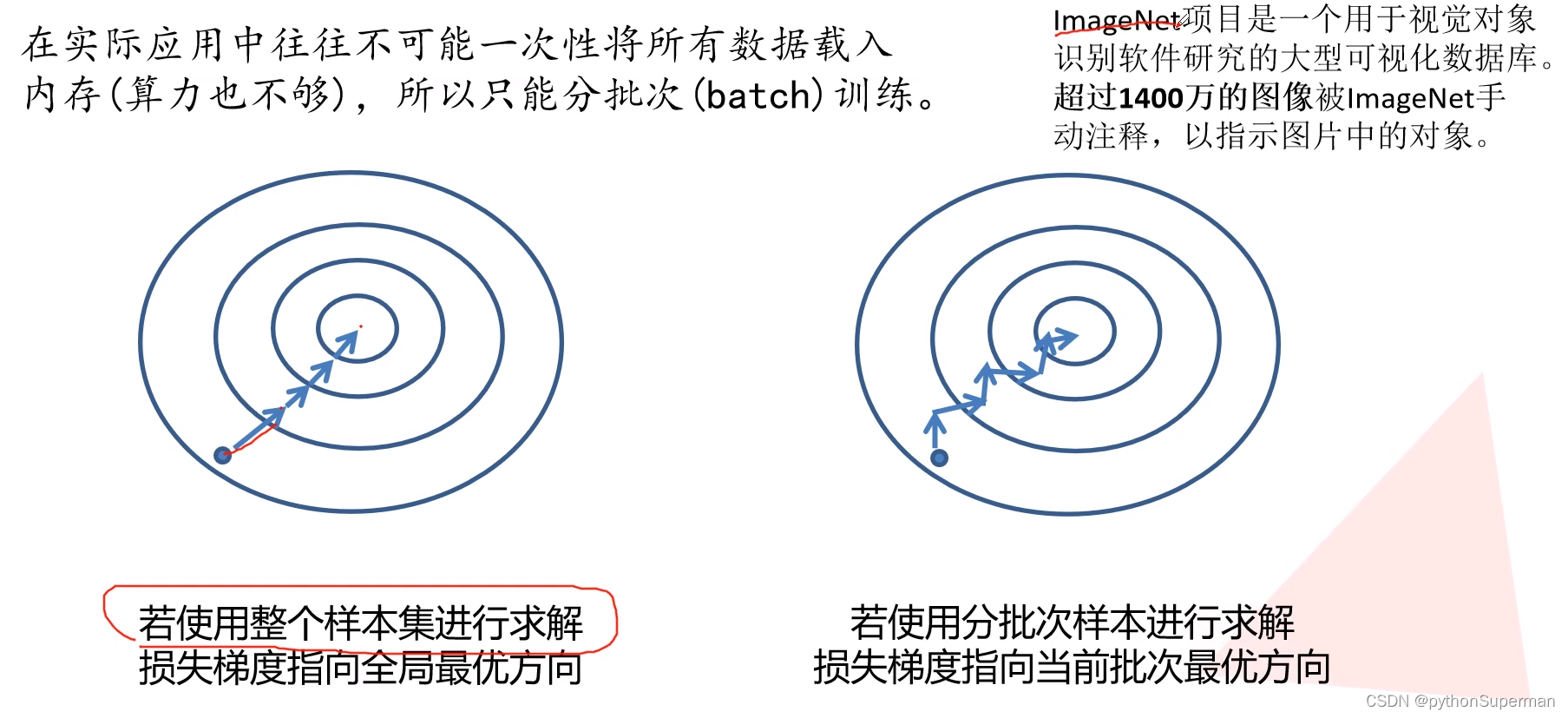
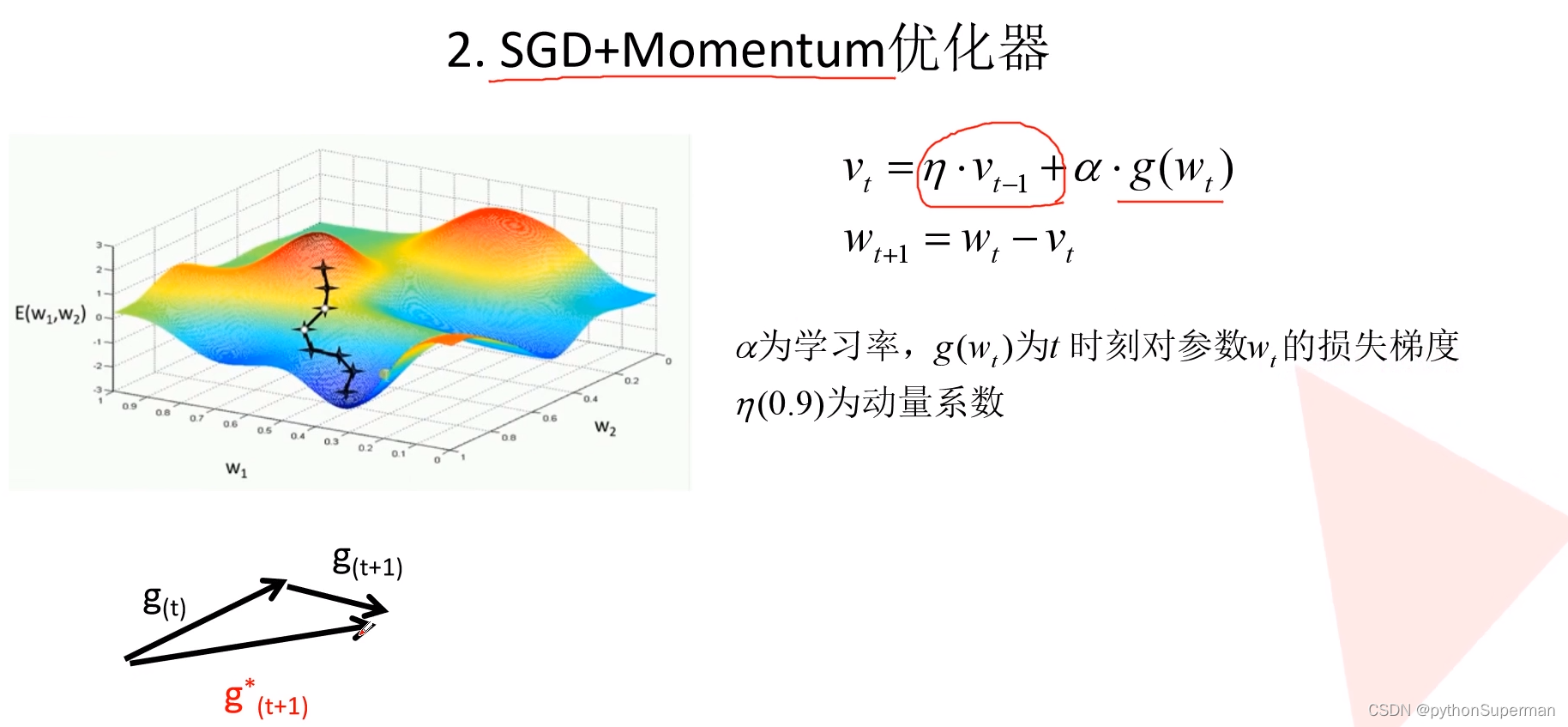
