




支持的 Catalog
| 类别(Category) | Catalog 类型(Catalog Type) | 说明 / 用途 |
|---|---|---|
| Relational | Doris catalog | 对接 Apache Doris,管理其数据库和表 |
| Hive catalog | 对接 Apache Hive Metastore,管理 Hive 表 | |
| Hudi catalog | 管理 Apache Hudi 表(通常基于 Hive 或 LakeFS) | |
| Iceberg catalog | 管理 Apache Iceberg 表(支持 Hive、JDBC、REST 等后端) | |
| MySQL catalog | 通过 JDBC 连接 MySQL,将其作为元数据源 | |
| Paimon catalog | 对接 Apache Paimon(原 Flink Table Store),用于流批一体表 | |
| PostgreSQL catalog | 通过 JDBC 连接 PostgreSQL | |
| OceanBase catalog | 对接 OceanBase 数据库(兼容 MySQL/Oracle 模式) | |
| StarRocks catalog | 对接 StarRocks,管理其数据库和表 | |
| Fileset | Fileset catalog | 管理通用文件集合(如 Parquet、CSV 文件目录) |
| Fileset catalog with S3 | 文件存储在 Amazon S3 上 | |
| Fileset catalog with GCS | 文件存储在 Google Cloud Storage (GCS) 上 | |
| Fileset catalog with OSS | 文件存储在阿里云 OSS 上 | |
