



 本文详细介绍了MySQL5.6环境下主从复制的搭建流程及常见故障处理,包括单向、双向、链式级联复制原理,通过具体步骤演示如何在线搭建主从环境,以及如何使用percona-toolkit等工具解决主从复制中常见的1062、1032、1593、1236错误。
本文详细介绍了MySQL5.6环境下主从复制的搭建流程及常见故障处理,包括单向、双向、链式级联复制原理,通过具体步骤演示如何在线搭建主从环境,以及如何使用percona-toolkit等工具解决主从复制中常见的1062、1032、1593、1236错误。
.MySQL5.6在线搭建主从复制实验与主从经典故障处理
1.MySQL主从复制概述
mysql支持单向,双向,链式级联,异步复制,半同步复
制(mysql5.5版本之后),复制过程中,
一台服务器当主master,而一个或者多个服务器slave.
复制可以是单向:M-->S,也可以双向M<-->M
如设置了链式级联复制,那么从服务器本身除了
充当slave之外,还是其下面从服务器的主服务器
结构如是:M-->S1-->S2-->S3的复制形式
2.主从复制原理
复制是mysql数据库提供的一种高可用、高性能的解决方案,一般用来建立大型的应用。复制的工作原理分为三个步骤:
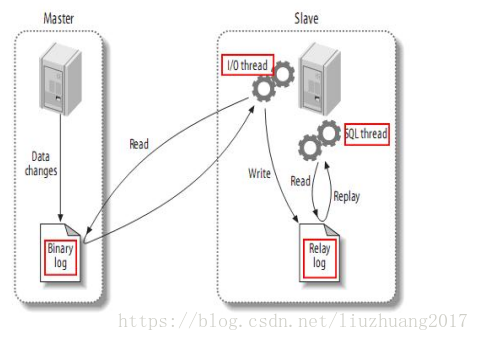
1.主服务器把数据更新记录到二进制日志中.
2.从服务器把主服务器的二进制日志拷贝到自己的中继日志(relay log)中.这个过程是通过IO Thread完成的。
3.从服务器重做中继日志中的时间,把更新应用到自己的数据库上,通过从库的SQL线程来达到数据的一致性。
工作原理的剖析:就是完全备份和二进制日志备份的还原。二进制日志的还原操作基本上是实时进行。但不是完全的实时,而是异步的实时。其中存在主从服务器之间的执行延时。因为sql线程为单线程,是一条一条地执行。如果主服务器的压力很大,则这个延时可能会更长。
主服务器的一个工作线程:
I/O线程
作用:接收到从库发来的请求后,负责给slave服务器发送二进制日志
从服务器的两个工作线程:
I/O线程
作用:负责读取主服务器的二进制日志,并将其保存到自己的中继日志文件中。
SQL线程
作用:来复制执行中继日志。
主从复制原理图:
3、在线搭建主从环境
(1)在主库初始化数据,通过mysqldump把数据导出来
/usr/local/mysql/bin/mysqldump --single-transaction -uroot -p123123 -A --master-data=2 > all.sql

vi all.sql 查看
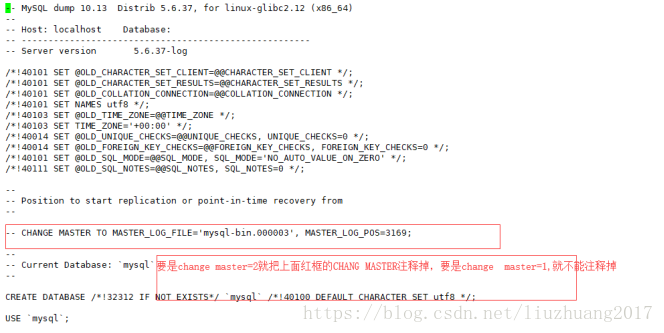
(2)把数据拷贝到从库
scp -r /data/mysql/all.sql root@bigdata14:/data/mysql/all.sql

(3)在从库执行恢复操作
mysql -uroot -p123123 < /data/mysql/all.sql

(4)在主库授权,指定从库
grant replication slave on *.* to 'repl'@'192.168.100.14' identified by '123456';
flush privileges;