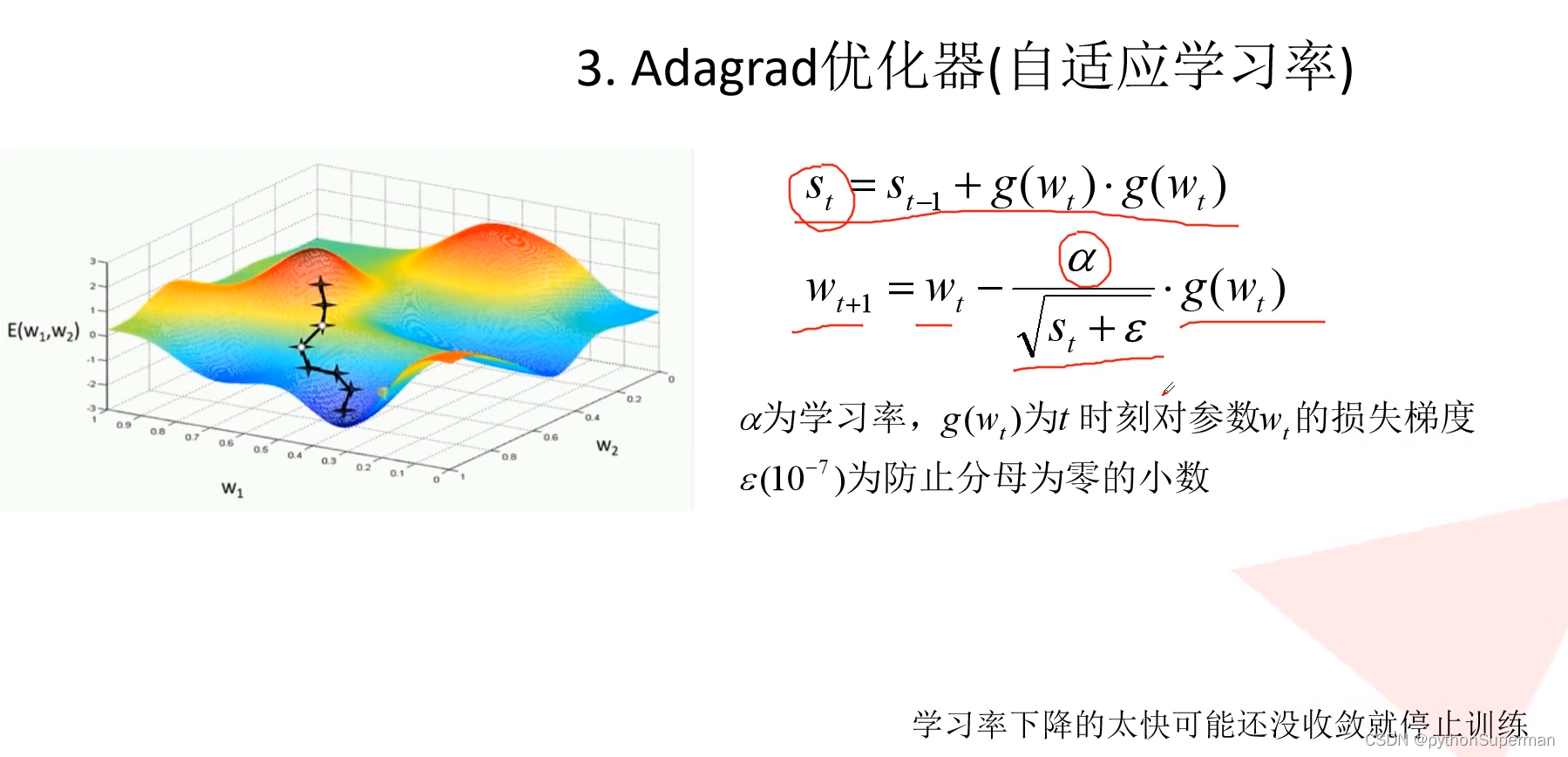
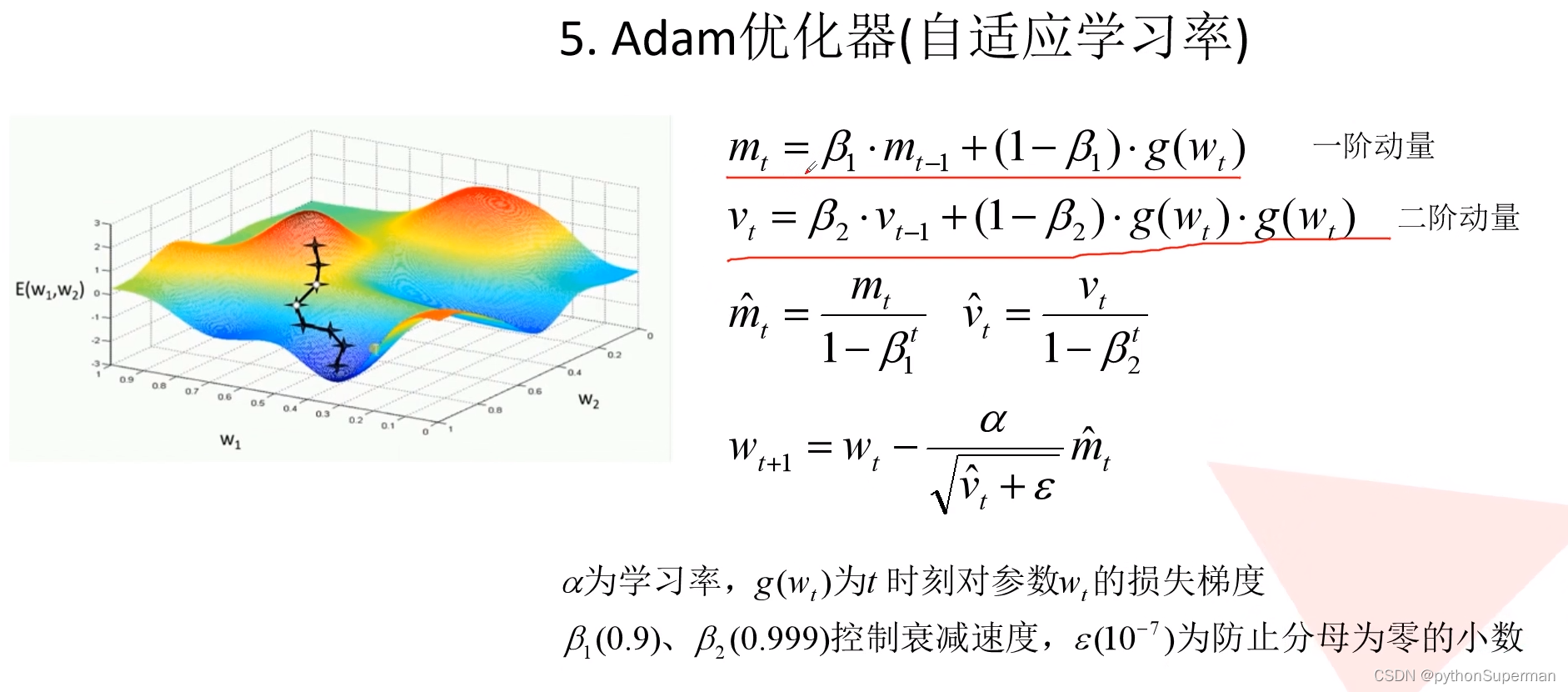
