




 本文详细介绍了Hadoop集群的初始化配置、启动过程及通过网页和命令行验证集群状态的方法,并演示了如何使用Hadoop计算圆周率。
本文详细介绍了Hadoop集群的初始化配置、启动过程及通过网页和命令行验证集群状态的方法,并演示了如何使用Hadoop计算圆周率。
对本节配置目录不了解的,请先看上一篇文章
初始化
首次启动需要进行初始化,初始化成功不再初始化。
初始化的操作在hdfs的主节点-node1
直接执行命令
hdfs namenode -format
启动
使用官方自带启动脚本
存放目录为 /data/hadoop/hadoop-3.1.2/sbin/
启动所有 start-all.sh
停止所有 stop-all.sh
通过jps查看已启动了那些服务
[root@node1 ~]# jps
1393 NameNode
1781 ResourceManager
1497 DataNode
2812 Jps
1885 NodeManager
把之前的hosts添加到本地hosts(windows)
192.168.1.70 node1
192.168.1.71 node2
192.168.1.72 node3
访问网页查看成果喽
hadoop群集页面
http://node1:50070
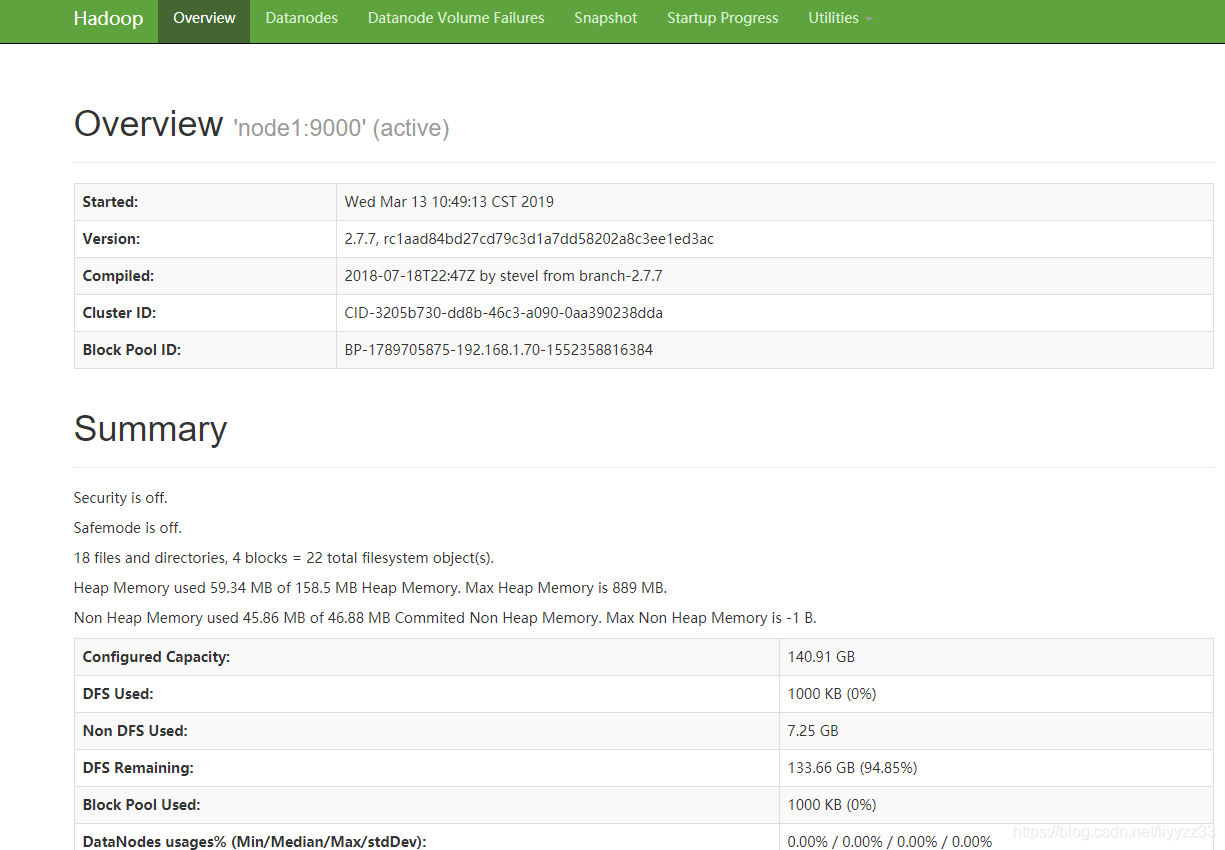
使用
Utilities - Briowse the file system 可查看当前集群的文件情况
当然现在啥也没有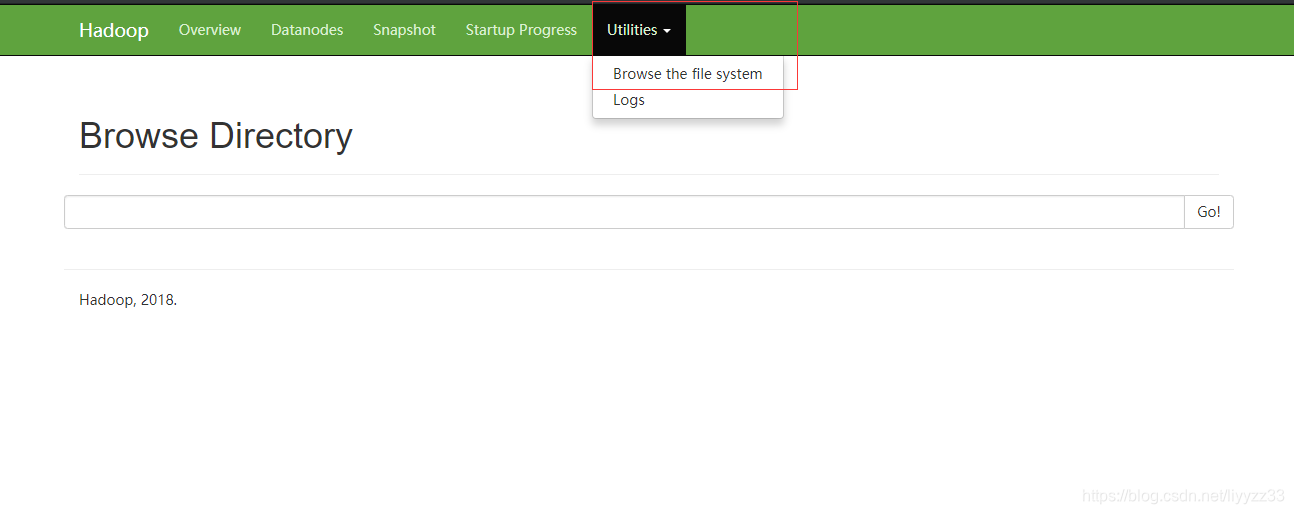
我们通过命令行也可查看
[root@node2 ~]# hdfs dfs -ls /
来通过命令行创建一个hello_world文件夹
[root@node2 ~]#hdfs dfs -mkdir /hello_world
然后往hello_world 文件夹中传一个测试文件上去(anaconda-ks.cfg)
[root@node2 ~]#hdfs dfs -put anaconda-ks.cfg /hello_world
现在再通过页面查看一下
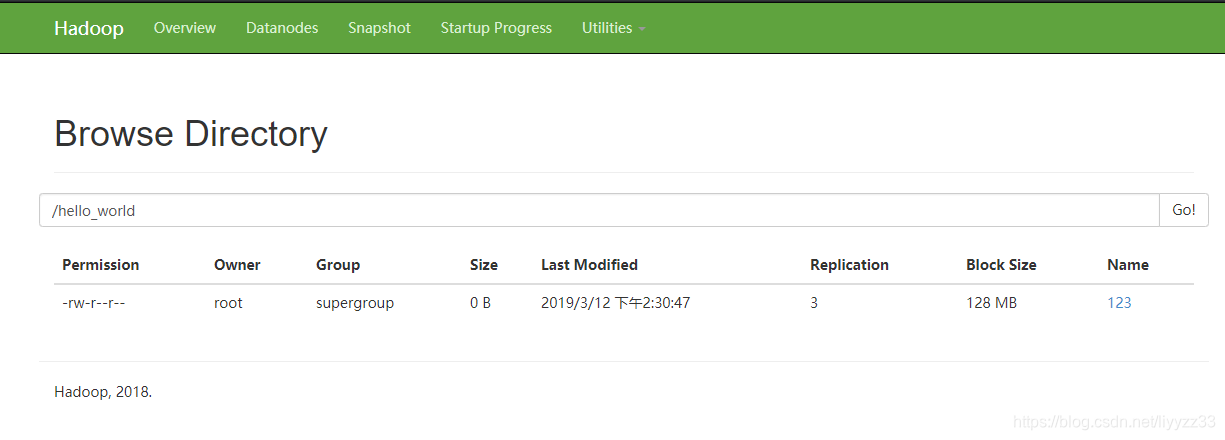
成功good!
