




 本文介绍awk命令处理大文件的优势及其应用场景,并通过多个实例演示如何利用awk进行数据处理和统计,包括字段求和、条件筛选及日志分析。
本文介绍awk命令处理大文件的优势及其应用场景,并通过多个实例演示如何利用awk进行数据处理和统计,包括字段求和、条件筛选及日志分析。
awk可以处理大文件
因为awk处理文件是一行一行的处理,所以当内存空间不足时awk可以处理大文件,而cat命令不能处理一个超过内存大小的文件,因为cat是一次性全部读取文件里面的内容。
下面用实验证明这个结论:
free
free 查看内存使用的命令
-m 以M为单位显示内存的使用情况
-h 以人类能够读的懂的格式显示
B = bytes K = kilos M = megas G = gigas
T = teras
P = petas
[root@localhost 75]# free -m
total used free shared buff/cache available
Mem: 972 176 110 12 684 621
Swap: 2047 1 2046
[root@localhost 75]#
Mem: memory 内存
total 是总的物理内存(内存条的大小)
used 使用了多少内存
free 剩余多少内存
shared 共享内存消耗的空间 --》进程和进程之间通信
buff/cache --》buffer cache 缓存
buffer : data from memory to disk
cache : data from disk to memoryavailable: 可用的内存空间
一个新的进程它可以使用的内存的空间=free + buff和cache里的可用
缓存的使用空间,可以释放的
告诉内核去释放缓存的空间:
[root@localhost 75]# echo 3 >/proc/sys/vm/drop_caches
[root@localhost 75]# free -h
total used free shared buff/cache available
Mem: 972M 144M 773M 10M 54M 725M
Swap: 2.0G 3.5M 2.0G
/proc 是内核文件系统,内核是一个软件,控制操作系统的硬件,管理cpu,内存,磁盘,网卡等硬件
process
/proc文件系统 消耗也是内存的空间
sys 系统system
vm virtual memory 虚拟内存=物理内存+交换分区
物理内存:8G
10G
交换分区:swap 20G 从磁盘里划分出来的一块空间,用来当作内存使用 速度比较慢
将不活跃的进程临时存放到交换分区(冷宫)
page in
page out
什么时候算内存不足
查看系统给定的内存空间
# 当内存空间剩余30%时,内存空间不足
[root@lier 705]# cat /proc/sys/vm/swappiness
30
内核参数优化,提升进程使用的效率,告诉系统尽可能多使用物理内存,物理内存速度快。
系统开机启动的时候,内核会读取这个配置文件,进行相关参数的设置/etc/sysctl.conf
root@aliyun-sz:~# cat /etc/sysctl.conf
vm.swappiness = 0
kernel.sysrq = 1
net.ipv4.neigh.default.gc_stale_time = 120
# see details in https://help.aliyun.com/knowledge_detail/39428.html
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
# see details in https://help.aliyun.com/knowledge_detail/41334.html
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_slow_start_after_idle = 0
root@aliyun-sz:~#
使用top命令动态监控系统状态
[root@lier 705]# top
top - 05:03:34 up 1 day, 9:06, 4 users, load average: 0.01, 0.03, 0.05
Tasks: 113 total, 1 running, 112 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
[root@localhost 75]# time cat sc_bigfile.txt |wc -l
43017128
real 0m3.595s
user 0m0.495s
sys 0m2.927s
[root@localhost 75]# time tail -1 sc_bigfile.txt
username feng43017128 uid:19509
real 0m0.002s
user 0m0.001s
sys 0m0.001s
[root@localhost 75]#
# 连续的空格和:当作一个分割符号
[root@localhost 75]# awk -F"[ :]+" '{print $2,$4}' sc_bigfile.txt
# tr -s " " 将连续的空格压缩成一个空格
[root@localhost 75]# head sc_bigfile.txt |tr -s " "|awk -F"[ :]" '{print $1,$4}'
substr
substr是awk语言中的一个内置函数
substr(s, i [, n]) Return the at most n-character substring of s starting at i. If n is omitted, use the rest of s.
