







利用人工智能实现创意辉煌:构建交互式媒体应用程序的黑客马拉松指南
大家好,未来的黑客马拉松获胜者!在本教程中,我很高兴向你们展示如何构建一款必定令人眼花缭乱的 AI 驱动应用程序。我们将使用 Clarifai 进行文本转语音、使用 DALL·E API 进行图像生成,以及可能的 GPT-4 Turbo。本指南是您在有凝聚力的应用程序中理解和利用这些技术的路线图。
人工智能关键技术简介
使用 Clarifai 进行文本转语音
- 功能:将文本转换为口头语言。
- 主要特点:提供多种声音和语言,非常适合创建动态且易于访问的应用程序。
- 实际应用:有助于为视障人士创建语音助手、教育工具和内容。
使用 DALL·E API 生成图像
- 功能:利用人工智能根据文本描述创建图像。
- 主要特点:能够根据复杂的描述生成详细的图像。
- 实际应用:非常适合图形设计、创意艺术和内容创作。
- 进一步阅读:DALL·E 图像生成 API。
可选:通过 Clarifai 进行 GPT-4 Turbo
- 其作用:用于文本理解和生成的高级模型。
- 主要特点:对话和内容创作高度复杂。
- 实际应用:非常适合聊天机器人、内容生成和复杂的数据解释。
构建 Showcase 应用程序:交互式媒体创建器
概念概述
我们正在制作一款应用,让用户可以输入描述、生成漫画、根据图片创作故事并讲述这个故事。这是一种完全由人工智能驱动的讲故事体验!
开发步骤
设置你的环境
制作 Streamlit 界面
- UI 设计:使用 Streamlit 创建一个引人入胜的 UI,包括输入区域、生成按钮和显示结果的面板。
集成 DALL·E 进行图像生成
- 功能:编写一个
generate_image函数来使用 DALL·E 3 API 来创建图像。 - 显示:在 Streamlit 应用程序中动态显示这些图像。
实现文本转语音
- 音频转换:使用 Clarifai 的 API 将文本故事转换为可听的语音。
- 播放功能:在应用程序中嵌入音频播放器。
通过图像创作故事
- 叙事发展:可选择使用 GPT-4 来分析图像和编写故事。
- 文本显示和转换:显示文本并将其转换为语音。
交互式媒体应用程序代码分解:友好演练
好吧,让我们仔细看看互动媒体应用程序的工作原理。我将以简单、友好的方式向您介绍代码,解释每个部分的作用以及如何将它们组合在一起以创建这个很酷的应用程序。
设置交互式媒体应用程序:入门
在我们深入编写交互式媒体应用程序的有趣部分之前,我们需要遵循一些重要的设置步骤。这包括获取一些访问密钥和安装必要的软件包。别担心,我会指导您完成每个步骤!