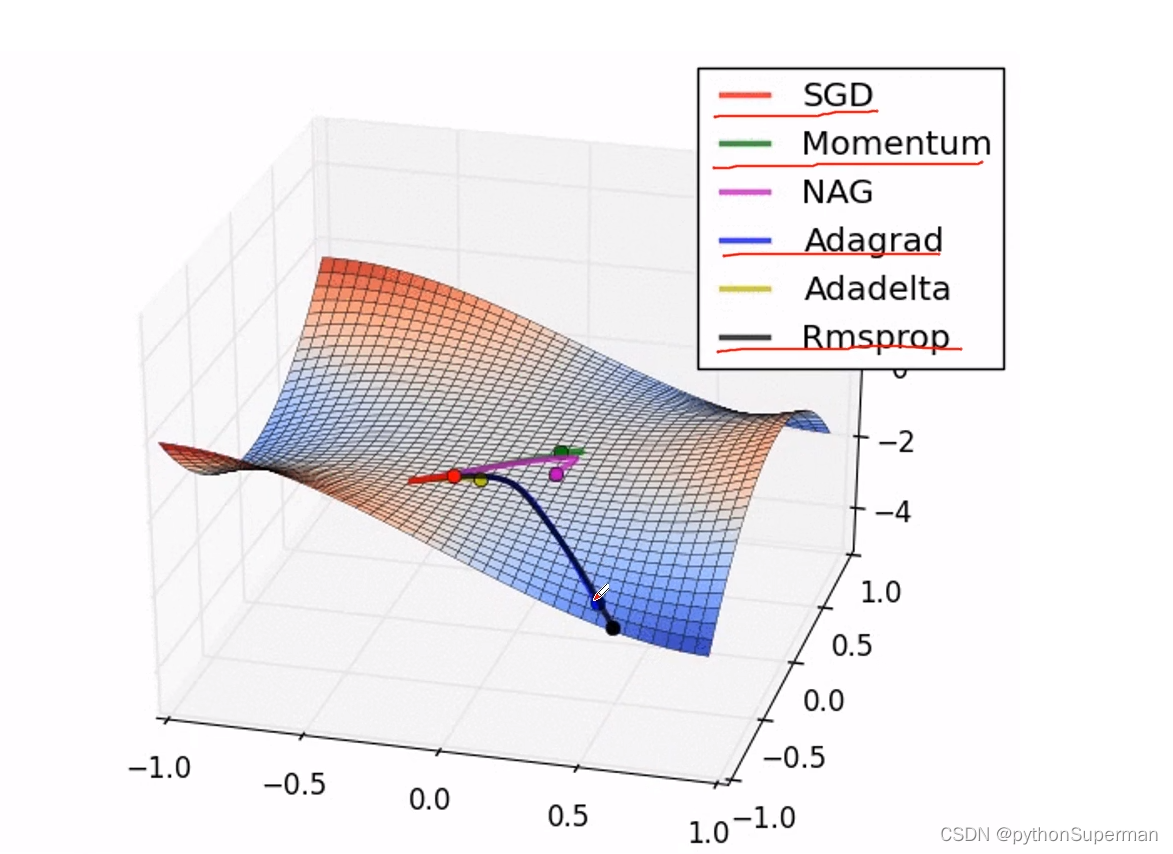
优化器
使网络更快地得到收敛



















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