| Fileset catalog with ADLS | 文件存储在 Azure Data Lake Storage (ADLS) 上 | |
| Fileset catalog index | (实验性)为 Fileset 提供索引能力 | |
| Messaging | Kafka catalog | 管理 Apache Kafka 主题(Topic)的元数据,支持 schema 注册 |
| Model | Model catalog | 管理机器学习模型元数据(如模型版本、输入/输出 schema、存储路径等,实验性功能) |
- Relational Catalogs:大多通过 JDBC 或专用客户端连接,适用于结构化数据库。
- Fileset Catalogs:适用于无 Schema 的原始文件管理,常用于数据湖场景。
- Iceberg / Hudi / Paimon:属于 表格式(Table Format)Catalog,Gravitino 可直接操作其元数据。
- Kafka & Model Catalogs:属于扩展领域,支持更广泛的元数据治理(消息队列、AI 模型)。
✅ 所有 Catalog 均可在 同一个 Metalake 下共存,实现统一元数据视图。
Catalog
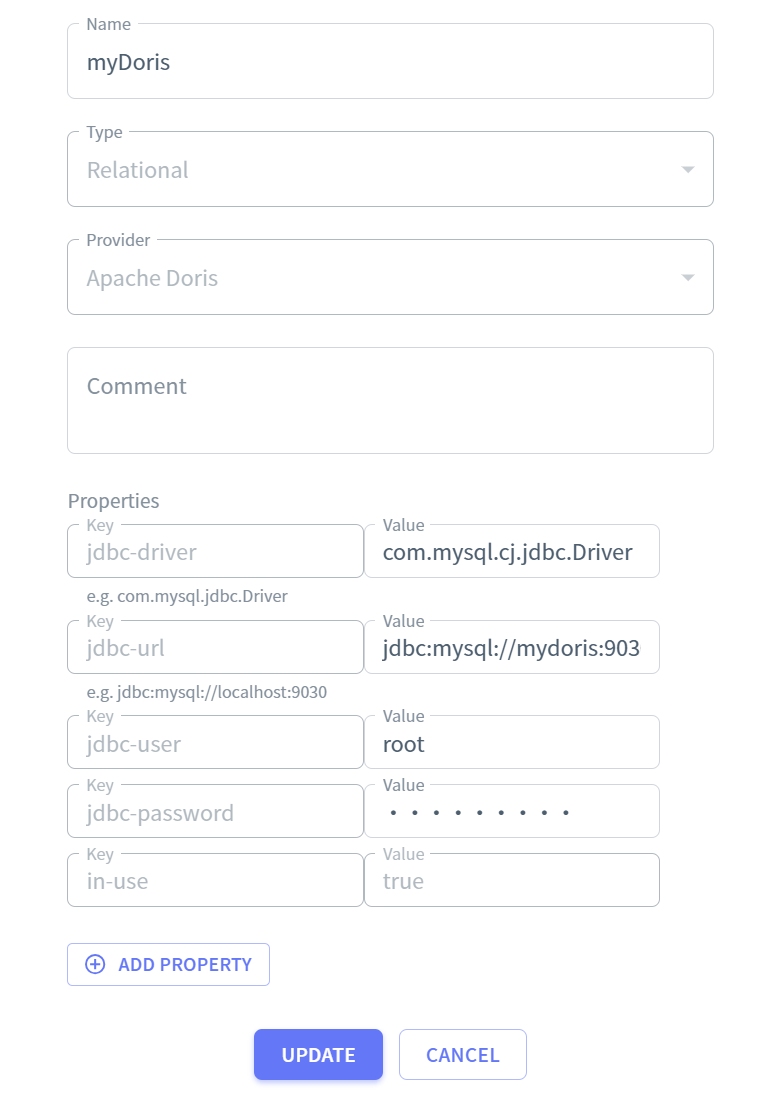
MySQL catalog
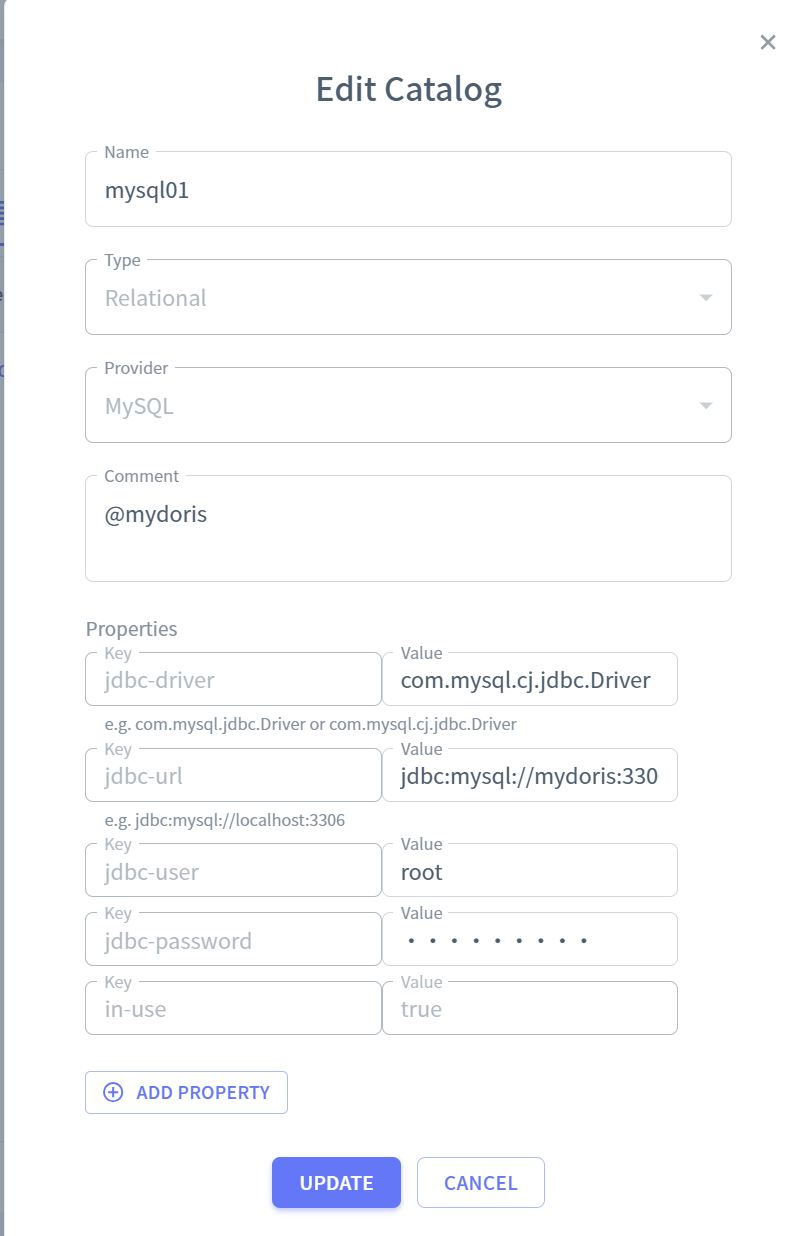
jdbc.driver : com.mysql.cj.jdbc.Driver
jdbc.url: jdbc:mysql://mydoris:3306/app_db?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
Doris catalog
