



 本文介绍了一个简单的Python爬虫项目,用于抓取豆瓣电影Top250榜单中的电影名称,并详细记录了使用Python3.6环境下PyCharm进行开发的过程。通过正则表达式和BeautifulSoup解析网页,最终将数据存储到本地文件。
本文介绍了一个简单的Python爬虫项目,用于抓取豆瓣电影Top250榜单中的电影名称,并详细记录了使用Python3.6环境下PyCharm进行开发的过程。通过正则表达式和BeautifulSoup解析网页,最终将数据存储到本地文件。
1、开发环境
Windows 10 + PyCharm (Python3.6)
在下学习python有很长一段时间了,但是对于爬虫技术不咋滴,今天学习了一下爬虫。如有出处,请阅读者指出,让我们共同学习,共同进步,Just Do DT ----> From zero to hero。
# -*- coding: utf-8 -*-
"""
@Time: 2018/8/11 10:52
@Author: JustDoDT
@Version: V1.0
"""
import requests,re
from bs4 import BeautifulSoup
print("现在开始从豆瓣电影Top250中抓取数据.......")
for page in range(10):
url = 'https://movie.douban.com/top250?start='+str(page*25)+'&filter='
print('##########正在爬取第'+str(page+1)+'页的数据###########')
#获取网页源代码
html = requests.get(url)
soup = BeautifulSoup(html.text,'html.parser')
soup = str(soup) #利用正则表达式将网页转换为字符串
#该函数根据包含的正则表达式字符串创建模式对象
title = re.compile(r'<span class="title">(.*)</span>')
names = re.findall(title,soup)
for name in names:
if name.find('/') == -1: #剔除英文名
with open('F:/网络爬虫/DoubanMovie.txt', 'a', encoding='utf-8') as f:
print(name)
f.write('##########正在爬取第'+str(page+1)+'页的数据###########')
f.write(name)
# if __name__ == '__main__' :
# save_info(name)
运行结果截图如下:
2、然后把此运行的文档存放在本地的文件夹中
在文件夹中查看,截图如下
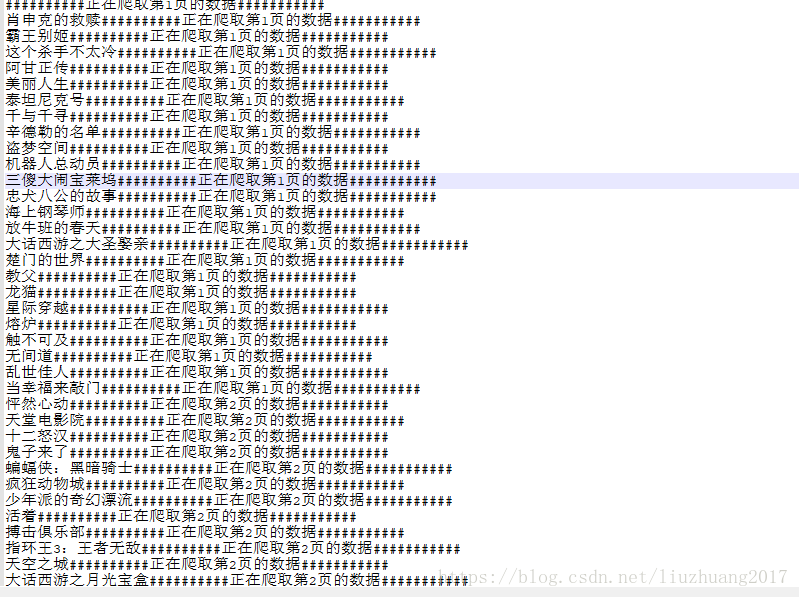
小结:注意读写文件的三种方式,这里需要指出指出的是,一定不能用w这种模式,因为他是覆盖以前的,最后只保存最后一行的内容,一定需要用a或者a+这种模式,他不覆盖前面的内容。

















 4131
4131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