步骤 1:获取访问令牌
Clarifai 个人访问令牌
- 访问 Clarifai:前往Clarifai 的安全设置页面。
- 获取您的令牌:在这里,您将找到您的个人访问令牌。这就像一个特殊密码,可让您的应用与 Clarifai 的服务对话。复制此令牌。
OpenAI API 密钥
- 前往 OpenAI:访问 OpenAI 网站并登录您的帐户。
- 检索您的密钥:找到列出您的 API 密钥的位置。此密钥允许您的应用与 OpenAI 强大的 AI 模型进行交互。
步骤 1:设置虚拟环境
在开始项目之前,创建虚拟环境非常重要。这可确保您的项目有一个独立的空间来管理依赖项,从而防止不同项目之间发生冲突。
-
导航到您的项目目录:
- 使用您的终端或命令提示符转到您的项目文件夹。
-
创建虚拟环境:
-
运行命令:
python -m venv env -
这将在您的项目目录中创建一个名为的新文件夹
env,其中包含虚拟环境。
-
-
激活虚拟环境:
- 对于 Windows,运行:
.\env\Scripts\activate - 对于 macOS/Linux,运行:
source env/bin/activate - 您的命令提示符现在应该显示虚拟环境的名称,表明它处于活动状态。
- 对于 Windows,运行:
第 2 步:设置环境文件
现在您有了密钥,您需要将它们安全地存储在您的项目中。
-
创建
.env文件:在您的项目文件夹中,创建一个新文件并将其命名为.env。 -
添加密钥:打开此文件并添加您的 Clarifai 和 OpenAI 密钥,如下所示:
CLARIFAI_PAT=Your_Clarifai_Personal_Access_Token OPEN_AI=Your_OpenAI_API_Key用您复制的实际键替换
Your_Clarifai_Personal_Access_Token和。Your_OpenAI_API_Key
步骤3:安装必要的软件包
最后,您需要安装几个 Python 包。
-
安装 Clarifai:此包让您的 Python 代码与 Clarifai API 交互。
pip install clarifai -
安装 python-dotenv:此包将帮助您的 Python 代码读取
.env您存储 API 密钥的文件。pip install python-dotenv -
安装streamlit:安装streamlit以更快地创建我们的应用程序。
pip install streamlit
准备编码!
完成这些步骤后,您就可以开始构建应用程序了。您已安全存储了访问令牌并安装了必要的软件包。接下来,我将引导您完成创建交互式媒体应用程序的代码。让我们开始编码吧!🚀👩💻👨💻
从基础开始:导入库
import streamlit as st
from clarifai.client.model import Model
import base64
from dotenv import load_dotenv
from PIL import Image
from io import BytesIO
load_dotenv()
import os此块就像是在开始构建某件事物之前收集所需的所有工具。以下是每个工具的作用:
