




声明:我主要从事语音合成,对语音识别的学习主要出于兴趣。文章内容摘要如有错误,还望读者指出,共同学习进步。
欢迎关注微信公众号:低调奋进
Comparing the Benefit of Synthetic Training Data for Various Automatic Speech Recognition Architectures
本文2021.04.12号由德国亚琛工业大学计算机科学系发布,主要对比使用TTS合成的数据对不同ASR架构的影响,具体的文章链接
https://arxiv.org/pdf/2104.05379.pdf
内容摘要
就目前的ASR架构,主要分为attention encoder-decoder(AED),connectionist-temporal-classification(CTC)和Hybrid ASR。其中效果最好的还是Hybrid ASR。本文主要使用TTS进行数据增广,使AED的性能逼近Hybrid ASR。
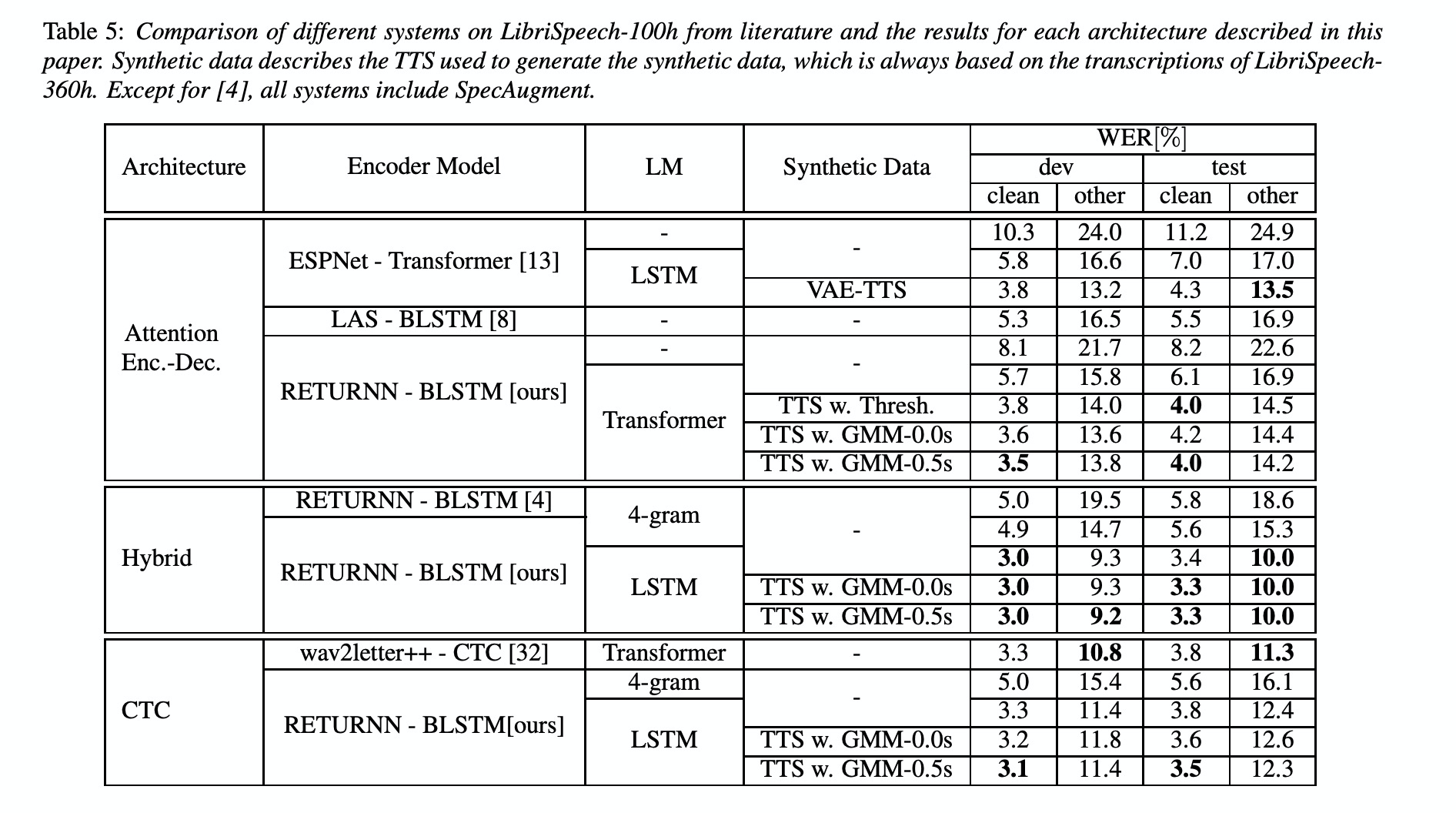
本文是TTS和ASR都使用LibriSpeech-100,合成使用的文本是LibriSpeech-360,具体的结果如table 5所示,主要的结论如下:
1)使用TTS增广数据对AED提升很大,对Hybrid ASR和CTC相对较小;
2)即使使用TTS增光数据,AED还是无法达到Hybrid ASR的性能;
3)虽然TTS数据对Hybrid ASR影响很小,本文使用LibriSpeech-100来训练Hybrid ASR,在干净和噪声数据集上获得了目前WER较好的3.3%/10%的表现。



















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