jdbc.driver : com.mysql.cj.jdbc.Driver
jdbc.url: jdbc:mysql://mydoris:9030
Paimon catalog
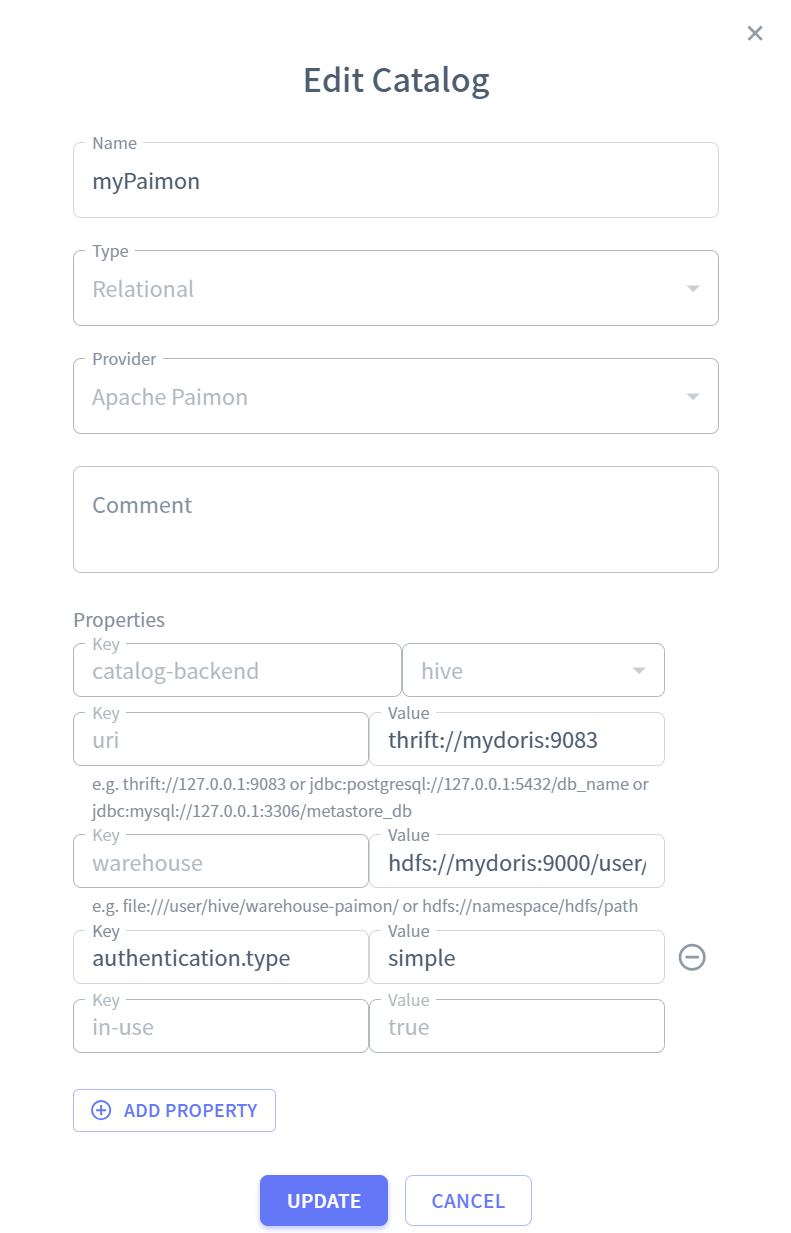
url thrift://mydoris:9083
warehouse : hdfs://mydoris:9000/user/paimon/warehouse
Iceberg catalog
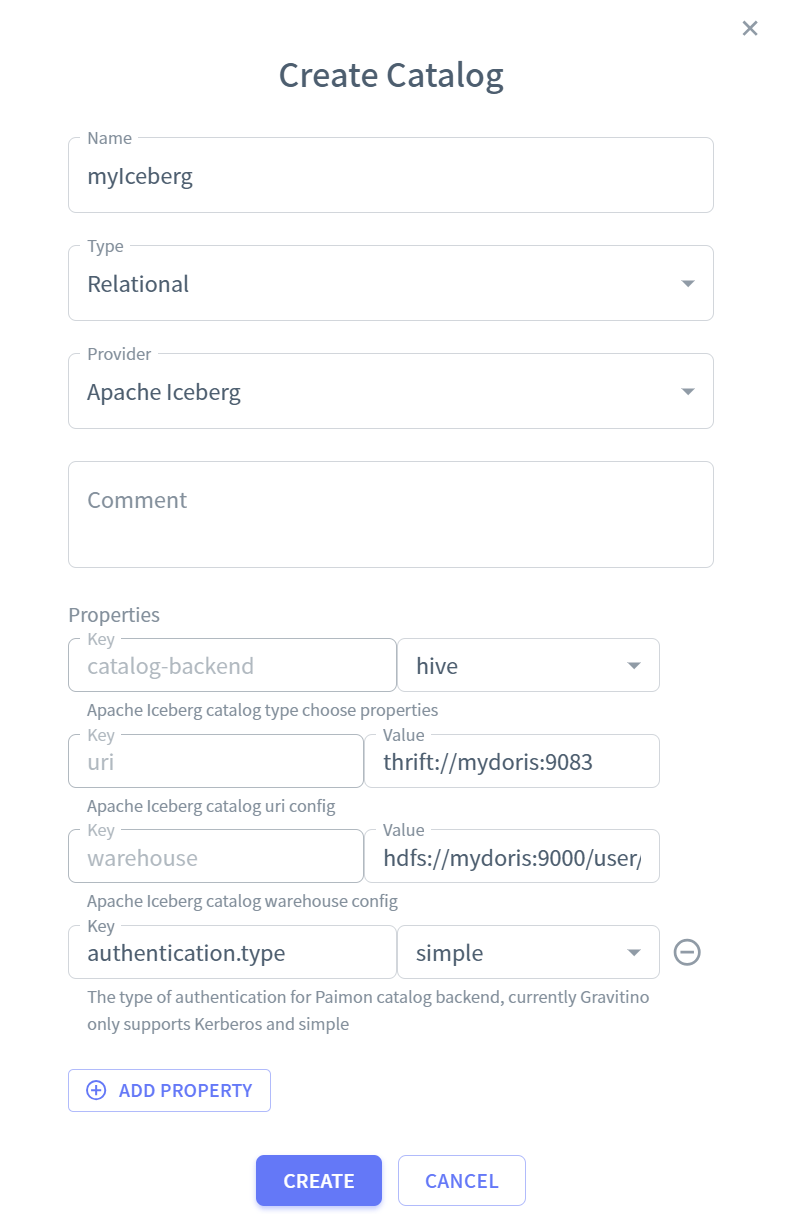
url thrift://mydoris:9083
warehouse : hdfs://mydoris:9000/user/iceberg/warehouse
kafka iceberg
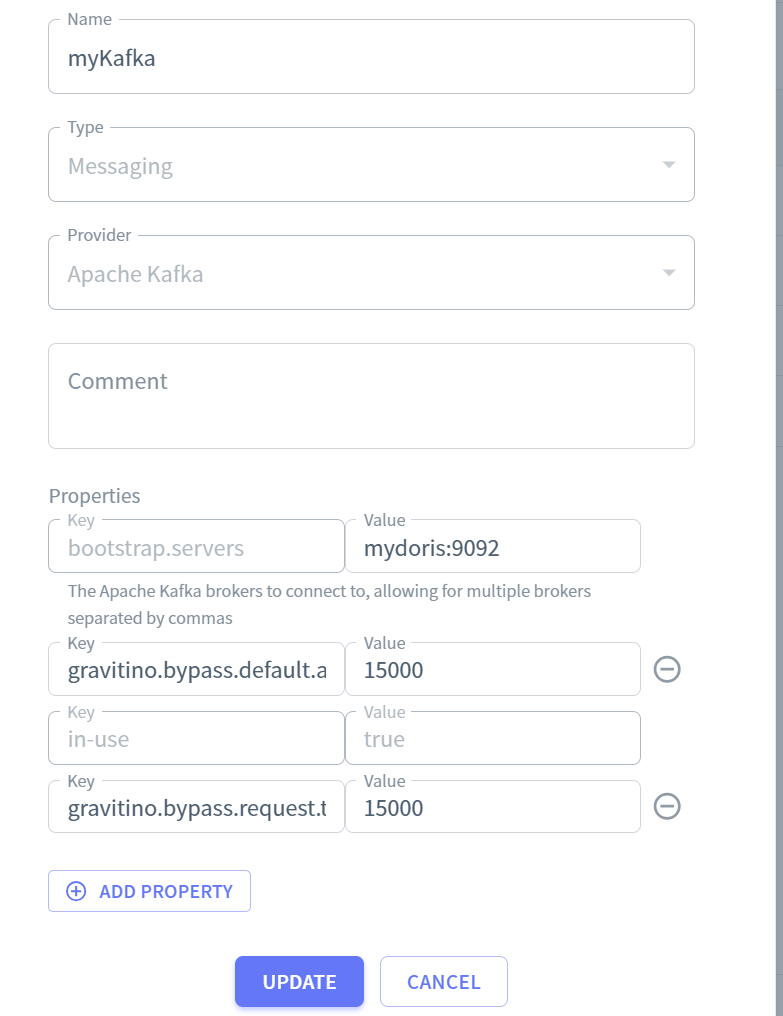