(5)在从库搭建主从复制
change master to master_host='192.168.100.13',master_user='repl',
master_password='123456',master_log_file='mysql-bin.00001',master_log_pos=120;

(6)在从库开启主从开关
start slave;

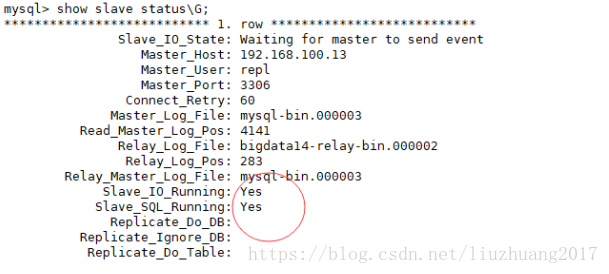
(7)查看主从的状态show slave status\G; 当IO线程和 SQL线程都为OK时,表明主从搭建理论上成功。
(8)验证主从搭建是否成功?在主库新插入一条数据,看是否能够同步到从库?
主库
select * from mytest.t1;
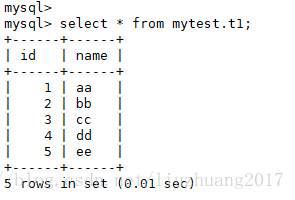
从库
select * from mytest.t1;
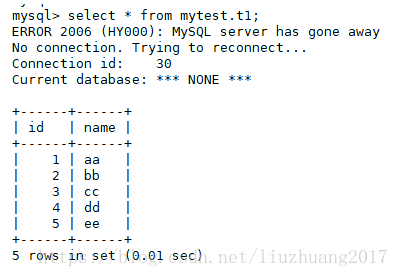
证明备份成功,导入数据成功
在主库新插入数字id=6,name=ff
insert into t1 (id,name) values(6,'ff');
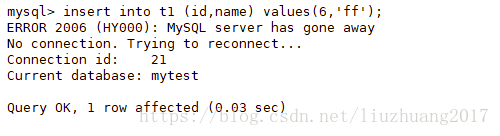
在从库查看t1表
select * from mytest.t1;
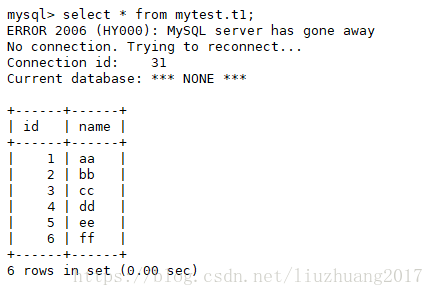
发现主库和从库数据一样,证明了主从搭建成功。
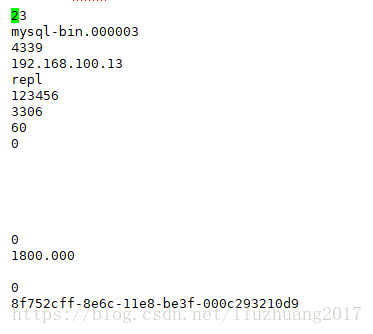
注意:在搭建完单向主从时,只有在从库中才有master.info的信息
vi /data/mysql/master.info
4、主从搭建的经典错误
主库:
CREATE TABLE `t`( `a` int(11) NOT NULL auto_increment, `b` varchar(20) DEFAULT NULL, PRIMARY KEY (`a`), KEY `b` (`b`) ) ENGINE=InnoDB auto_increment=1 DEFAULT CHARSET=utf8;