- streamlit (st):将其视为我们应用的画布。我们将在此绘制用户界面。
- clarifai.client.model:这就像是 Clarifai 宝箱的钥匙,让我们可以访问他们酷炫的 AI 模型。
- base64:有点像翻译器,将图像转换成计算机喜欢使用的格式。
- dotenv 和 os:这两者协同工作以确保我们的密钥(API 密钥)安全可靠。
- PIL(Python 图像库)和 BytesIO:这些是我们的图像向导,帮助我们处理和操作图片。
保守秘密:环境变量
clarifai_pat = os.getenv("CLARIFAI_PAT")
openai_api_key = os.getenv("OPEN_AI")在这里,我们正在检索与 Clarifai 和 OpenAI 服务通信所需的密钥。这就像获得进入专属俱乐部的特殊密码一样。
图像制作的魔力:generate_image
def generate_image(user_description, api_key):
prompt = f"You are a professional comic artist. Based on the below user's description and content, create a proper story comic: {user_description}"
inference_params = dict(quality="standard", size="1024x1024")
model_prediction = Model(
f"https://clarifai.com/openai/dall-e/models/dall-e-3?api_key={api_key}"
).predict_by_bytes(
prompt.encode(), input_type="text", inference_params=inference_params
)
output_base64 = model_prediction.outputs[0].data.image.base64
with open("generated_image.png", "wb") as f:
f.write(output_base64)
return "generated_image.png"在这个函数中,我们根据用户的描述来创建图像。这就像告诉艺术家(在本例中为 DALL-E 模型)要画什么,然后艺术家为我们绘制出一幅美丽的图像。
理解图片:understand_image
def understand_image(base64_image, api_key):
prompt = "Analyze the content of this image and write a creative, engaging story that brings the scene to life. Describe the characters, setting, and actions in a way that would captivate a young audience:"
