




声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
Revisiting Over-Smoothness in Text to Speech
本文为浙江大学和微软在2022.02.26更新的文章,主要分析语音合成过平滑问题以及解决方案,具体的文章链接https://arxiv.org/pdf/2202.13066.pdf
1 背景
非自回归语音合成模型由于其快速的生成速度从而引起了学术界和工业界的广泛关注,但该模型的一个限制是它们在生成语音梅尔谱图时忽略了时域和频域的相关性,从而导致合成结果模糊和过度平滑。本文从一个新的角度重新审视了语音合成过度平滑的问题:过度平滑的程度取决于数据分布的复杂性和建模方法的能力之间的差距。简化数据分布和改进建模方法都可以缓解这个问题。
2 问题分析及解决方案
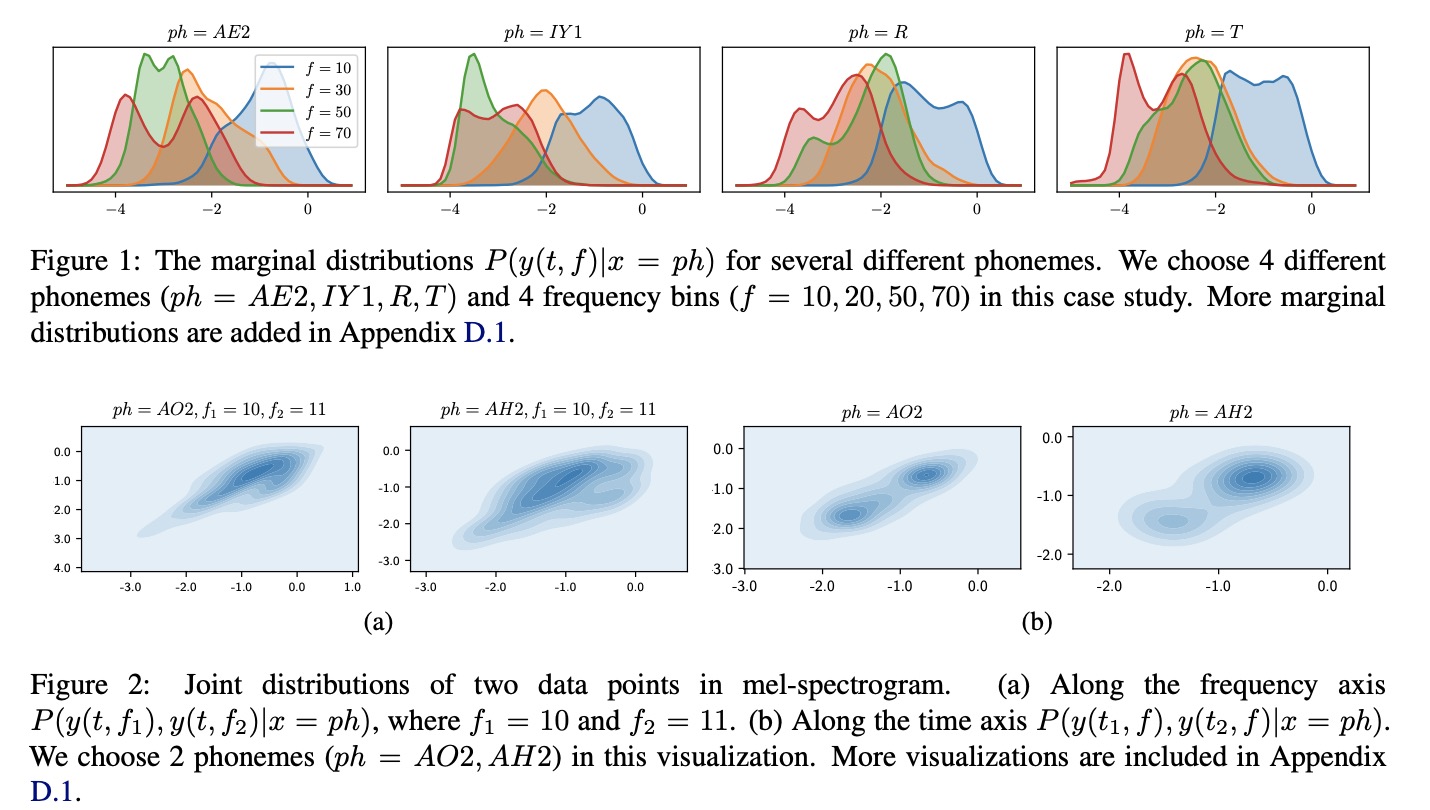
本文首先分析过平滑的问题是由于复杂的数据分布和建模方法之间的差距,即建模方法不能够对相互依赖和多峰的数据进行很好的建模。作者首先对建模数据的多峰及相互依赖进行可视化展示,结果如图1和图2所示。