bootstrap.servers mydoris:9092
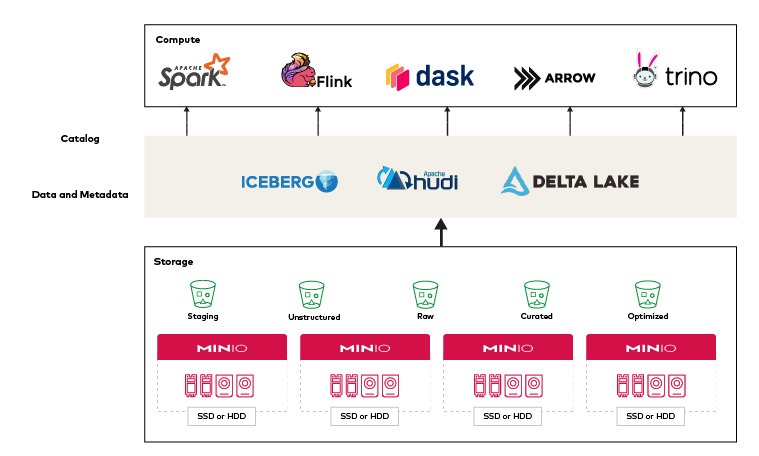
计算引擎
Flink
环境准备
上传 jar 包到 $FLINK_HOME/lib
gravitino-flink-connector-runtime-1.18_2.12-1.0.1.jar
配置flink-conf.yaml
vim $FLINK_HOME/conf/config.yaml
# Gravitino 相关
table.catalog-store.kind: gravitino
table.catalog-store.gravitino.gravitino.metalake: MyMetalake
table.catalog-store.gravitino.gravitino.uri: http://mydoris:8090