s是指定的字段,i是从s字段的第i个开始数,n表示n个
[root@localhost 75]# cat test.txt
2022-7-1 00:01:01 78
2022-7-1 00:01:04 89
2022-7-1 00:03:01 178
2022-7-1 00:03:05 890
2022-7-2 00:03:01 178
2022-7-3 00:03:05 890
2022-7-30 00:03:01 178
2022-7-31 00:07:05 8900
# 截取第一个字段的从第1个字符开始数4个
[root@localhost 75]# cat test.txt |awk '{print substr($1,1,4)}'
2022
2022
2022
2022
2022
2022
2022
2022
# 截取第一个字段的从第6个字符开始数1个
[root@localhost 75]# cat test.txt |awk '{print substr($1,6,1)}'
7
7
7
7
7
7
7
7
练习
算出2022年7月份里的每一个分钟的流量,具体日志文件格式如下:
2022-7-1 00:01:01 78
2022-7-1 00:01:04 89
2022-7-1 00:03:01 178
2022-7-1 00:03:05 890
2022-7-2 00:03:01 178
2022-7-3 00:03:05 890
…
2022-7-30 00:03:01 178
2022-7-31 00:07:05 8900
[root@localhost 75]# awk '{time[$1,substr($1,5,1),substr($2,1,5)]+=$3}END{for (i in time)print i,time[i]}' test.txt |sort -n -k 3 -t -
2022-7-1-00:01 167
2022-7-1-00:03 1068
2022-7-2-00:03 178
2022-7-3-00:03 890
2022-7-30-00:03 178
2022-7-31-00:07 8900
[root@localhost 75]#
time[$1,substr($1,5,1),substr($2,1,5)]+=$3 表示将年月日和小时分钟(substr($2,1,5))拼接作为key,流量($3)作为value,将每分钟的流量相加再用for循环输出统计后的每分钟的流量
使用awk进行求和运算
统计用户uid大于1000并且shell是使用bash的用户的数量
[root@localhost 75]# awk -F: 'BEGIN{num=0}$3>1000 && $NF ~ /bash/{print $0;num++}END{print num}' /etc/passwd
bashzhang:x:1004:1004::/home/bashzhang:/bin/bash
liu1:x:1006:1006::/home/liu1:/bin/bash
zhangliu1:x:1007:1007::/home/zhangliu1:/bin/bash
liu:x:1008:1008::/home/liu:/bin/bash
fengdeyong:x:1011:1011::/home/fengdeyong:/bin/bash
5
awk中的字段求和(累加)
[root@localhost lianxi]# cat grade.txt
id name chinese english math
1 cali 80 80 80
2 tom 90 90 70
3 jarry 70 100 90
12 cali 80 80 80
11 tom 90 90 70
13 jarry 70 100 90
[root@localhost lianxi]# awk 'NR>1{sum+=$3}END{print sum}' grade.txt
480
[root@localhost lianxi]# awk 'BEGIN{sum=0}NR>1{sum+=$3}END{print sum}'grade.txt
480
awk的内置函数length,substr
统计没有设置密码的用户的数量,同时输出用户名
/etc/shadow
[root@localhost lianxi]# awk -F: 'length($2)<=2 {print $1;sum++}END{print sum}' /etc/shadow
统计没有设置密码的用户的数量,同时输出用户名前2个字符
[root@localhost lianxi]# awk -F: 'length($2)<=2 {print substr($1,1,2);sum++}END{print sum}' /etc/shadow
练习
1.只显示df -h结果的第一列文件系统
[root@lier 705]# df -h|awk '{print $1}' 文件系统 devtmpfs tmpfs tmpfs tmpfs /dev/mapper/centos-root /dev/sda1 tmpfs2.显示passwd文件的第5行和第10行的行号和用户名
[root@lier 705]# awk -F: 'NR==5 || NR==10 {print NR,$1}' /etc/passwd 5 lp 10 operator3.使用NF变量显示passwd文件倒数第二列的内容
[root@lier 705]# awk -F: '{print $(NF-1)}' /etc/passwdxxxxxxxxxx awk -F: '{print $(NF-1)}' /etc/passwd[root@lier 705]# awk -F: '{print $(NF-1)}' /etc/passwd4.显示passwd文件中第5到第10行的用户名
[root@lier 705]# awk -F: 'NR>=5 && NR<=10{print $1}' /etc/passwd lp sync shutdown halt mail operator5.显示passwd文件中第7列不是bash的用户名
[root@lier 705]# awk -F: '$3<1000{print $1}' /etc/passwd6.显示passwd文件中行号是5结尾的行号和整行内容