inference_params = dict(temperature=0.2, image_base64=base64_image, api_key=api_key)
model_prediction = Model(
"https://clarifai.com/openai/chat-completion/models/gpt-4-vision"
).predict_by_bytes(
prompt.encode(), input_type="text", inference_params=inference_params
)
return model_prediction.outputs[0].data.text.raw
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")获得图像后,此功能开始发挥作用。它会查看图片并向我们讲述一个故事。我们在这里使用另一个 AI 模型将图像转化为创意故事。
讲故事:text_to_speech
def text_to_speech(input_text, api_key):
inference_params = dict(voice="alloy", speed=1.0, api_key=api_key)
model_prediction = Model(
"https://clarifai.com/openai/tts/models/openai-tts-1"
).predict_by_bytes(
input_text.encode(), input_type="text", inference_params=inference_params
)
audio_base64 = model_prediction.outputs[0].data.audio.base64
return audio_base64现在,我们将人工智能模型为我们编写的故事转化为语音。这就像将书变成有声读物,这样您就可以听故事,而不必阅读。
让一切栩栩如生:main
def main():
st.set_page_config(page_title="Interactive Media Creator", layout="wide")
st.title("Interactive Media Creator")
with st.sidebar:
st.header("Controls")
image_description = st.text_area("Description for Image Generation", height=100)
generate_image_btn = st.button("Generate Image")
col1, col2 = st.columns(2)
with col1:
st.header("Comic Art")
if generate_image_btn and image_description:
with st.spinner("Generating image..."):
image_path = generate_image(image_description, clarifai_pat)
