




 本文探讨了Python爬虫在处理网页时遇到的乱码问题,主要原因是网页编码格式与存储格式不一致,特别是GBK编码的页面。介绍了UTF-8和GBK编码的特点,以及Unicode作为转换桥梁的角色。并提供了一个解决乱码问题的参考链接。
本文探讨了Python爬虫在处理网页时遇到的乱码问题,主要原因是网页编码格式与存储格式不一致,特别是GBK编码的页面。介绍了UTF-8和GBK编码的特点,以及Unicode作为转换桥梁的角色。并提供了一个解决乱码问题的参考链接。
问题原因:
爬取的所有网页无论何种编码格式,都转化为utf-8格式进行存储,与源代码编码格式不同所以出现乱码。
目前大部分都是utf-8格式,一部分是gbk格式或者(会出现乱码),还有一些不常见的,比如Windows-1254,UTF-8-SIG等这里不做讨论。国内网页还没有看到别的编码格式,欢迎补充指正!
简单科普一下:
UTF-8通用性比较好,是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24位(三个字节)来编码。
UTF-8编码的文字可以在各国各种支持UTF8字符集的浏览器上显示,也就是必须两者都是utf-8才行。
gbk是是国家编码,通用性比UTF8差,GB2312之类的都算是gbk编码。
GBK包含全部中文字符;UTF-8则包含全世界所有国家需要用到的字符。
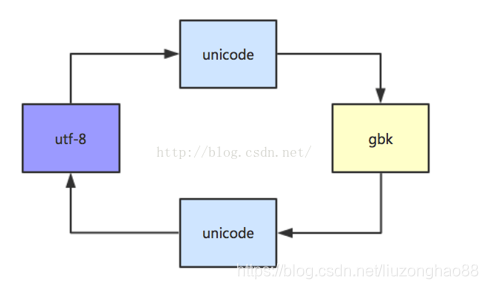
unicode是一种二进制编码,所有utf-8和gbk编码都得通过unicode编码进行转译,即utf-8和gbk编码之间不能直接转换。附图如下:
解决办法:
page =requests.get(url)
encoder = 'utf-8'
try:
html = urllib.request.urlopen(url).read()
encoder = chardet.detect(html)['encoding']
except Exception as e:
print(e)
if encoder == 'utf-8' or encoder == 'UTF-8':
pass
elif encoder == 'GBK' or encoder == 'gbk':
page.encoding = 'GBK'
elif encoder == 'GB2312'  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









