






 本文详细介绍了在MySQL中查找每个用户最新订单的五种不同方法,包括使用窗口函数、INNER JOIN、LEFT JOIN、IN子句以及EXISTS。每种方法都附带了SQL语句示例,通过比较和分析,帮助读者理解各种查询策略的适用场景。
本文详细介绍了在MySQL中查找每个用户最新订单的五种不同方法,包括使用窗口函数、INNER JOIN、LEFT JOIN、IN子句以及EXISTS。每种方法都附带了SQL语句示例,通过比较和分析,帮助读者理解各种查询策略的适用场景。
mysql查找出每个用户最新的一条订单的5种解决思路
一、使用窗口函数
使用窗口函数
– 使用窗口函数:可以视为规范固定写法
row_number() over(partition by 需要分区的列 order by xxx [asc|desc])
1.解释
row_number() 函数表示行号,如果后面紧跟 over函数,则表示窗口函数,
窗口函数分为:聚合窗口函数和非聚合窗口函数
像:row_number() 、rank() 、dense_rank()等后面加上over子句就是非聚合窗口函数,像max() 、min()、avg()、count()、sum()等聚合函数后面紧跟over子句,就是聚合窗口函数啦。
窗口函数与group by 的区别就是 :
group by 强调整体为一组,所以group by 分组后,每组只有一条数据,而窗口函数更强调分区后的个体,所以会在每个分区的每行都产生一个值,所以窗口函数会返回该行的全部数据,以及窗口值,如对学生的成绩进行一个排名,这个名次就是窗口值
窗口函数的好处在于:可以对不同分区进行单独排名排序等操作,就像将中国分为23个省,每个省为一区,每个省都有高考状元一样,每个省都有前十名一样。我之前一直以为像这种分组或分区后,对每个组别进行个体操作在mysql中是很难实现的,如获取每个省的前3名的同学成绩信息等,直到我了解了窗口函数,才知道有多么牛逼。太好了,如果你学过java8 的Stream API 你就会知道,mysql的的窗口函数,也能像Collectors.groupingBy()一样…
2.上sql语句
代码如下(示例):
SELECT
ROW_NUMBER() OVER (PARTITION BY t.user_id ORDER BY id DESC) AS userRank, t.id,t.amount,t.balance,t.user_id,t.create_time,t.order_desc
FROM
t_order as t
WHERE
os_type = 1
AND IFNULL(order_from, 1) != 10
AND order_status = 1
AND user_id IN ( 6156, 6158, 6172)
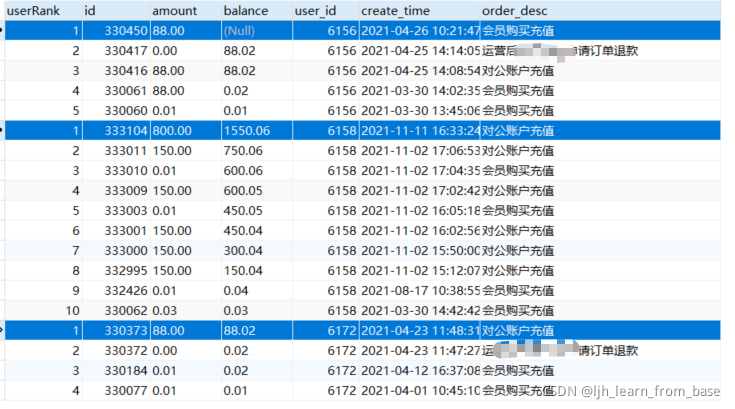
执行结果上图所示,按照每个用户的user_id 对订单进行分区,然后对每个分区进行id 倒序排,id最大的排名第一,也就是说每个分组id最大就是最新的一条数据,然鹅,这里白每个分区的排名都列出来了,我们想要的只是每组最新的一条数据,所以再加一层条件过滤一下,筛选出userRank=1的即可
代码如下(示例):
select * from (
SELECT
ROW_NUMBER() OVER (PARTITION BY t.user_id ORDER BY id DESC) AS userRank,t.id,t.amount,t.balance,t.user_id,t.create_time,t.order_desc
FROM
t_order as t
WHERE
os_type = 1
AND IFNULL(order_from, 1) != 10
AND order_status = 1
AND user_id IN ( 6156, 6158, 6172)
) as a where a.userRank=1;

二、使用inner join 或join
众所周知,inner join=join 取的是交集
代码如下(示例):
SELECT t.id,t.amount,t.balance,t.user_id,t.create_time,t.order_desc FROM t_order t
JOIN (
SELECT MAX(id) AS id FROM t_order WHERE os_type = 1 AND IFNULL(order_from, 1) != 10 AND order_status = 1
AND user_id IN ( 6156, 6158, 6172) GROUP BY user_id
) AS t1 ON t.id = t1.id
三、使用left join
众所周知,left join是取主表,即左表的全部,无论条件满不满足,
如果满足条件,则不为空,如果不满足,则为空,可以根据此,过滤不符合条件的行。注意比较与inner join 写法的区别
代码如下(示例):(实际验证中,可以将where条件去掉和加上都试一下)
SELECT * FROM t_order t
left JOIN (
SELECT MAX(id) AS id FROM t_order WHERE os_type = 1 AND IFNULL(order_from, 1) != 10 AND order_status = 1
AND user_id IN ( 6156, 6158, 6172) GROUP BY user_id
) AS t1 ON t.id = t1.id
where t1.id is not null
四、记住一句话:可以用左连接的,一般都可以用in子句 和exists改写
代码如下(示例)使用 in
SELECT * FROM t_order t where id in (
select max(id) from t_order WHERE os_type = 1 AND IFNULL(order_from, 1) != 10
AND order_status = 1 AND user_id IN ( 6156, 6158, 6172) GROUP BY user_id
)
代码如下(示例)使用exists改写
[当你发现select 的字段只用于条件判断,
而不需要进行查询显示时,即可考虑使用exists]
SELECT * FROM t_order t where EXISTS (
select * from (
select max(id) as maxId from t_order WHERE os_type = 1 AND IFNULL(order_from, 1) != 10
AND order_status = 1 AND user_id IN ( 6156, 6158, 6172) GROUP BY user_id) a
where t.id=a.maxId
)
总结
这里对文章进行总结:
问:问题到这里已经解决了,问那种方法是最优解?
学霸之所能成为学霸,是因为当看到一道题没有思路的或无从入手时,学霸早就已经联想到可行的几种解决方案,并在开始思考那种方法是最优解了
学到了就要教人,赚到了就要给人,欢迎有问题一起探讨,交流分享!
你现在多努力一分,以后老婆就多漂亮一分!

















 2832
2832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