if image_path:
st.image(
image_path,
caption="Generated Comic Image",
use_column_width=True,
)
st.success("Image generated!")
else:
st.error("Failed to generate image.")
with col2:
st.header("Story")
if generate_image_btn and image_description:
with st.spinner("Creating a story..."):
base64_image = encode_image(image_path)
understood_text = understand_image(base64_image, openai_api_key)
audio_base64 = text_to_speech(understood_text, openai_api_key)
st.audio(audio_base64, format="audio/mp3")
st.success("Audio generated from image understanding!")这是我们构建应用界面并将所有内容整合在一起的地方。我们设置了一个供用户输入描述的空间、一个让魔法发生的按钮以及显示生成的图像和故事的区域。
掌控局势
if __name__ == "__main__":
main()最后,这小段代码是一切的开始。它就像“营业中”的标志,让一切运转起来。
将代码保存在 main.py 中并运行它
streamlit run main.py抢先一睹应用程序
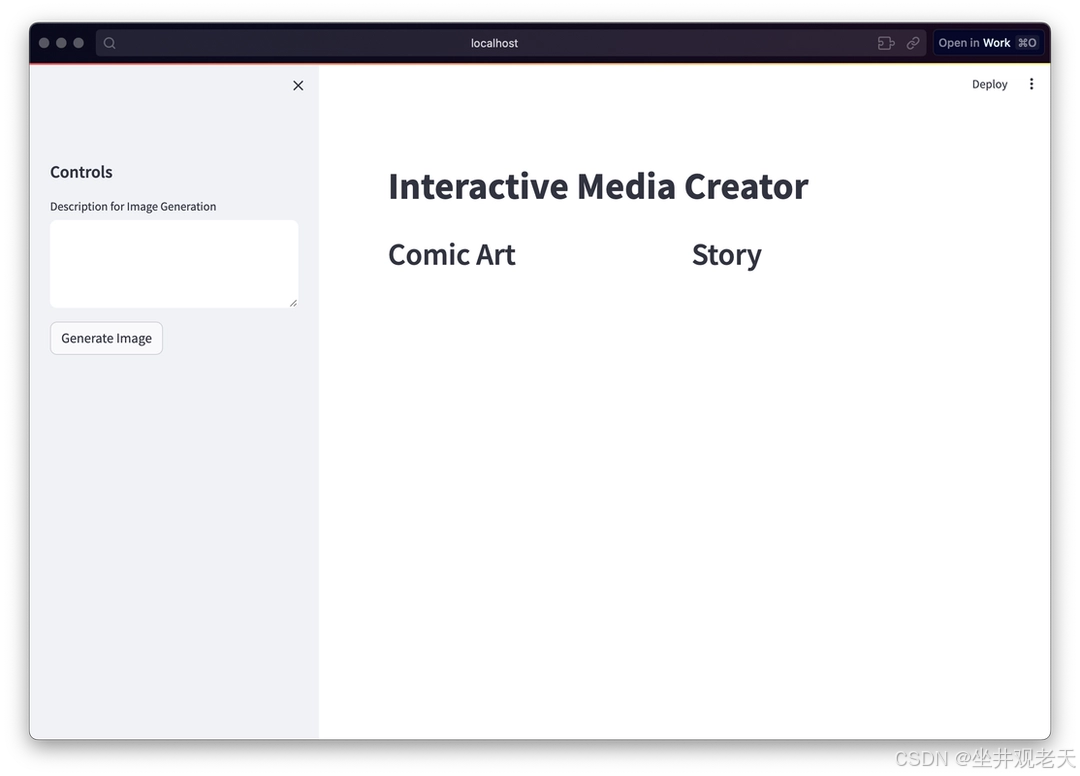
主页
图像的生成
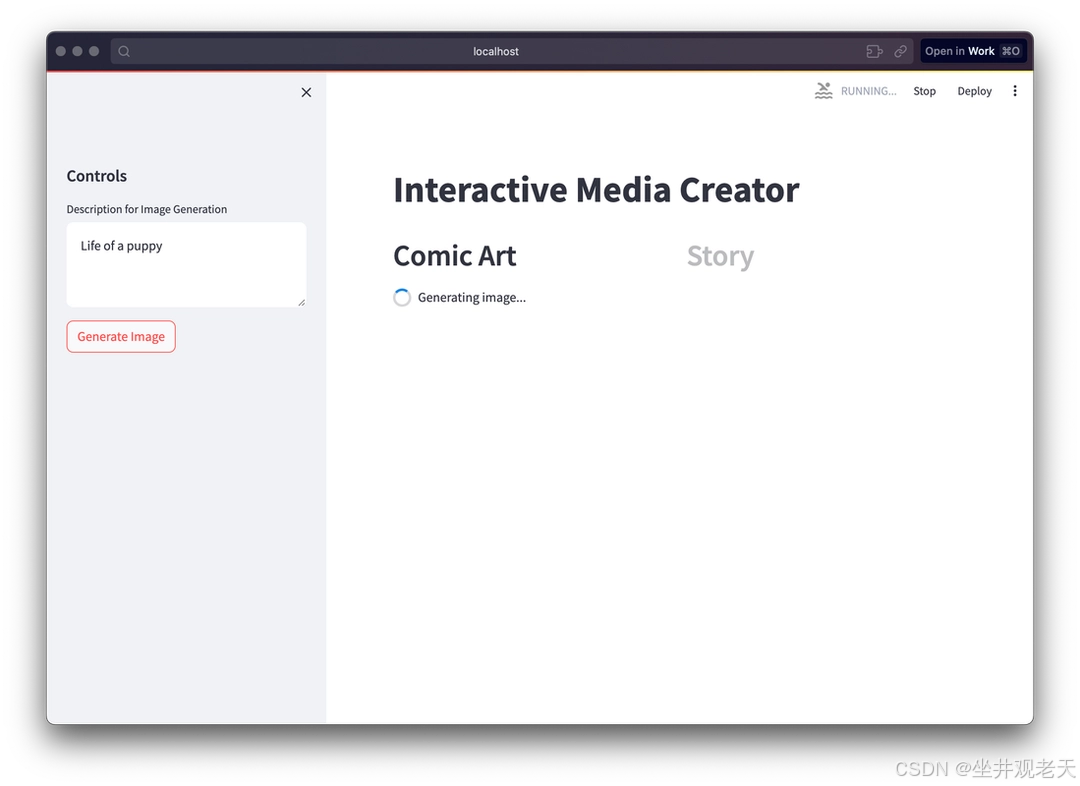
生成图像
图像和故事生成
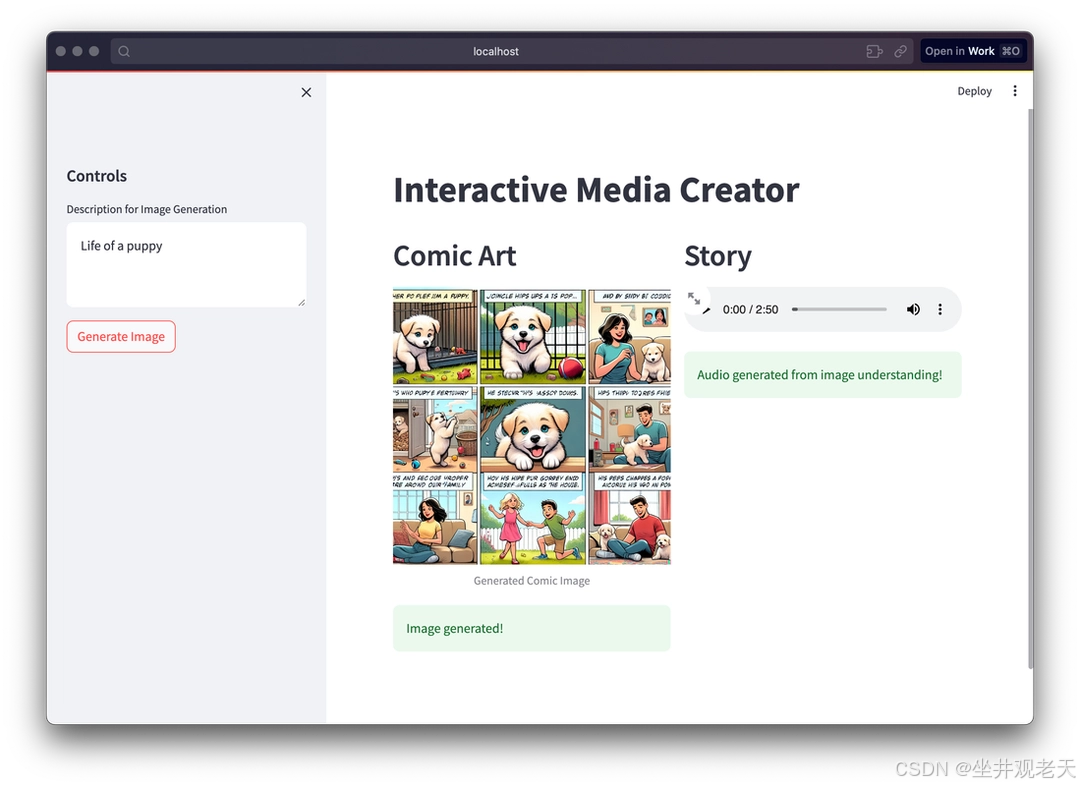
图像生成成功
就这样!我们一步步开发出一款应用,可以将描述转化为图像,将图像转化为故事,将故事转化为口头表达。从文本到引人入胜的多媒体体验,整个过程都由人工智能驱动!🚀🌟👩💻👨💻
总结:黑客马拉松成功的秘诀
最后的润色
- 测试:确保所有组件完美地协同工作。
- 用户体验:专注于创建引人入胜且直观的界面。
制胜策略
- 创造力:以独特的方式使用人工智能来应对真正的挑战。
- 演示技巧:有效表达您的应用程序的价值和功能。
- 团队合作:协作融合不同的技能和观点。
深入探究的资源
- 在OpenAI 技术页面上探索有关 OpenAI 功能的更多信息。
- 在 DALL-E-2 页面上了解有关 DALL- E 2 的详细信息。
现在,您已经掌握了为下一次黑客马拉松创建出色的 AI 应用程序的知识。拥抱创造力、技术技能和演示能力,您一定会产生影响。祝您编码愉快,我迫不及待地想看看您创造了什么!🌟🚀👩💻👨💻

















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