yarn页面
http://node1:8088/cluster/
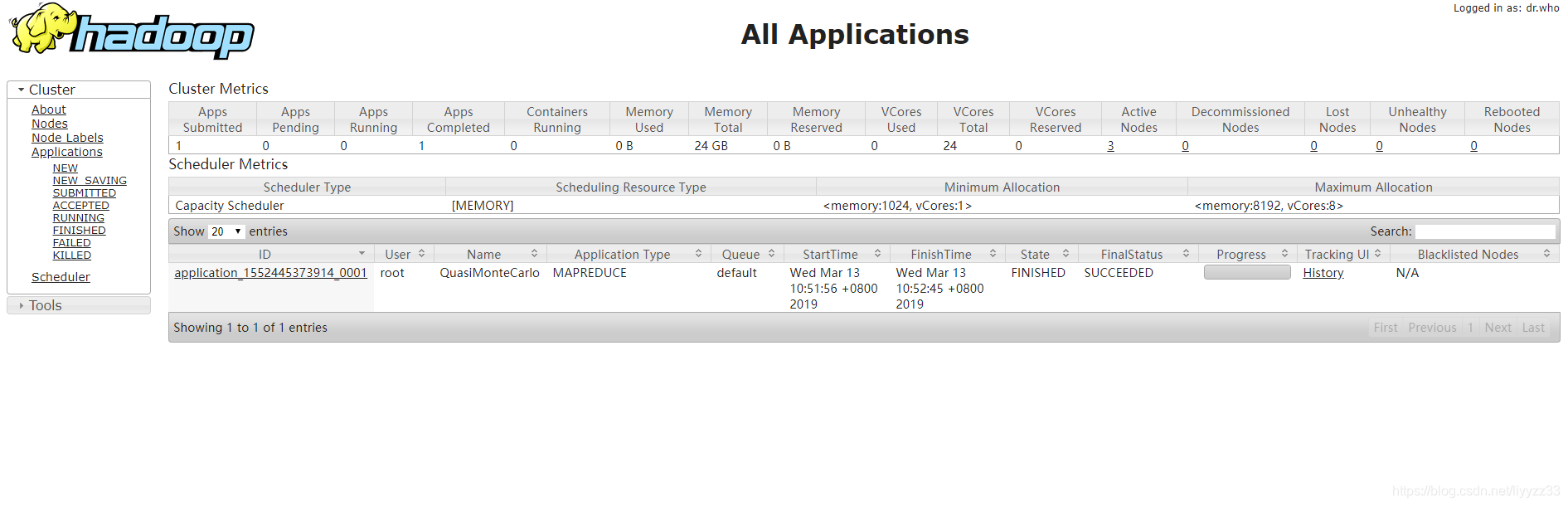
来我们通过一个官方实例来体验一下计算和调度
cd /data/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 20 50 #计算圆周率的实例
#得到结果
>Job Finished in 52.843 seconds
>Estimated value of Pi is 3.14800000000000000000
再看下你的yarn页面 里面就多了一个任务

















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