insert into t (b) values ('aa');
insert into t (b) values ('bb');
insert into t (b) values ('cc');
select * from t;
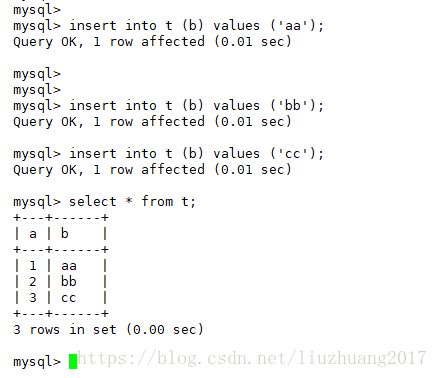
首先在从库中进行查看t表
发现主从数据一致
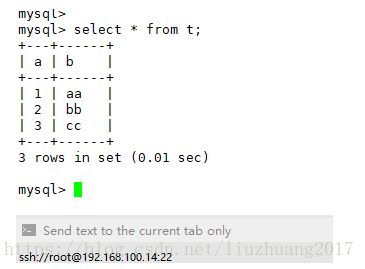
在从库进行写数据操作
insert into t (b) values (‘dd’);
select * from t;
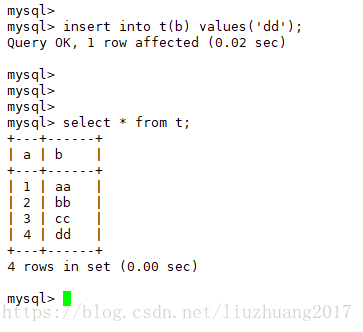
主库:
insert into t (b) values (‘dd’);
select * from t;
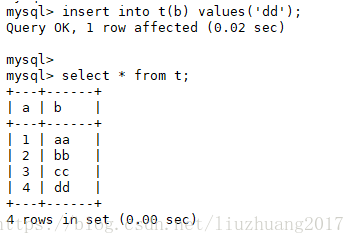
在主库插入刚才在从库插入的语句,因为这是单向同步的,只能从主库同步到从库。因此主库少了一条数据,所以需要在主库进行插入。
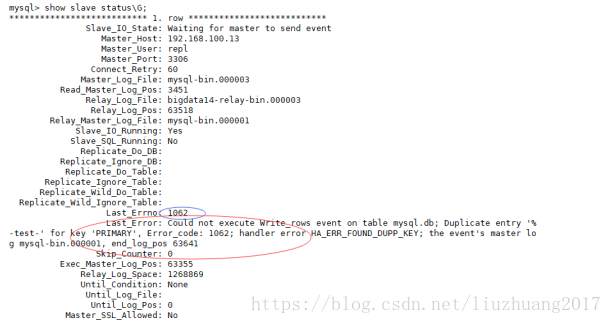
查看从库的状态show slave status\G;
(1)主从的第一个经典的错误1062 主键冲突
用percona-toolkit-2.2.20 来修复,这个工具被称为业界的瑞士军刀。
安装percona-toolkit-2.2.20工具之前,需要安装他的依赖
yum -y install perl-Digest-MD5
yum install -y perl-DBI
yum -y install perl-DBD-MySQL
cd /root/training/percona-toolkit-2.2.20/bin
./pt-slave-restart -uroot -p123123

它是实时监控的,下回还会报错。
然后查看从库的状态:show slave status\G; 主从的状态又OK了。
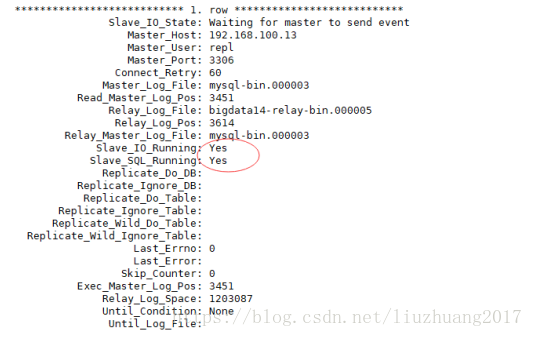
(2)主从第二个经典错误1032
在从库删一条数据,

在主库更新一条数据
在从库查询主从的状态:show slave status\G;
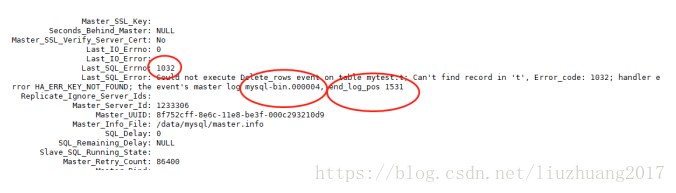
解决办法:
在主库中查看binlog日志mysql-bin.000004
/usr/local/mysql/bin/mysqlbinlog --no-defaults -v -v --base64-output=decode-
rows /data/mysql/mysql-bin.000004 > /data/mysql/1.log
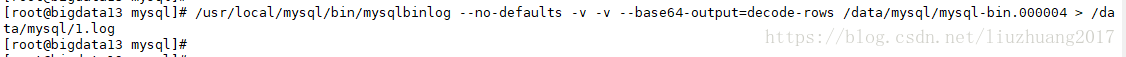
vi 1.log
从binlog日志中可以看出我们做了两个操作,所以在从库中插入与主库一致的数据的数据
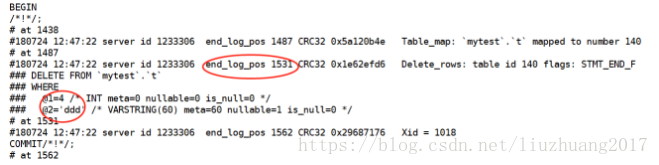
在从库:
insert into t(a,b) values (4,’ddd’);
再用pt工具集