[root@lier 705]# awk -F: 'NR ~/5$/{print NR,$0}' /etc/passwd 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 15 systemd-bus-proxy:x:999:997:systemd Bus Proxy:/:/sbin/nologin 25 chx:x:1004:1004::/home/chx:/bin/bash 35 luoyawei:x:1041:1041::/home/luoyawei:/bin/bash 45 zhaojunjie:x:7797:7797::/home/zhaojunjie:/bin/bash 55 user8:x:7807:7808::/home/user8:/bin/bash 65 user18:x:7817:7818::/home/user18:/bin/bash 75 user08:x:7827:7828::/home/user08:/bin/bash 85 lyl:x:10004:10004::/home/lyl:/bin/bash 95 cali10:x:10014:10014::/home/cali10:/bin/bash 105 cali20:x:10024:10024::/home/cali20:/bin/bash 115 mi:x:10034:10034::/home/mi:/bin/bash 125 yueyang:x:10045:10042::/home/yueyang:/bin/bash7.用ifconfig/ip add 只显示ip
yum install net-tools -y -->安装ifconfig命令的软件[root@lier 705]# ifconfig|awk 'NR==2{print $NF}' 192.168.1.2558.ifconfig 命令后使用awk显示ens33的入站流量和出站流量(字节)
[root@lier 705]# ifconfig|awk 'NR==5 || NR==7{print $1,$5}' RX 336596366 TX 14454204759.使用awk命令统计以r开头的用户数目,显示如下效果
[root@lier 705]# awk 'BEGIN{num=0}/^r/{num+=1}END{print num}' /etc/passwd 110.显示每隔2秒的流量的变化
[root@lamp-test ~]# watch -n 2 -d “ifconfig|awk ‘NR==5{print $5}’”
11.统计/etc/passwd文件里以r开头的用户的数量,并且显示出用户名[root@lier 705]# awk -F: 'BEGIN{num=0}/^r/{print $1;num+=1}END{print num}' /etc/passwd root 1
awk使用shell变量
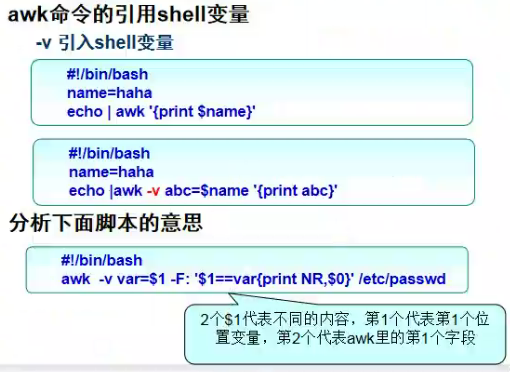
[root@lier 705]# echo |awk -F: -v username=$name '{print username}'
mengmeng
[root@lier 705]# ls |awk -F: -v username=$name '{print username}'
mengmeng
mengmeng

[root@lier 705]# awk -F: "\$1~/$mn/{print \$0}" /etc/passwd
mengmeng:x:10049:10049::/home/mengmeng:/bin/bash
mengmeng1:x:10050:10050::/home/mengmeng1:/bin/bash
mengmeng12:x:10051:10051::/home/mengmeng12:/bin/bash
if语句

单分支
[root@lier 705]# cat /etc/passwd|awk -F: 'length($1)==3{print $0}'
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
lwq:x:1002:1002::/home/lwq:/bin/bash
chx:x:1004:1004::/home/chx:/bin/bash
lqt:x:1010:1010::/home/lqt:/bin/bash
lyl:x:10004:10004::/home/lyl:/bin/bash
[root@lier 705]# cat /etc/passwd|awk -F: '{if (length($1)==3) print $0}'
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
lwq:x:1002:1002::/home/lwq:/bin/bash
chx:x:1004:1004::/home/chx:/bin/bash
lqt:x:1010:1010::/home/lqt:/bin/bash
lyl:x:10004:10004::/home/lyl:/bin/bash
双分支
[root@lier 705]# cat /etc/passwd|awk -F: '{if (length($1)==3) print $0;else print $1}'
多分支
找出超级用户、系统用户、普通用户
awk -F: '{if ($3==0) print $1,"为超级用户";else if($3>0 && $3<1000) print $1,"为系统用户";else print $1,"为普通用户"}' /etc/passwd
找出超级用户、系统用户、普通用户并统计用户数量
[root@lier 705]# awk -F: '{if ($3==0) {print $1,"为超级用 户";num1++;}else if($3>0 && $3<1000) {print $1,"为系统用户";num2++;}else {print $1,"为普通用户";num3++}}END{print " 超级用户的数量是:"num1,"系统用户的数量:"num2,"普通用户的数量:"num3}' /etc/passwd
for循环