table.catalog-store.gravitino.gravitino.client.socketTimeoutMs: 60000
table.catalog-store.gravitino.gravitino.client.connectionTimeoutMs: 60000
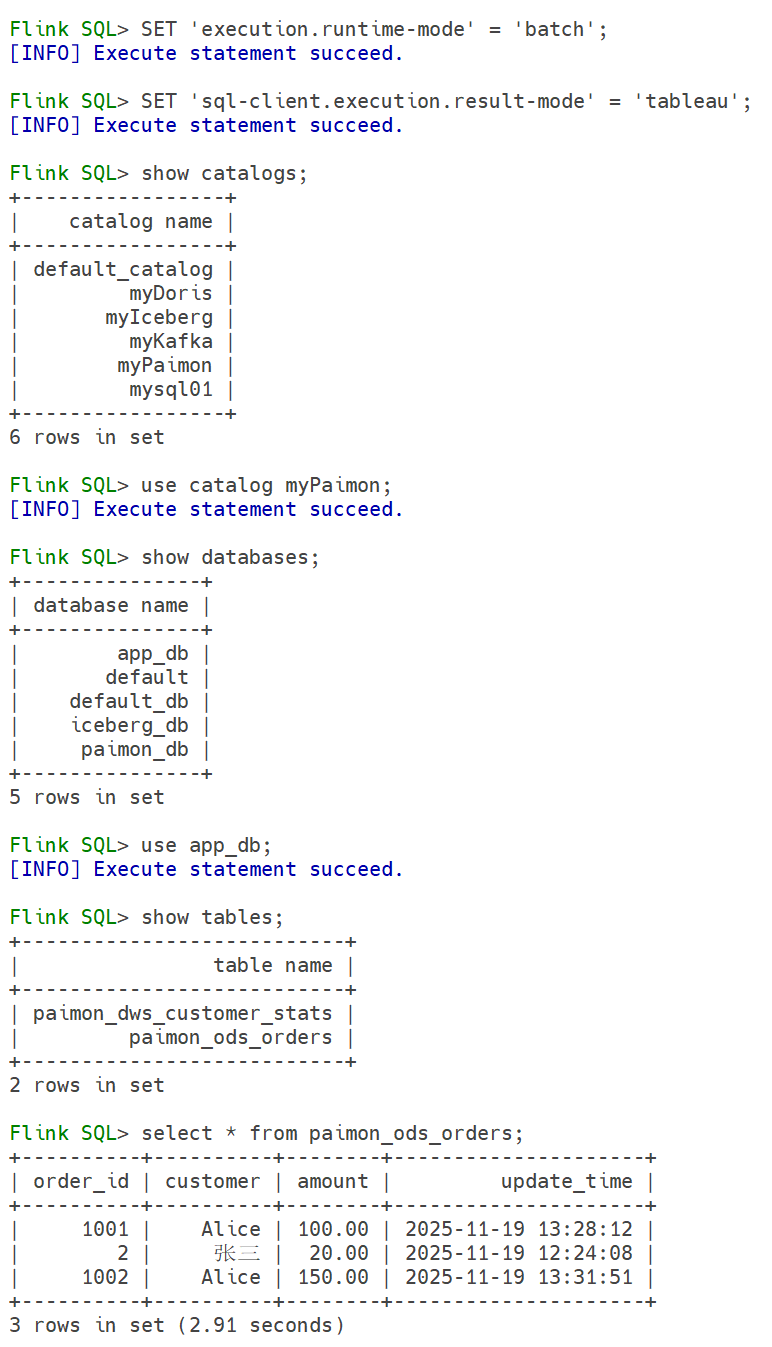
查表
# 打开 SQL Client
$FLINK_HOME/bin/sql-client.sh
-- 设置查询模式
SET 'execution.runtime-mode' = 'batch';
-- 设置输入格式
SET 'sql-client.execution.result-mode' = 'tableau';
-- 显示 catalog
show catalogs;
-- 切换 catalog
use catalog myPaimon;
-- 显示数据库