查看主从的状态:
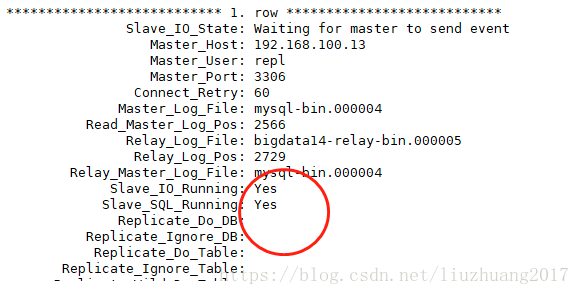
在主库继续更新操作
update t set b=’dddd’ where a=4;
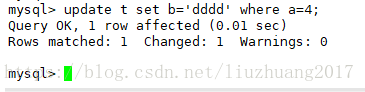
在从库查看更新的情况

发现数据可以同步过来了
(3)主从第三个经典错误1593
把从库的server_id修改成与主库的一样,在配置文件中进行修改,然后重新启动数据库。
查看主从的状态,show slave status\G;
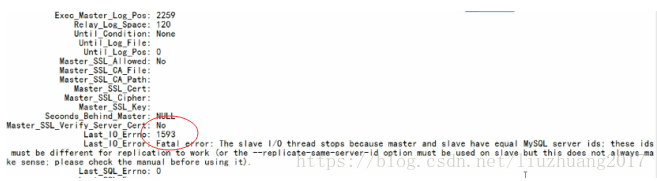
解决办法,在配置文件中把server_id修改为不一样的就行了。
(4)主从第四个经典错误1236
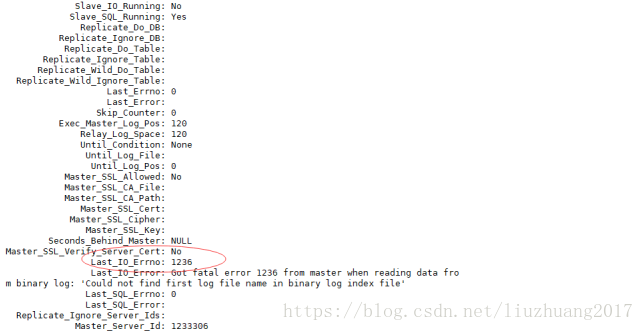
这个问题产生的原因为:从数据库读取的 mysqlbin 文件的pos 位置与主数据库不一致所产生的。
- 停止从数据库的同步
stop slave;
2.在主数据库上查看当前的日志 pos
show master status;

3.根据上述的位置,在从数据库上执行
change master to master_log_file='mysql-bin.000003',master_log_pos= 4141;
![]()
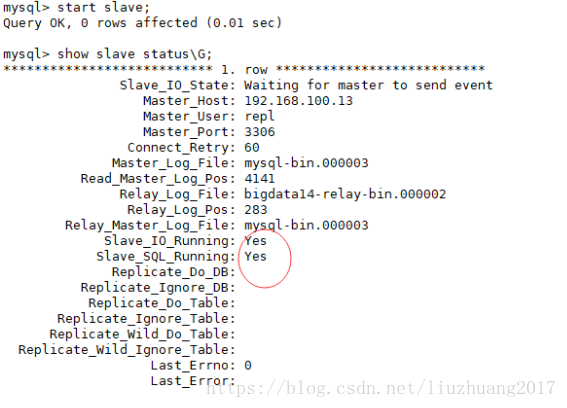
4.开启从库,并查看状态
start slave;
show slave status\G;

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