图1展示了mel-spectrogram的数据是多峰分布,尤其在高频部分。图2展示了数据分布不仅具有多峰分布而且有很强的相关性,因此常用的MAE or MSE loss不能够很好的对其建模。本文总结了解决过平滑问题的方案主要分为两类:simplifying data distributions和enhancing modeling methods,具体方案总结参照table 1。simplifying data distributions主要包括分解复杂的依赖分布为简单的条件分布(比如自回归)和提供更多的条件变量信息来预测mel-spectrogram(比如pitch, duration, energy等)。enhancing modeling methods方案包括SSIM、GAN、Glow等等。

3 实验分析
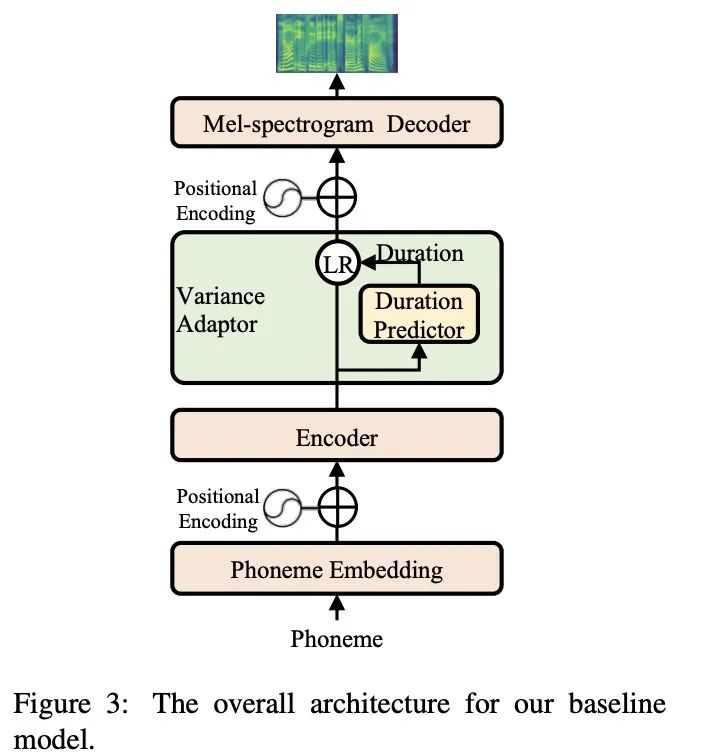
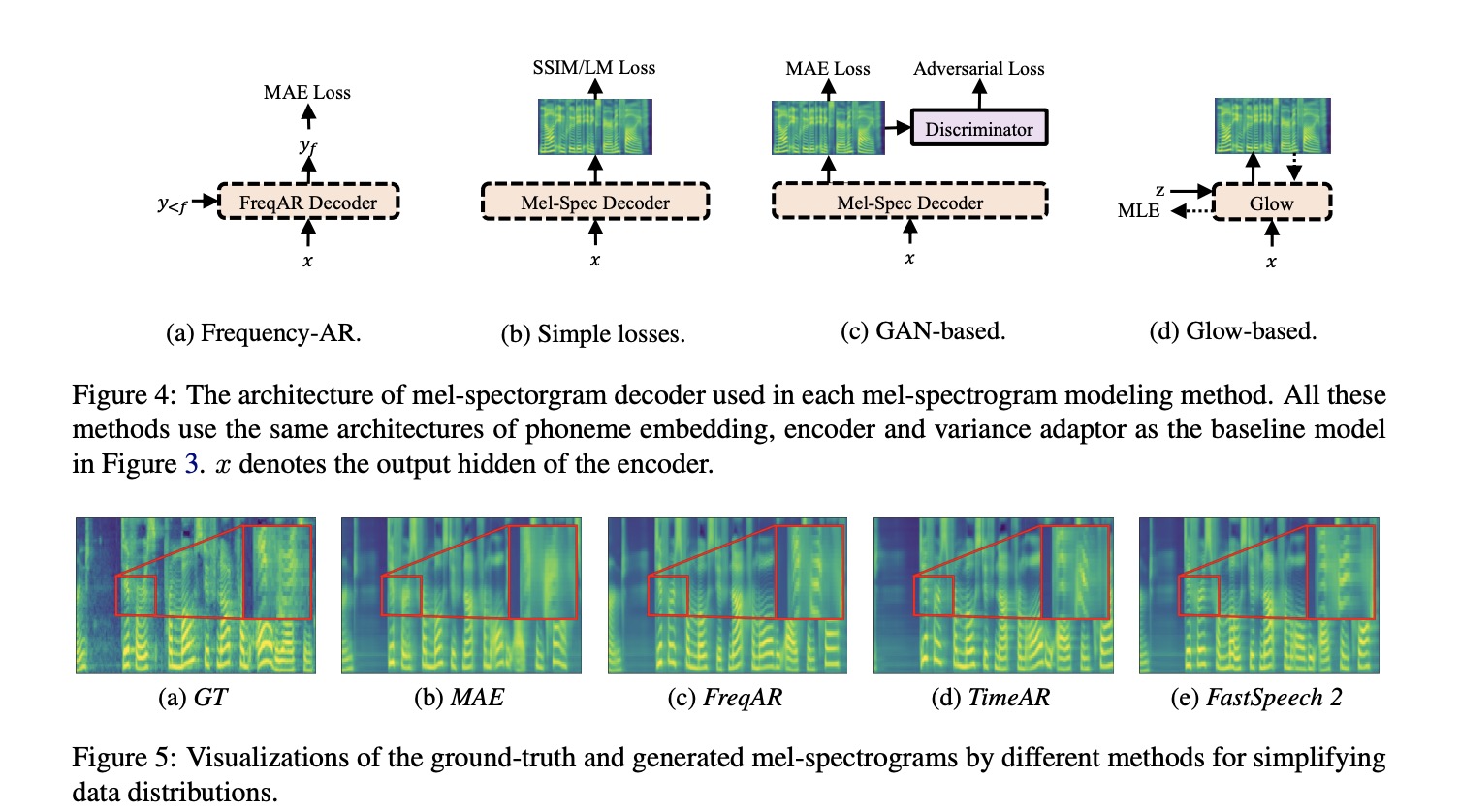
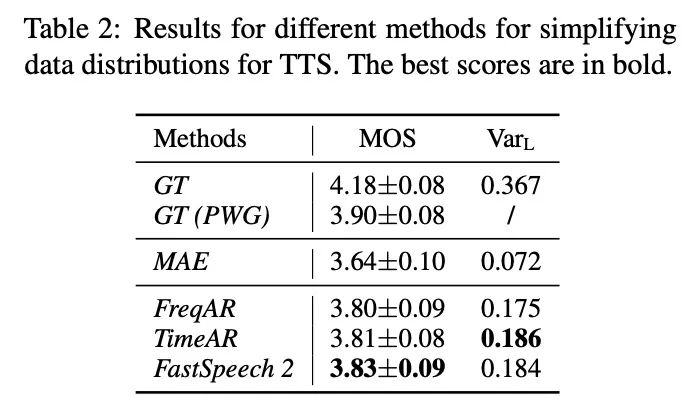
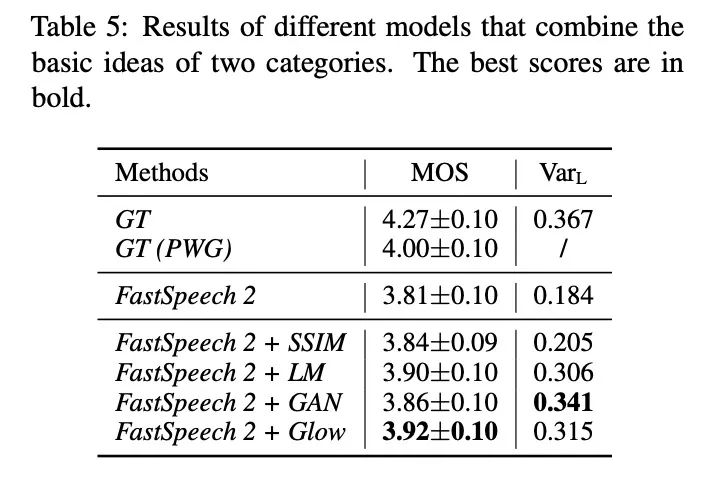