show databases;
-- 切换数据库
use app_db;
-- 查询表
show tables;
-- 查询数据
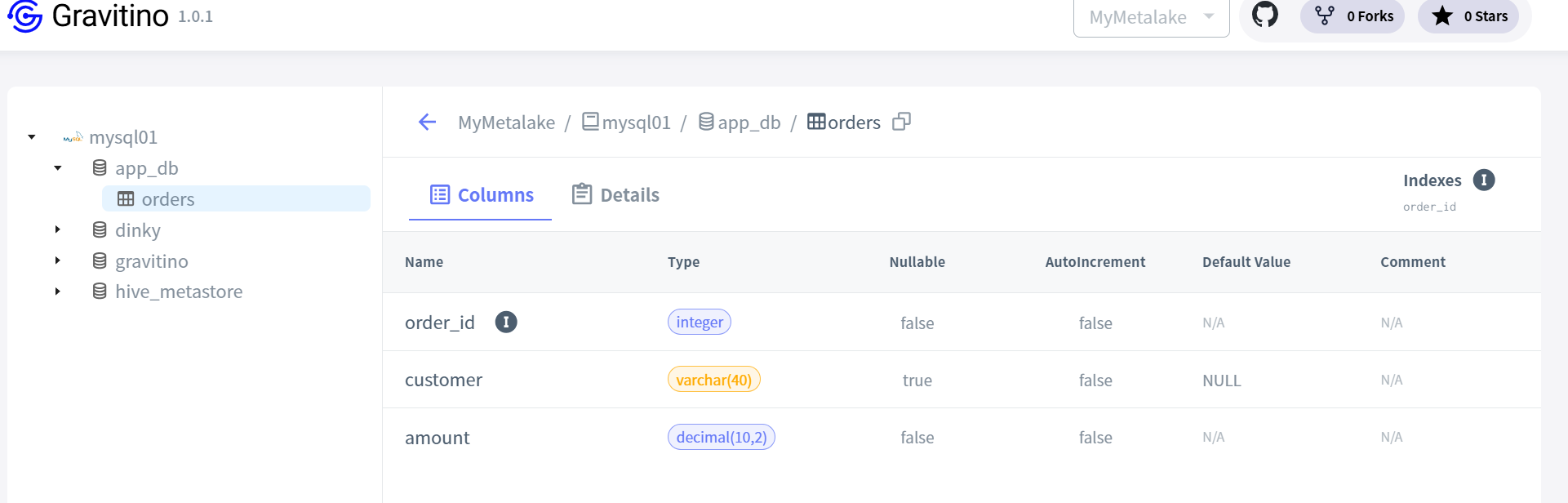
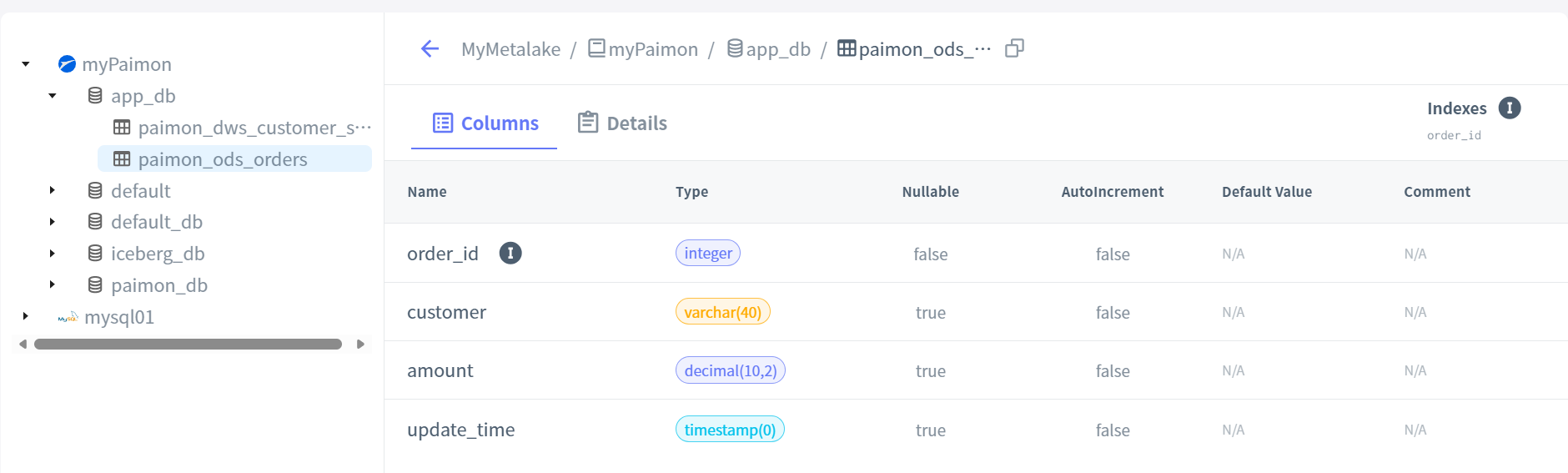
select * from paimon_ods_orders;
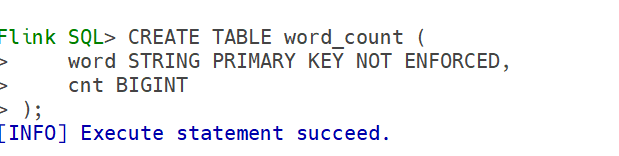
建表
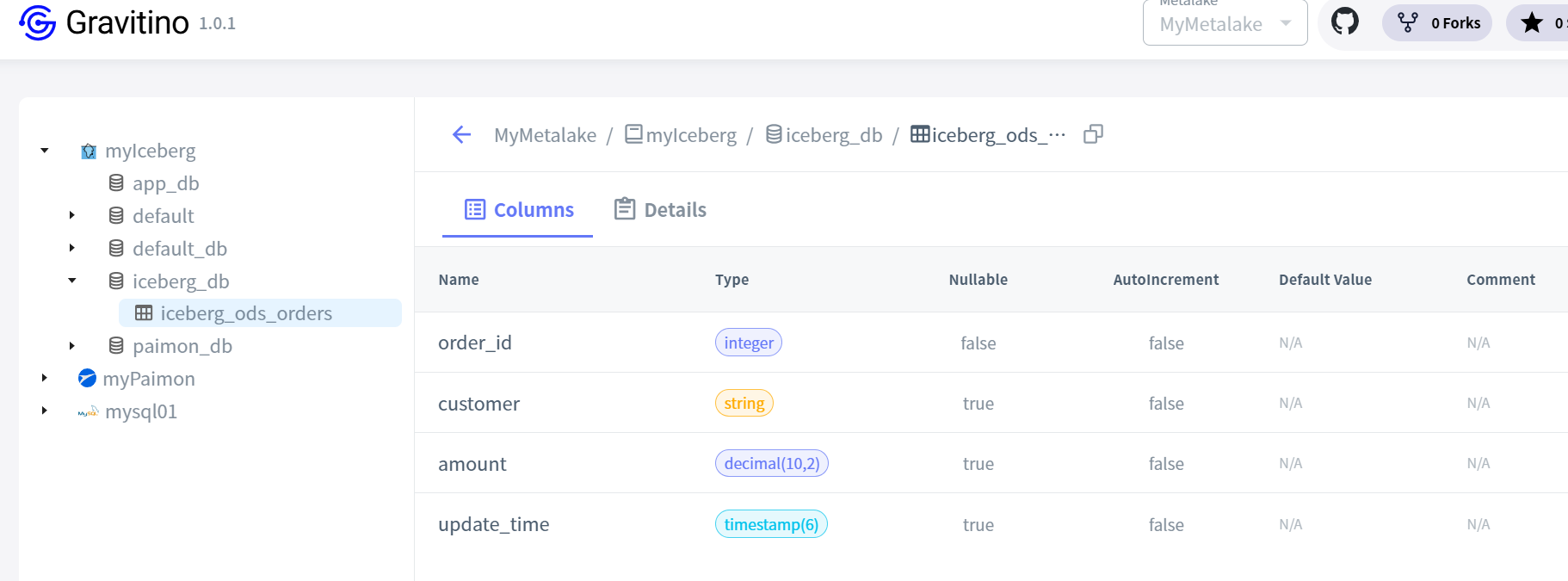
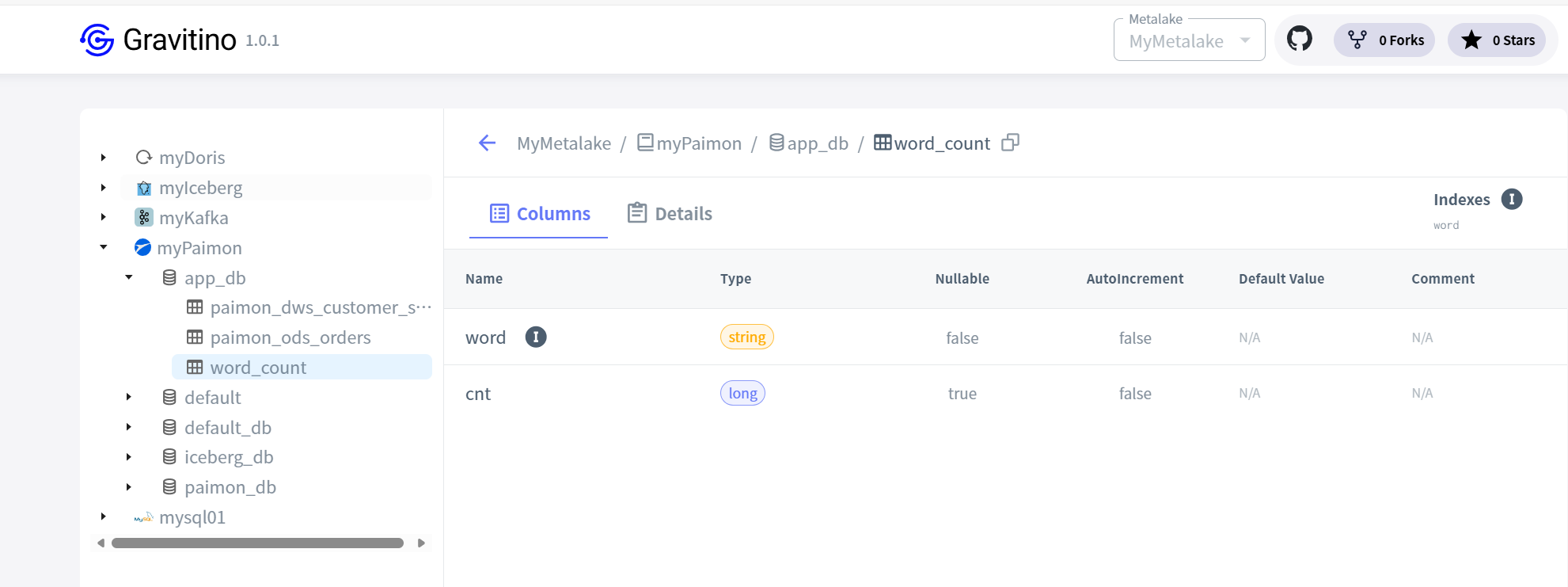
建表后,在Gravitino就能看到此表

















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