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DkZcYT5S-1657026505736)(C:\Users\lier\AppData\Roaming\Typora\typora-user-images\image-20220705165522617.png)]
[root@lier 705]# awk -F: '{user[$1]=$3}END{for (i in user) print user[i]}' /etc/passwd
练习
练习: 对nginx的日志文件access.log进行分析,分析出单个ip地址累计下载获取的文件大小的总数(对每次访问数据的大小进行求和),显示下载总数最大的前100个ip地址和下载文件大小,按照下载文件大小的降序排列
[root@lier 705]# awk '{access[$1]+=$10}END{for (i in access) print i,access[i]}' access.log |sort -k 2 -n -r|head -100 result.txt
以下是nginx日志的字段含义
timeiso8601∣time_iso8601|timeiso8601∣host|httpcfconnectingip∣http_cf_connecting_ip|httpcfconnectingip∣request|status∣status|status∣body_bytes_sent|httpreferer∣http_referer|httpreferer∣http_user_agent
-------------------------------------
2019-04-25T09:51:58+08:00|a.google.com|47.52.197.27|GET /v2/depth?symbol=aaa HTTP/1.1|200|24|-|apple
2019-04-25T09:52:58+08:00|b.google.com|47.75.159.123|GET /v2/depth?symbol=bbb HTTP/1.1|200|407|-|python-requests/2.20.0
2019-04-25T09:53:58+08:00|c.google.com|13.125.219.4|GET /v2/ticker?timestamp=1556157118&symbol=ccc HTTP/1.1|200|162|-|chrome
2019-04-25T09:54:58+08:00|d.shuzibi.co|-||HEAD /justfor.txt HTTP/1.0|200|0|-|-
2019-04-25T09:55:58+08:00|e.google.com|13.251.98.2|GET /v2/order_detail?apiKey=ddd HTTP/1.1|200|231|-|python-requests/2.18.4
2019-04-25T09:56:58+08:00|f.google.com|210.3.168.106|GET /v2/trade_detail?apiKey=eee HTTP/1.1|200|24|-|-
2019-04-25T09:57:58+08:00|g.google.com|47.75.115.217|GET /v2/depth?symbol=fff HTTP/1.1|200|397|-|python-requests/2.18.4
2019-04-25T09:58:58+08:00|h.google.com|47.75.58.56|GET /v2/depth?symbol=ggg HTTP/1.1|200|404|-|safari
2019-04-25T09:59:58+08:00|i.google.com|188.40.137.175|GET /v2/trade_detail?symbol=hhh HTTP/1.1|200|6644|-|-
2019-04-25T10:01:58+08:00|j.google.com|2600:3c01:0:0:f03c:91ff:fe60:49b8|GET /v2/myposition?apiKey=jjj HTTP/1.1|200|110|-|scan
1、计算每分钟的带宽(body_bytes_sent)
[root@lier 705]# awk -F"|" '{flow[substr($1,1,16)]+=$(NF-2)}END{for (i in flow) print i,flow[i]}' nginx.log 2019-04-25T10:01 110 2019-04-25T09:56 24 2019-04-25T09:57 397 2019-04-25T09:58 404 2019-04-25T09:59 6644 2019-04-25T09:51 24 2019-04-25T09:52 407 2019-04-25T09:53 162 2019-04-25T09:54 0 2019-04-25T09:55 2312、统计每个URI(即不带问号?前面的内容)的每分钟的频率
/v2/myposition?apiKey=jjj 中的/v2/myposition[root@lier 705]# awk -F"[| ?]+" '{flow[substr($1,1,16)$5]+=1}END{for (i in flow) print i,flow[i]}' nginx.log 2019-04-25T09:55/v2/order_detail 1 2019-04-25T10:01/v2/myposition 1 2019-04-25T09:59/v2/trade_detail 1 2019-04-25T09:53/v2/ticker 1 2019-04-25T09:58/v2/depth 1 2019-04-25T09:57/v2/depth 1 2019-04-25T09:52/v2/depth 1 2019-04-25T09:51/v2/depth 1 2019-04-25T09:56/v2/trade_detail 1 2019-04-25T09:54/justfor.txt 1

















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