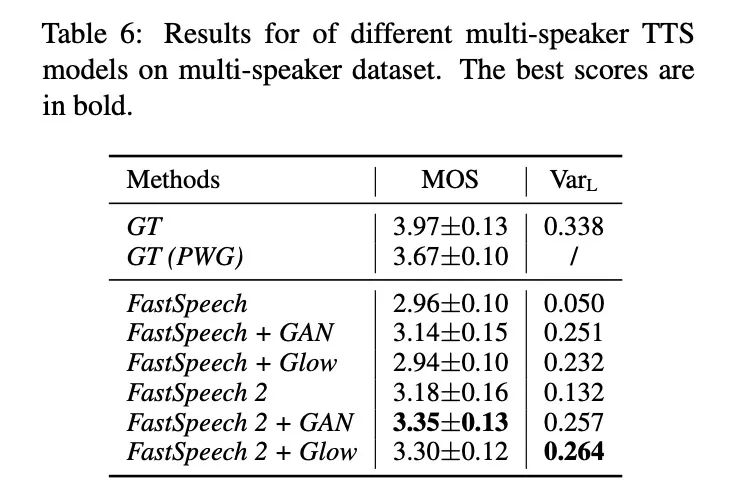
本部分将对以上的解决方案进行试验分析,使用的baseline 模型图3所示。图4展示不同建模方法。首先验证simplifying data distributions的实验,具体的结果如图5和table 2所示,使用自回归的FreqAR和TimeAR好于基准MAE,使用多变量信息的Fastspeech2效果最好。接下来看一下建模方法的实验,本文列举的方法如table 3所示,其实验结果如图6和table4所示,虽然GAN和Glow效果较好但其训练速度较为缓慢。本文结合以上的两类方案在单发音人和多发音人上进行试验,具体结果如table 5和table6所示,结合的方案可以提高合成的音频质量。


4 总结
本文是第一个对语音合成的过平滑问题进行系统分析总结,并对相应的解决方案进行试验总结,期望可以为语音社区设计更有的模型提供新颖的视角。



















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











